人人都是 DBA(VIII)SQL Server 页存储结构
当在 SQL Server 数据库中创建一张表时,会在多张系统基础表中插入所创建表的信息,用于管理该表。通过目录视图 sys.tables, sys.columns, sys.indexes 可以查看新建的表的元数据信息。
下面使用创建 Customer 表的过程作为示例。

USE [TEST] GO DROP TABLE [dbo].[Customer] GO CREATE TABLE [dbo].[Customer]( [ID] [int] NOT NULL, [Name] [varchar](50) NOT NULL, [Address] [varchar](100) NULL, [Phone] [varchar](100) NULL ) GO
select * from sys.tables where [name] = 'Customer'; select * from sys.columns where object_id = (select object_id from sys.tables where [name] = 'Customer'); select * from sys.indexes where object_id = (select object_id from sys.tables where [name] = 'Customer');

如果一张表没有聚集索引(Clustered Index),则数据本身没有结构,这样的表称为堆(Heap)。sys.indexes 中堆的 index_id 为 0,可以看到 Customer 表没有建立任何索引,所以 index_id 为 0,并且 type_desc 为 HEAP。
堆中的数据没有任何结构,当有新的数据行插入时,SQL Server 会寻找空闲的可用空间直接插入。存储数据的数据页之间也没有连接关系,不会形成一个链表。

如果为表建立上非聚集索引(Non-Clustered Index),则 index_id 从 2 开始增长。1 的位置始终留给聚集索引(Clustered Index)。
CREATE NONCLUSTERED INDEX [IX_Customer_Name] ON [dbo].[Customer] ([Name]);

ALTER TABLE [dbo].[Customer] ADD CONSTRAINT [PK_Customer] PRIMARY KEY CLUSTERED ([ID]);

SQL Server 在构成 Primary Key 约束的列上创建一个唯一索引,如果不明确指定,则默认该索引类型是唯一聚集索引。建立 Primary Key 后,可以在 sys.key_constraints 视图中查看主键信息。
select * from sys.check_constraints select * from sys.default_constraints select * from sys.key_constraints select * from sys.foreign_keys

当为表建立聚集索引后,表内的数据会重构成树状结构,也就是使用 B 树形式进行存储。

SQL Server 数据库的每张表和索引都可以存储在多个分区上,sys.partitions 视图为堆或索引的每个分区包含一行数据。每个堆或索引都至少有一个分区,即使没有专门进行分区。
select * from sys.partitions where object_id = (select object_id from sys.tables where [name] = 'Customer');

SQL Server 用于描述某个分区上某张表或索引子集的术语是 hobt,代表 Heap Or B-Tree,即堆或 B 树,发音读作 "hobbit"。所以上图中可以看到存在一列为 hobt_id,使得 partition_id 和 hobt_id 形成 一对一的关系,实际上这两列总是具有相同的值。
分区上可以存储 3 种类型的数据页:
- 行内数据页(In-Row Data Pages)
- 行溢出页(Row-Overflow Data Pages)
- LOB 数据页(LOB Data Pages)

一个分区下的一种数据页类型的一组页面称为分配单元(Allocation Unit),可以使用 sys.allocation_units 视图来查看。
SELECT object_name(object_id) AS [name] ,partition_id ,partition_number AS pnum ,rows ,allocation_unit_id AS au_id ,type_desc AS page_type_desc ,total_pages AS pages FROM sys.partitions p JOIN sys.allocation_units a ON p.partition_id = a.container_id WHERE object_id = OBJECT_ID('dbo.Customer');

如果行的长度超过了最大值 8060 字节,那么行的数据会被存放到行溢出页中。如果行中存在 LOB 类型的字段,则会使用 LOB 数据页存储。
ALTER TABLE [dbo].[Customer] ADD [OrderDescription] varchar(8000); ALTER TABLE [dbo].[Customer] ADD [OrderDetails] text;

对表添加聚集索引不会修改 sys.allocation_units 中的行数,但会修改 partition_id,因为创建聚集索引会导致表在系统内重建。添加非聚集索引则会至少添加一行记录以跟踪该索引。
ALTER TABLE [dbo].[Customer] ADD CONSTRAINT [PK_Customer] PRIMARY KEY CLUSTERED ([ID]); CREATE NONCLUSTERED INDEX [IX_Customer_Name] ON [dbo].[Customer] ([Name]);
SELECT convert(CHAR(8), object_name(i.object_id)) AS table_name ,i.NAME AS index_name ,i.index_id ,i.type_desc AS index_type ,partition_id ,partition_number AS pnum ,rows ,allocation_unit_id AS au_id ,a.type_desc AS page_type_desc ,total_pages AS pages FROM sys.indexes i JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id JOIN sys.allocation_units a ON p.partition_id = a.container_id WHERE i.object_id = object_id('dbo.Customer');

可以通过 DMV 视图查询索引状况。
SELECT * FROM sys.dm_db_index_physical_stats(DB_ID('TEST'), OBJECT_ID(N'dbo.Customer'), NULL, NULL, 'DETAILED');

SQL Server 中的数据页具有 8KB(8192 Bytes)的固定长度,每个数据页由 3 部分组成:
- 页头(Page Header)
- 数据行(Data Rows)
- 行偏移数组(Row Offset Array)

页头(Page Header)占了 96 字节长度。向 Customer 表插入条数据看看。
INSERT INTO [dbo].[Customer] ( [ID] ,[Name] ,[Address] ,[Phone] ) VALUES ( 1 ,'Dennis Gao' ,'Beijing Haidian' ,'18866667777' ) GO
使用 sys.fn_dblog 查询事务日志,获取新插入的 Page 相关信息。
SELECT [Current LSN] ,[Operation] ,[Context] ,[Transaction ID] ,[Log Record Length] ,[Previous LSN] ,[AllocUnitId] ,[AllocUnitName] ,[Page ID] ,[Slot ID] ,[Xact ID] FROM sys.fn_dblog(NULL, NULL)
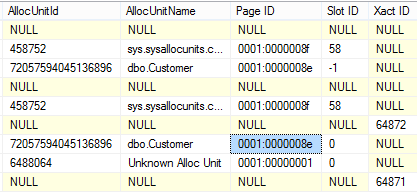
发现 LOP_INSERT_ROWS 操作对应的 Page ID 为 0001:0000008e,翻译成 10 进制为 1:142。也就是文件号为 1,页编号为 142。实际上,每个页都会通过一个 6 Bytes 的值来表示,其中包含 2 Bytes 的文件 ID 和 4 Bytes 的页编号。
由于我们只插入了 1 条数据,可以使用 sys.system_internals_allocation_units 目录视图来查看首页地址。以 sys.system_internals_ 开头的目录视图是还未公开的目录视图。sys.system_internals_allocation_units 比 sys.allocation_units 视图多 3 个字段:first_page, root_page, first_iam_page。
SELECT object_name(object_id) AS [name] ,rows ,type_desc AS page_type_desc ,total_pages AS pages ,first_page ,root_page ,first_iam_page FROM sys.partitions p JOIN sys.system_internals_allocation_units a ON p.partition_id = a.container_id WHERE object_id = object_id('dbo.Customer');

这里的 first_page = 0x8E0000000100 十六进制结果可以翻译为 00 01 共 2 字节的文件号,和 00 00 00 8E 共 4 字节的页编号。与上面的 0001:0000008e 正好匹配。
不过,这么计算基本上乐趣全无了,可以使用如下的 SQL 进行直接翻译。
DECLARE @page_num BINARY (6) = 0x8E0000000100; SELECT (convert(VARCHAR(2), ( convert(INT, substring(@page_num, 6, 1)) * power(2, 8)) + (convert(INT, substring(@page_num, 5, 1)))) + ':' + convert(VARCHAR(11), ( convert(INT, substring(@page_num, 4, 1)) * power(2, 24)) + (convert(INT, substring(@page_num, 3, 1)) * power(2, 16)) + (convert(INT, substring(@page_num, 2, 1)) * power(2, 8)) + (convert(INT, substring(@page_num, 1, 1)) ))) AS page_number;

另一种确认页编号的方式是使用 DBCC IND 命令,用于查找表中的所有的页。
DBCC IND([TEST], 'dbo.Customer', -1) GO

实际上,还有一种查询页编号的方式是使用内部函数 sys.fn_PhysLocFormatter,不过很遗憾,这个函数的返回结果存在问题,不准确。
SELECT %%physloc%%, sys.fn_PhysLocFormatter (%%physloc%%) AS RID, * FROM dbo.Customer;
DBCC TRACEON(3604, -1) GO DBCC PAGE([TEST], 1, 142, 1) GO
DBCC PAGE 的输出结果分成 4 个部分:BUFFER,PAGE HEADER,DATA,OFFSET TABLE。
- BUFFER 部分显示给定页面的缓冲区信息。
- PAGE HEADER 部分显示 Page 页头信息。
- DATA 部分显示 Page 中存放的记录信息。
- OFFSET TABLE 部分显示行偏移数组信息。
PAGE: (1:142) BUFFER: BUF @0x000000027D0048C0 bpage = 0x0000000272292000 bhash = 0x0000000000000000 bpageno = (1:142) bdbid = 7 breferences = 0 bcputicks = 0 bsampleCount = 0 bUse1 = 17332 bstat = 0x10b blog = 0x15acc bnext = 0x0000000000000000 PAGE HEADER: Page @0x0000000272292000 m_pageId = (1:142) m_headerVersion = 1 m_type = 1 m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x8000 m_objId (AllocUnitId.idObj) = 110 m_indexId (AllocUnitId.idInd) = 256 Metadata: AllocUnitId = 72057594045136896 Metadata: PartitionId = 72057594040287232 Metadata: IndexId = 0 Metadata: ObjectId = 1045578763 m_prevPage = (0:0) m_nextPage = (0:0) pminlen = 8 m_slotCnt = 1 m_freeCnt = 8039 m_freeData = 151 m_reservedCnt = 0 m_lsn = (34:369:91) m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 m_tornBits = 0 DB Frag ID = 1 Allocation Status GAM (1:2) = ALLOCATED SGAM (1:3) = ALLOCATED PFS (1:1) = 0x61 MIXED_EXT ALLOCATED 50_PCT_FULL DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED DATA: Slot 0, Offset 0x60, Length 55, DumpStyle BYTE Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS Record Size = 55 Memory Dump @0x000000000B7DA060 0000000000000000: 30000800 01000000 04000003 001d002c 00370044 0..............,.7.D 0000000000000014: 656e6e69 73204761 6f426569 6a696e67 20486169 ennis GaoBeijing Hai 0000000000000028: 6469616e 31383836 36363637 373737 dian18866667777 OFFSET TABLE: Row - Offset 0 (0x0) - 96 (0x60)
Metadata 为前缀的字段不是 Page Header 中的内容,它们是 DBCC PAGE 的一些查询结果。
- Metadata: AllocUnitId = 72057594045136896
- Metadata: PartitionId = 72057594040287232
- Metadata: IndexId = 0
- Metadata: ObjectId = 1045578763
这与使用目录视图查询的结果一致。
SELECT convert(CHAR(8), object_name(i.object_id)) AS table_name ,i.object_id ,i.index_id ,partition_id ,partition_number AS pnum ,rows ,allocation_unit_id AS au_id ,total_pages AS pages FROM sys.indexes i JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id JOIN sys.allocation_units a ON p.partition_id = a.container_id WHERE i.object_id = object_id('dbo.Customer');

我们发现 m_objId 和 m_indexId 两个字段的值没有在之前的查询中出现过:
- m_objId (AllocUnitId.idObj) = 110
- m_indexId (AllocUnitId.idInd) = 256
实际上这两个字段的值是计算出来的结果,计算规则:
- 将 m_indexId 向左移 48 位,记录为值 A;
- 将 m_objId 向左移 16 位,记录为值 B;
- AllocUnitId = A|B;(逻辑或)
例如,使用上面的页中的值,
- A = 256 << 48 = 72057594037927936
- B = 110 << 16 = 7208960
- A|B = 72057594045136896
可以使用如下 SQL 进行计算。
SELECT 256 * CONVERT(BIGINT, POWER(2.0, 48)); SELECT 110 * CONVERT(BIGINT, POWER(2.0, 16)); SELECT 256 * CONVERT(BIGINT, POWER(2.0, 48)) | 110 * CONVERT(BIGINT, POWER(2.0, 16));

那么,反向根据 AllocUnitId 求 m_objId 和 m_indexId 的方式和上面的规则正好相反:
- m_indexId = AllocUnitId >> 48
- m_objId = (AllocUnitId - (m_indexId << 48)) >> 16
可以使用下面的 SQL 语句进行计算。
DECLARE @alloc BIGINT = 72057594045136896; DECLARE @index BIGINT; SELECT @index = CONVERT(BIGINT, CONVERT(FLOAT, @alloc) * (1 / POWER(2.0, 48)) ); SELECT CONVERT(BIGINT, CONVERT(FLOAT, @alloc - (@index * CONVERT(BIGINT, POWER(2.0, 48)))) * (1 / POWER(2.0, 16)) ) AS [m_objId] ,@index AS [m_indexId]; GO

DBCC PAGE 输出的 OFFSET TABLE 部分是一块 2 字节的条目块,其中每个条目指向着行数据页的起始位置。也就是,每一行数据都有一个 2 字节的条目在行偏移数组中。行偏移数组指向着页内数据的逻辑顺序。例如,对于一个聚集索引的表,SQL Server 会按照聚集索引的键的顺序对数据进行存储,这并不是说物理顺序就是按照键的顺序排列,而是在行偏移数组中的 slot 0 存放索引的第 1 个数据引用,slot 1 存放第 2 个数据引用,以此类推。这样,物理上数据就可以存放在任意位置了。
对于数据行存储的结构,可以用下图所示,包括存储固定长度字段数据和变长字段数据。

可以与 DBCC PAGE 输出的 DATA 数据段落进行数据对比分析,具体的内容较为复杂,这里就不详细展开了。
Slot 0, Offset 0x60, Length 55, DumpStyle BYTE Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS Record Size = 55 Memory Dump @0x000000000B1DA060 0000000000000000: 30000800 01000000 04000003 001d002c 00370044 0..............,.7.D 0000000000000014: 656e6e69 73204761 6f426569 6a696e67 20486169 ennis GaoBeijing Hai 0000000000000028: 6469616e 31383836 36363637 373737 dian18866667777
由于每页有固定的 8K 字节的大小。每一个数据页中都包含多条数据记录,一页中能存储多少条记录则直接依赖于记录本身的大小。由于从磁盘读取数据时也是从磁道和柱面一次读取多个数据页,让后将数据页存放到内存缓冲区,所以如果每数据页可以存放更多的数据记录,则可以直接减少物理读的次数,而通过逻辑读来提高性能。
《人人都是 DBA》系列文章索引:
本系列文章《人人都是 DBA》由 Dennis Gao 发表自博客园个人技术博客,未经作者本人同意禁止任何形式的转载,任何自动或人为的爬虫转载或抄袭行为均为耍流氓。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
2013-12-09 Visual Studio 2013 新功能 Memory Dump 分析器