

软件工程第1次作业
要求0
作业连接:【https://edu.cnblogs.com/campus/nenu/2016CS/homework/2110】
要求1
git仓库地址:【https://git.coding.net/Soloversion/wf.git】
要求2
1.PSP阶段表格
|
SP2.1 |
任务内容 |
计划共完成需要的时间(min) |
实际完成需要的时间(min) |
|
Planning |
计划 |
2000 |
2240 |
|
Estimate |
估计这个任务需要多少时间,并规划大致工作步骤 |
2000 |
2240 |
|
Development |
开发 |
1580 |
2330 |
|
Analysis |
需求分析 (包括学习新技术) |
120 |
150 |
|
Design Spec |
生成设计文档 |
90 |
120 |
|
Design Review |
设计复审 (和同事审核设计文档) |
0 |
0 |
|
Coding Standard |
代码规范 (为目前的开发制定合适的规范) |
60 |
100 |
|
Design |
具体设计 |
240 |
500 |
|
Coding |
具体编码 |
920 |
1220 |
|
Code Review |
代码复审 |
60 |
90 |
|
Test |
测试(自我测试,修改代码,提交修改) |
90 |
150 |
|
Reporting |
报告 |
410 |
500 |
|
Test Report |
测试报告 |
200 |
230 |
|
Size Measurement |
计算工作量 |
90 |
120 |
|
Postmortem & Process Improvement Plan |
事后总结, 提出过程改进计划 |
120 |
150 |
|
功能模块 |
具体阶段 |
预计时间(min) |
实际时间(min) |
|
功能1 |
具体设计 具体编码 测试完善 |
20 130 20 |
30 200 25 |
|
功能2 |
具体设计 具体编码 测试完善 |
30 140 20 |
15 150 25 |
|
功能3 |
具体设计 具体编码 测试完善 |
40 210 30
|
未完成 未完成 未完成 |
2.分析预估耗时和实际耗时的差距原因:
•自身能力薄弱。由于自己的编程能力比较弱,所以在拿到作业之后花了很长时间去尽力实现其中的部分功能,这个过程中还包含着我对于自己之前不熟悉的语言的重新学习;
•分析不到位。可能是基础比较差和缺少经验的原因,我虽然感觉自己学过这种频率统计,但是实际仔细分析的时候才发现有很大的不同,所以出于一种不断发现问题的循环中;
•细节处理不好。对于代码的规范和整体框架,我做的并不好,脑子中没有一个outline,这是我欠缺的一种能力。
要求3
1.解题思路
先将题目要求实现的功能大致分为以下三大块:(1)读取txt文本(2)统计其中单词个数(3)将单词(按照某种顺序)输出。
对功能一进行分析:要求统计文本中不重复的单词个数,同时将大写全部转化为小写输出。
多功能而进行分析:在功能一的基础上增加了在路径下寻找指定文本,在调用功能一即可。
然而,理想很丰满,现实很骨感。分析起来好像很简单,实际上真正做起来自己完成的部分少之又少,还是在借鉴了其他博主思路的情况下。
2.部分代码展示
1)首先利用函数判断该单词是否符合规定的单词格式,从而进行第一道筛选
bool islegal( char a[] ) /* 判断是否是一个合法单词 */ { int i = 0; for ( i = 0; a[i] != '\0'; i++ ) if ( (a[i] >= 'a' && a[i] <= 'z') || (a[i] >= '0' && a[i] <= '9') ) return(true); else return(false); }
2)将找到的单词的字母进行大小写的转换,再将转换后所得结果result存入数组中
int j = 0; /* 大写转为小写 */ while ( result[j] != '/0' && result[j + 1] != '/0' ) { if ( result[j] >= 'A' && result[j] <= 'Z' ) { result[j] = result[j] +32;/*单个字母的大小写转换*/ j++; } } cout << result; char *sep = " ";
3)扫描要求路径下的所有txt文件,同时选定在字典顺序中最靠前的文件,从而实现功能2.
这一部分代码是借鉴于其他博主的,引用自:https://www.cnblogs.com/tgyf/p/3839894.html
/*-------获取特定格式的文件名-------*/ void GetAllFormatFiles( string path, vector<string>& files,string format) { long hFile = 0;//文件句柄 struct _finddata_t fileinfo; //文件信息 string p; if((hFile = _findfirst(p.assign(path).append("\\*" + format).c_str(),&fileinfo)) != -1) { do { if((fileinfo.attrib & _A_SUBDIR)) { if(strcmp(fileinfo.name,".") != 0 && strcmp(fileinfo.name,"..") != 0) { GetAllFormatFiles( p.assign(path).append("\\").append(fileinfo.name), files,format); } } else { files.push_back(p.assign(fileinfo.name)); } }while(_findnext(hFile, &fileinfo) == 0); _findclose(hFile); } }
4)处理输入的文件名,即只有当控制台输入“”wf -c 文件名”时,才能够对相应的.txt文件进行读取
此处对字符串的处理我引用自:http://blog.sina.com.cn/s/blog_5cef35c50100dqy5.html
bool filename()/*处理输入的文件名*/ { bool exist=false; string::size_type index1 = inputstr.find("-c");/*确定输入的为-c*/ if(index1!=string::npos) { exist=true; index1=index1+3; while(inputstr[index1]!=' '&&inputstr[index1]!='\n') { file_name=file_name+inputstr[index1]; index1++; } } return exist; }
5)对单词的出现频率进行排序,采用的算法是冒泡排序算法,此处用到数据结构当中的相关排序知识
for(k=1;k<=j-1;k++)/*利用冒泡排序算法*/ for(i=k+1;i<=j;i++) { if(number[k]<number[i]) { int temp=number[k]; number[k]=number[i]; number[i]=temp; r[0]=(char *)malloc(sizeof(w[k]));/*将对应的单词也进行交换*/ r[0]=w[k]; w[k]=(char *)malloc(sizeof(w[i])); w[k]=w[i]; w[i]=(char *)malloc(sizeof(r[0])); w[i]=r[0]; } return 0; }
要求4
由于我自己没有将各个功能全部完成,所以最后的测试部分借用的是别人的代码
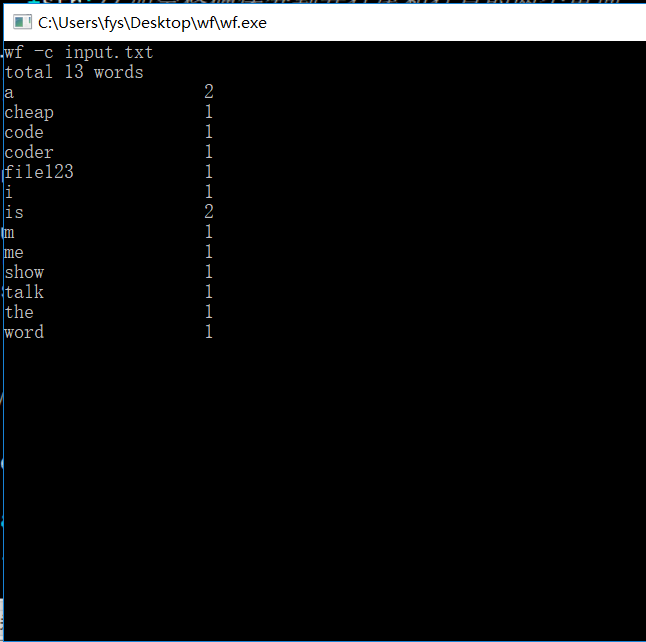
1)老师样例测试
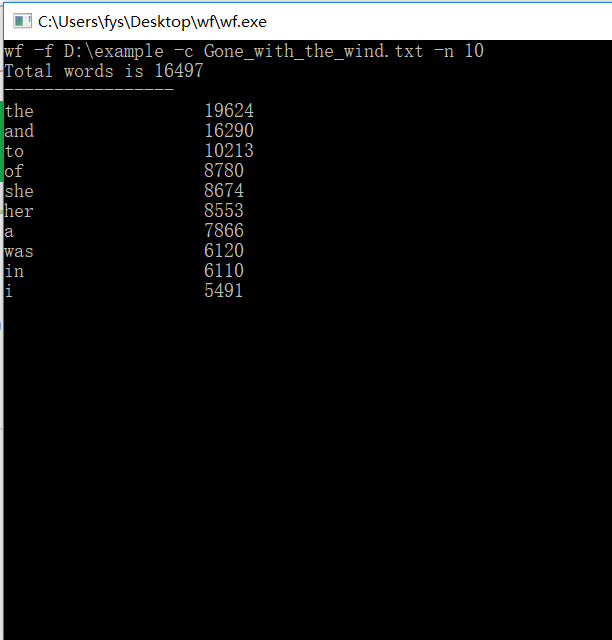
2)外国名著《飘》
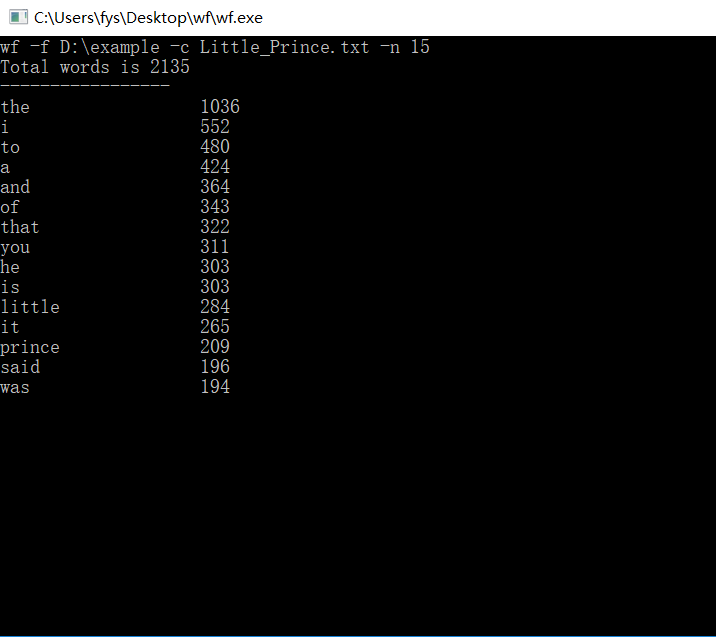
3)外国短篇小说《小王子》
总结
其实说句实话,在拿到这个作业之后,我感到无从下手,只能不断的查资料,从别的博主那里获得一些相关知识,不仅耗费了大量的时间也耗费了大量的精力,重点是最后还没有完全写出来,这也让我感到迷茫和伤心,我越来越觉得自己可能不适合干这行,越来越对自己产生怀疑。再看看《构建之法》中作者用诙谐的语言给我们讲着软件工程这门学科,我更加觉得自己的渺小和无知,因为只有真正懂得的人才能用通俗的语言讲给其他人听,而我没有也做不到。
