

最近做图的题比较多,除了克鲁斯卡尔和floyd,像广搜,普里姆,Bellman-Ford,迪杰斯特拉,SPFA,拓扑排序等等,都用到图的邻接表形式。
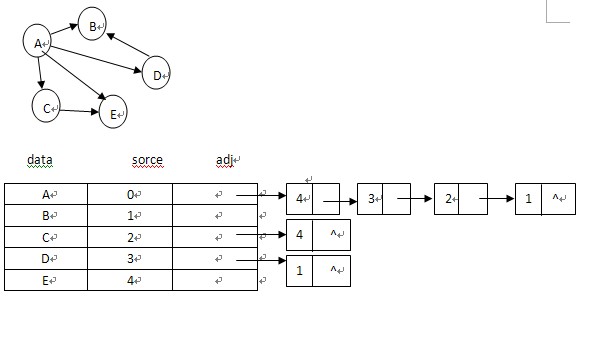
数据结构书上表示邻接表比较复杂,一般形式如下:
typedef struct Node
{
int dest; //邻接边的弧头结点序号
int weight; //权值信息
struct Node *next; //指向下一条邻接边
}Edge; //单链表结点的结构体
typedef struct
{
DataType data; //结点的一些数据,比如名字
int sorce; //邻接边的弧尾结点序号
Edge *adj; //邻接边头指针
}AdjHeight; //数组的数据元素类型的结构体
typedef struct
{
AdjHeight a[MaxVertices]; //邻接表数组
int numOfVerts; //结点个数
int numOfEdges; //边个数
}AdjGraph; //邻接表结构体
{
int dest; //邻接边的弧头结点序号
int weight; //权值信息
struct Node *next; //指向下一条邻接边
}Edge; //单链表结点的结构体
typedef struct
{
DataType data; //结点的一些数据,比如名字
int sorce; //邻接边的弧尾结点序号
Edge *adj; //邻接边头指针
}AdjHeight; //数组的数据元素类型的结构体
typedef struct
{
AdjHeight a[MaxVertices]; //邻接表数组
int numOfVerts; //结点个数
int numOfEdges; //边个数
}AdjGraph; //邻接表结构体
其实有种简洁且高效的表示形式:
typedef struct
{
int to;
int w;
int next;
}Edge;
Edge e[MAX];
int pre[MAX];
//初始化
memset(pre,-1,sizeof(pre));
//输入
scanf("%d %d %d",&from,&to,&w1);
e[i].to = to; e[i].w = w1; e[i].next = pre[from]; pre[from] = i;
i++;
{
int to;
int w;
int next;
}Edge;
Edge e[MAX];
int pre[MAX];
//初始化
memset(pre,-1,sizeof(pre));
//输入
scanf("%d %d %d",&from,&to,&w1);
e[i].to = to; e[i].w = w1; e[i].next = pre[from]; pre[from] = i;
i++;
上面这段代码中,边的结构体Edge由三个元素组成:弧头结点序号,边权值,下一条边的序号。e[i]指的是第i条边。pre[i]记录的是从当前输入的情况来看,序号为i的弧尾结点发出的第一条边的序号是pre[i]。
这样,在操作某个结点发出的边时,可以像这么做:
/*now为弧尾结点序号,i为now所发出的边序号,adj为弧头结点序号,w为now-->adj这条边的权值*/
for(i = pre[now]; i != -1; i = edge[i].next)
{
int adj = edge[i].to;
int w = edge[i].w;
//do something...
}
for(i = pre[now]; i != -1; i = edge[i].next)
{
int adj = edge[i].to;
int w = edge[i].w;
//do something...
}
其实,对于哈希表这类的存储结构(链表法解决冲突),与图的邻接表类似,也可以用类似的表示方法:
typedef struct
{
char e[11]; //value
char f[11]; //key
int next; //下一个结果(hash冲突)
}Entry;
Entry entry[M];
int hashIndex[M]; //哈希值为M的结果集的第一个在entry中的序号。
//输入:对key进行hash,
sscanf(str,"%s %s",entry[i].e,entry[i].f);
int hash = ELFHash(entry[i].f);
entry[i].next = hashIndex[hash];
hashIndex[hash] = i;
i++;
//使用:
for(int k = hashIndex[hash]; k; k = entry[k].next)
{
//do something..
}
{
char e[11]; //value
char f[11]; //key
int next; //下一个结果(hash冲突)
}Entry;
Entry entry[M];
int hashIndex[M]; //哈希值为M的结果集的第一个在entry中的序号。
//输入:对key进行hash,
sscanf(str,"%s %s",entry[i].e,entry[i].f);
int hash = ELFHash(entry[i].f);
entry[i].next = hashIndex[hash];
hashIndex[hash] = i;
i++;
//使用:
for(int k = hashIndex[hash]; k; k = entry[k].next)
{
//do something..
}

