关于NumPy的一些基础知识
关于NumPy的一些基础知识,供有一定NumPy基础的人作复习用
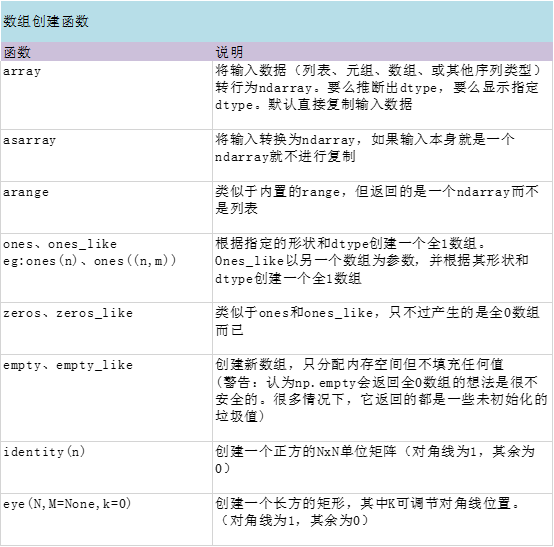
创建ndarray
每个数组都有一个shape(一个表示各维度大小的元组)和一个dtype(一个用于说明数组数据类型的对象),还有一个ndim(表示数组有几个维度)



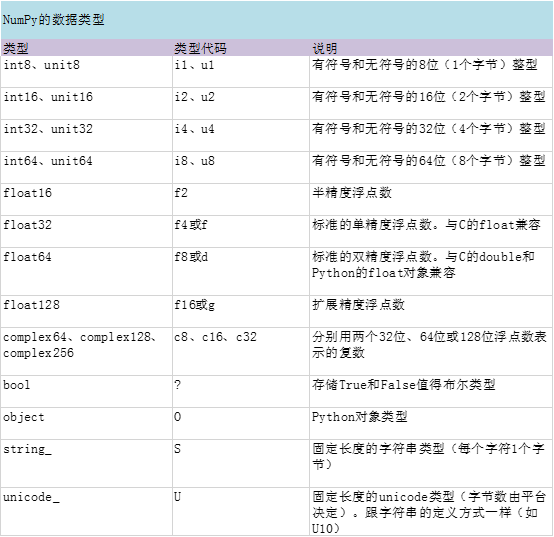
ndarray的数据类型
可以通过ndarray的astype方法转换其dtype(不会改变原对象):



警告:浮点数(比如float64和float32)只能表示近似的分数值。在复杂计算中,由于可能会积累一些浮点错误,因此比较操作只能在一定小数位以内有效
数组和标量之间的运算
大小相等的数组之间的任何算术运算都会将运算应用到元素级:



数组与标量的算术运算也会将那个标量值传播到各个元素:


索引和切片
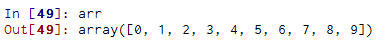



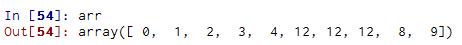
跟列表最重要的区别在于,数组切片是原始数组的视图。这意味着数据不会被复制,视图上的任何修改都会直接反映到源数组上。
如果你想要得到的是ndarray切片的一份副本而非视图,就需要显式地进行复制操作,例如arr[5:8].copy()
对元素访问

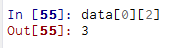
 两者等价
两者等价
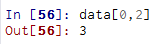
标量值和数组都可以被赋值给data[0]:

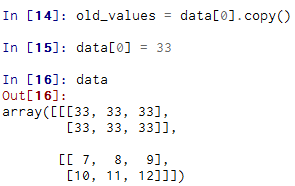

切片索引
高纬度数组,可以在一个或多个轴上进行切片,也可以跟整数索引混合使用。


可以看出,它是沿着第0轴(既第一个轴)切片的。也就是说,切片是沿着一个轴向选取元素的。你可以一次传入多个切片,就像传入多个索引那样:

像这样进行切片时,只能得到相同维数的数组视图。通过将整数索引和切片混合,可以得到低纬度的切片:


只有冒号表示选取整个轴,因此你可以像下面这样只对高纬度进行切片:

布尔型索引

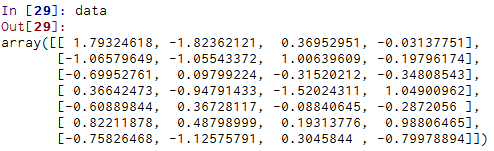


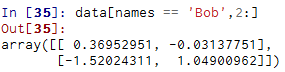
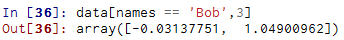
要选择Bob以外的值可以有多种方法:




选取这三个名字中的两个需要组合应用多个布尔条件,使用&(和)、|(或)之类的布尔算术运算符即可:

通过布尔型索引选取数组中的数据,将总是创建数据的副本,即使返回一模一样的数组也是如此。
警告:Python关键字and和or在布尔型数组中无效
通过布尔型数组设置值是一种经常用到的手段。为了将data中所有的负值都设置为0,我们只需:
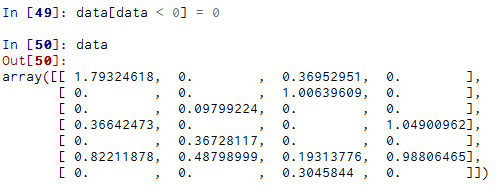
通过一维布尔数组设置整行或整列的值也很简单:

花式索引


为了以特定顺序选取行子集,只需传入一个用于指定顺序的整数列表或ndarray即可:


当传入两个列表时:

得到的结果可能和我们想的不一样。最终选出的是元素(1,0)、(5,3)、(7,1)、(2,2)。

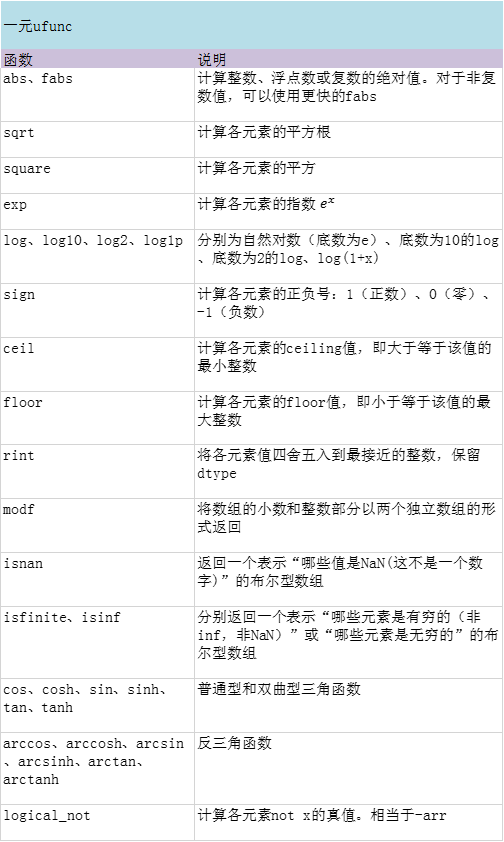
通用函数:快速的元素级数组函数
通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数。你可以将其看做简单函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。

利用数组进行数据处理
NumPy数组使你可以将许多种数据处理任务表述为简洁的数组表达式(否则需要编写循环)。用数组表达式代替循环的做法,通常被称为矢量化。一般来说,矢量化数组运算要比等价的纯Python方式快上一两个数量级(甚至更多),尤其是各种数值计算。




将条件逻辑表述为数组运算


数学和统计方法
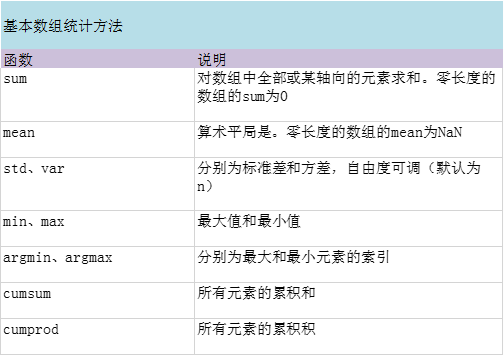
注意axis参数,可设置是对行还是列进行统计。如果不设置axis参数默认为对整个数组进行统计,而不是针对行或者列。
用于布尔型数组的方法
在上面这些方法中,布尔值会被强制转换为1(True)和0(False)。因此,sum经常被用来对布尔型数组中的True值计数:

另外还有两个方法any和all,它们对布尔型数组非常有用。any用于测试数组中是否存在一个或多个True,而all则检查数组中所有值是否都是True

这两个方法也能用于非布尔型数组,所有非0元素将会被当做True
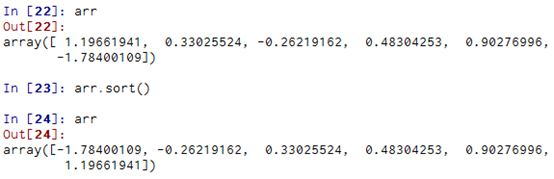
排序
跟Python内置的列表类型一样,NumPy数组也可以通过sort方法就地排序:
多维数组可以在任何一个轴向上进行排序,只需将轴编号传给sort即可:
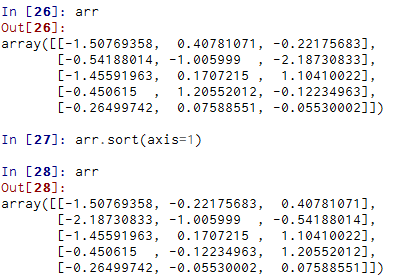
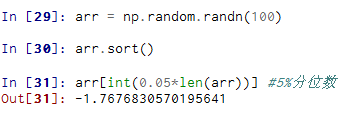
顶级方法np.sort返回的是数组的已排序副本,而就地排序则会修改数组本身。计算数组分位数最简单的办法是对其进行排序,然后选取特定位置的值:
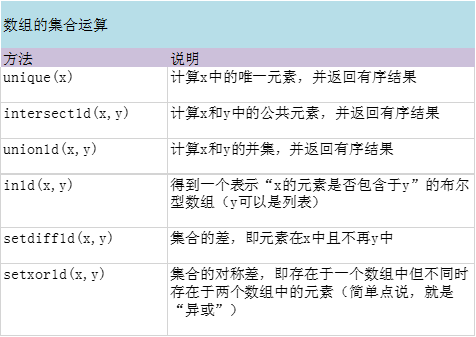
唯一化以及其他的集合逻辑
用于数组的文件输入输出
将数组以二进制格式保存到磁盘
np.save和np.load是读写磁盘数组数据的两个主要函数。默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为.npy的文件中。

如果文件路径末尾没有扩展名.npy,则该扩展名会被自动加上。然后就可以通过np.load读取磁盘上的数组:

通过np.savez可以将多个数组保存到一个压缩文件中,将数组以关键字参数的形式传入即可:

加载.npz文件时,会得到一个类似字典的对象:

存取文本文件
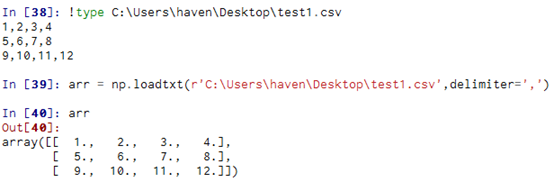
我们可以用np.loadtxt或更为专门话的np.genfromtxt将数据加载到普通的NumPy数组中。
这些函数都有许多选项可供使用:指定各种分隔符、针对特定列的转换器函数、需要跳过的行数等。以一个简单的逗号分隔文件为例(CSV):
np.savetxt执行的是相反的操作:将数组写到以某种分隔符隔开的文本文件中。genfromtxt跟loadtxt差不多,只不过它面向的是结构化数组和缺失数据处理。
线性代数
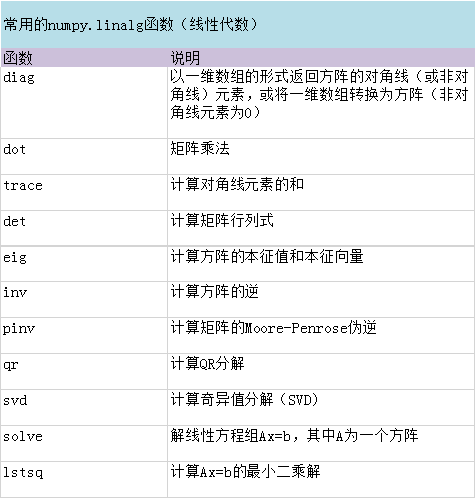
警告:有些函数并不属于numpy.linalg里,而是直接数据numpy里,如dot
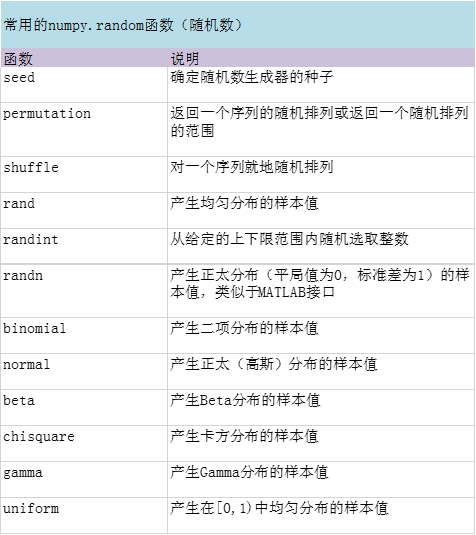
随机数生成