
Java解析OFFICE(word,excel,powerpoint)以及PDF的实现方案及开发中的点滴分享
Java解析OFFICE(word,excel,powerpoint)以及PDF的实现方案及开发中的点滴分享
在此,先分享下写此文前的经历与感受,我所有的感觉浓缩到一个字,那就是:"坑",如果是两个字那就是"巨坑"=>因为这个需求一开始并不是这样子的,且听我漫漫道来:
一开始客户与我们商量的是将office和PDF上传,将此类文件解析成html格式,在APP端调用内置server直接以html"播放"
经历一个月~,两个月~,三个月~~~
到需求开发阶段,发现这是个坑。。。:按照需规的意思这个整体是当做一个功能来做的,技术难度也就算了,而且按照估算的工时也很难做成需规所需要的样子(缺陷太多!)
然后一周~,一周~,又一周~~~
各种方案下来将需求做成能用的样子,然后需求确认时客户说:“我们没有要求你们能解析这些文档,我们只要求你们当做一个源文件上传,在APP端点击直接能选择调用第三方应用打开就行了,而且一开始我们的需求就是这样的。”
/**听完,顿时泪流满面(ಥ _ ಥ),如果业务一开始就确认这样做,何至于浪费如此多的时间,花费如此多的精力绕老大一圈。。。*/
需求绕了一圈又绕回来了,作为经历过的人,现在总结下这需求里面无尽的坑:
A>开源社区有很多Demo,这些Demo有很多缺陷,比如office里面的艺术字、图片、公式、颜色样式、视频和音频不能解析
B>能解析的对象,解析出来的效果不是很好,比如word和ppt自身的排版乱了,excel单元格里面的自定义格式全变成数字了~等等
C>开源社区的资料并不是很全,导致的结果是不同的文档类型需要用不同的解析方式去解析,比如word用docx4j解析、excel用poi解析带来的代码量巨大
D>由于代码自身的解析效果不是很好,更改后的方案需要在上传之前将源文件处理成其他的形式,如pdf需要切成图片,ppt需要转换成视频或是图片,这样一来需求实现的方式就变成半自动了╥﹏╥...
E>word用docx4j解析一个很大的问题是解析的效率太低了,5MB以上的文件或者内容比较复杂的word文档解析十分耗时,解析效率太低,再一就是poi解析数据量比较大的Exel(比如>1000行)容易造成内存溢出,不好控制
F>工时太短,只有15天。。。,加班加点(⊙︿⊙) ,包工头,加工资!!!ε=怒ε=怒ε=怒ε=怒ε=( o`ω′)ノ
以上吐槽完了,该展示下最终成果了~
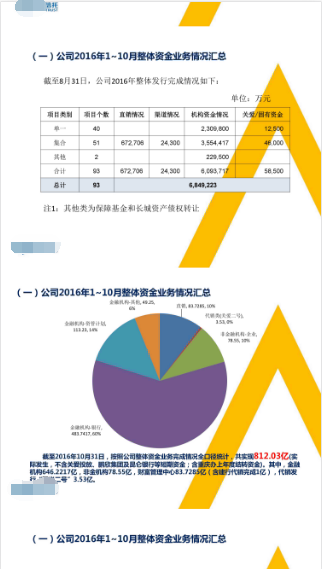

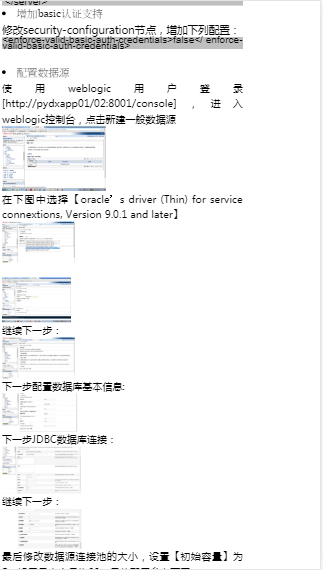
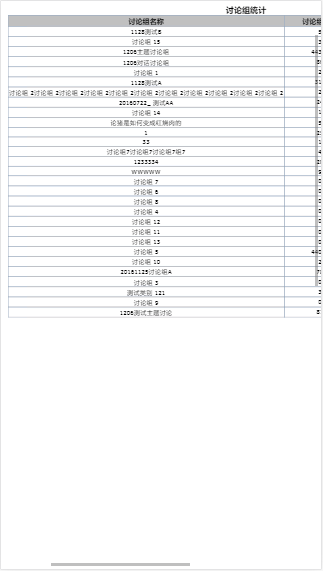
上4图从左至右依次是pdf、ppt、word、excel的解析html的效果,由于涉及开发协议上图1和图2部分地方有涂抹,且以上只是浏览器模拟手机显示,遂显示效果较为粗糙,在此十分抱歉~
下面介绍一下我的最终实现思路:
A>Word文档分两种格式(03版)doc和(07版)docx,由于doc属于即将淘汰的格式同时为方便使用docx4j一步到位的实现方式,故不考虑doc格式文档
B>同Word一样,excel也不考虑旧版格式的转换,方案是选用第三方Demo实现,涉及到具体的技术就是 poi.hssf
C>PowerPoint(ppt)由于内置对象比较多,为保证客户的使用体验,我的方案是将ppt直接导出成mp4或图片(需打zip包)上传,再用代码包装成html
D>对于pdf,同样没有很好的Demo实现成html,遂同ppt一样通过软件转换成图片的形式打包上传,再用代码包装成html
先展示下word解析的相关代码:
(代码片段一)
1 public static void Word2Html() throws FileNotFoundException, Docx4JException{
2 //需在log4j内配置docx4j的级别
3 WordprocessingMLPackage wmp = WordprocessingMLPackage.load(new File("C:\\Users\\funnyZpC\\Desktop\\Test\\word.docx"));
4 Docx4J.toHTML(wmp, "C:\\Users\\funnyZpC\\Desktop\\result\\wordIMG", "wordIMG", new FileOutputStream(new File("C:\\Users\\funnyZpC\\Desktop\\result\\word.html")));
5 }
(代码片段二)
1 public ProcessFileInfo processDOCX(File file,String uploadPath)throws Exception{
2 String fileName=file.getName().substring(0,file.getName().lastIndexOf("."));//获取文件名称
3 WordprocessingMLPackage wmp = WordprocessingMLPackage.load(file);//加载源文件
4 String basePath=String.format("%s%s%s", uploadPath,File.separator,fileName);//基址
5 FileUtils.forceMkdir(new File(basePath));//创建文件夹
6 String zipFilePath=String.format("%s%s%s.%s", uploadPath,File.separator,fileName,"ZIP");//最终生成文件的路径
7 Docx4J.toHTML(wmp, String.format("%s%s%s", basePath,File.separator,fileName),fileName,new FileOutputStream(new File(String.format("%s%s%s", basePath,File.separator,"index.html"))));//解析
8 scormService.zip(basePath, zipFilePath);//压缩包
9 FileUtils.forceDelete(new File(basePath));//删除临时文件夹
10 file.delete();//解析完成,删除原docx文件
11 return new ProcessFileInfo(true,new File(zipFilePath).getName(),zipFilePath);//返回目标文件相关信息
12 }
解析word(docx)文档所需要的代码简单到只需要两行代码(代码片段一3、4两行),以上(代码片段二)是实际开发的代码,建议对比片段一看,同时由于项目可能会部署在linux系统下,建议使用File.separator来代替"/"或者"\"路径分隔符;同时,需要解释的是toHtml方法的四个参数==>
Docx4j.toHtml(加载源docx文件的WordprocessingMLPackage实例化对象,存放解析结果(html和图片)的基目录,存放图片的文件夹名称(在基目录下),输出主html的输出流对象);
下图是输出的结果的目录:
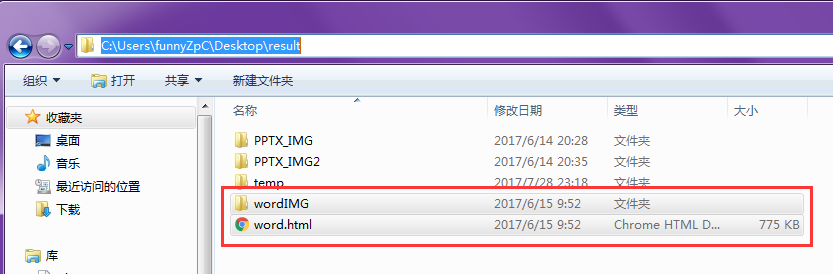
由于docx4j内部的log较多,默认Demo测试的时候输出文件会有如下提示:

这句话的大意是:如需隐藏此消息,请设置docx4j的debug的级别。解决的方式是在实际项目的log4j.properties中添加docx4j的消息级别为ERROR,如:

如果使用maven管理项目,直接在pom.xml里面添加docx4j的dependency,如果需手动配置docx4j及其依赖包,一定要注意依赖包与当前docx4j的版本对应性(推荐3.3.5的docx4j,解析效果会好一些!)否则各种毛病啊~,下图是maven仓库的一些说明,如需手动配置依赖一定要点进去看下:
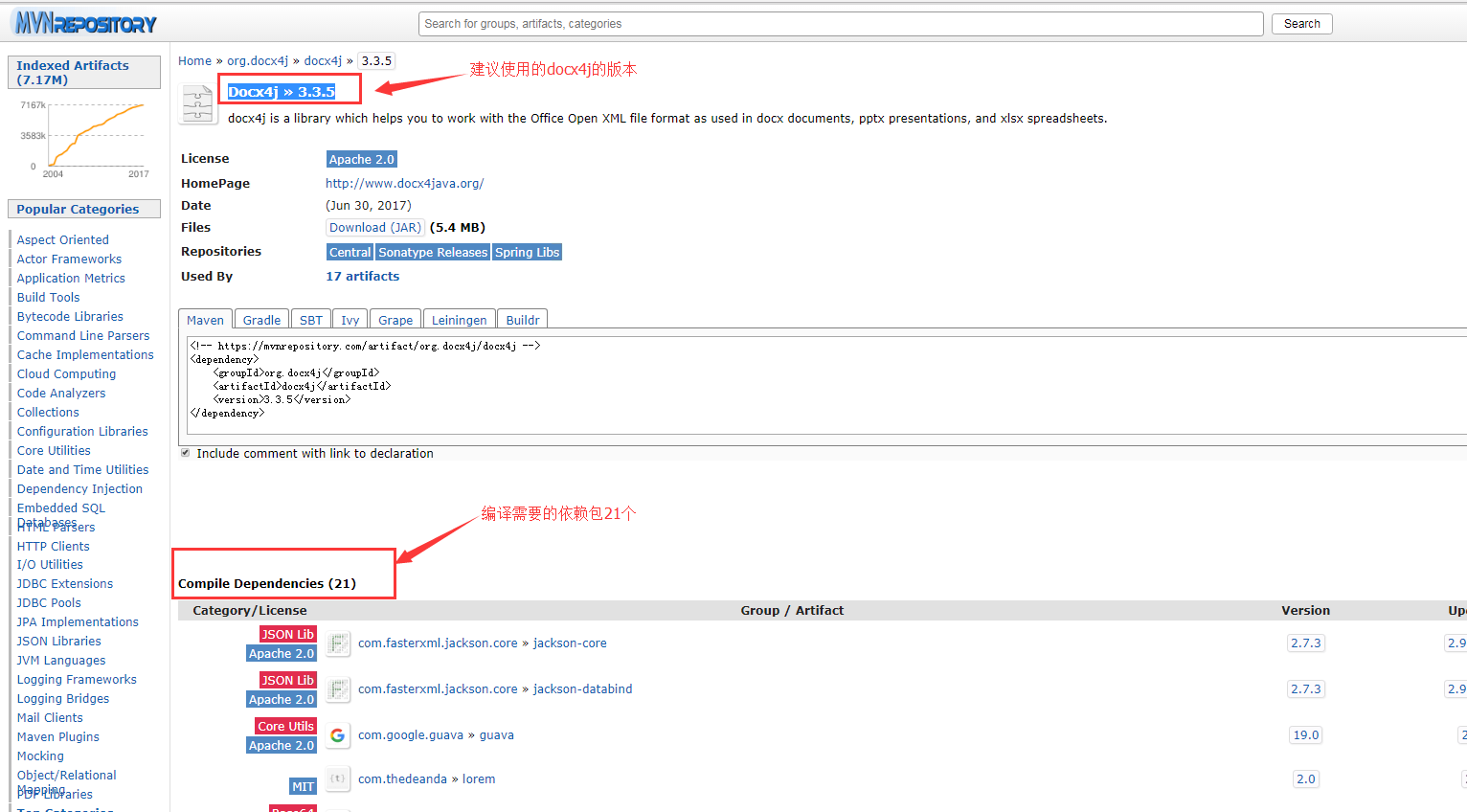
下面的代码是Excel解析word的部分代码片段(代码不全,如有需要请邮件私我):
(代码片段一)


1 /**
2 *
3 * @param file 源文件:c://xx//xx.xlsx
4 * @param uploadPath 基目录地址
5 * @return
6 * @throws Exception
7 */
8 public ProcessFileInfo processXLSX(File file,String uploadPath)throws Exception {
9 List<String> sheets=Excel2HtmlUtils.readExcelToHtml(file.getPath());
10 FileUtils.forceMkdir(new File(uploadPath));//创建文件夹
11 String code=file.getName().substring(0,file.getName().lastIndexOf("."));//文件名称
12 String basePath=String.format("%s%s%s", uploadPath,File.separator,code);
13 FileUtils.forceMkdir(new File(basePath));
14 File htmlFile = new File(String.format("%s%s%s", basePath,File.separator,"index.html"));
15 Writer fw=null;
16 PrintWriter bw=null;
17 //构建html文件
18 try{
19 fw= new BufferedWriter( new OutputStreamWriter(new FileOutputStream(htmlFile.getPath()),"UTF-8"));
20 bw=new PrintWriter(fw);
21 //添加表头及可缩放样式
22 String head="<!DOCTYPE html><html><head><meta charset=\"UTF-8\"></head><body style=\"transform: scale(0.7,0.7);-webkit-transform: scale(0.7,0.7);\">";
23 StringBuilder body=new StringBuilder();
24 for (String e : sheets) {
25 body.append(e);
26 }
27 String foot="</body></html>";
28 bw.write(String.format("%s%s%s", head,body.toString(),foot));
29 }catch(Exception e){
30 throw new Exception("");//错误扔出
31 }finally{
32 if (bw != null) {
33 bw.close();
34 }
35 if(fw!=null){
36 fw.close();
37 }
38 }
39 String htmlZipFile=String.format("%s%s%s.%s",uploadPath,File.separator,file.getName().substring(0,file.getName().lastIndexOf(".")),"ZIP");
40 //压缩文件
41 scormService.zip(basePath, htmlZipFile);
42 file.delete();//删除上传的xlsx文件
43 FileUtils.forceDelete(new File(basePath));
44 return new ProcessFileInfo(true,new File(htmlZipFile).getName(),htmlZipFile);
45 }
(代码片段二)
1 /**
2 * 程序入口方法
3 *
4 * @param filePath
5 * 文件的路径
6 * @return <table>
7 * ...
8 * </table>
9 * 字符串
10 */
11 public static List<String> readExcelToHtml(String filePath) {
12 List<String> htmlExcel=null;
13 try {
14 File sourcefile = new File(filePath);
15 InputStream is = new FileInputStream(sourcefile);
16 Workbook wb = WorkbookFactory.create(is);
17 htmlExcel = getExcelToHtml(wb);
18 } catch (EncryptedDocumentException e) {
19 e.printStackTrace();
20 } catch (FileNotFoundException e) {
21 e.printStackTrace();
22 } catch (InvalidFormatException e) {
23 e.printStackTrace();
24 } catch (IOException e) {
25 e.printStackTrace();
26 }
27 return htmlExcel;
28
29 }
以上只展示了xlsx文件的内容包装和解析excel的入口方法,整个解析类全部放在了utils包下面,service里面只管调用方法传参就好了,如下图:
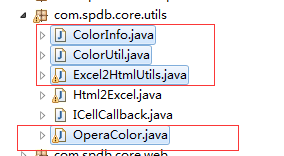
解析Excel的工具类一共有四个文件类,其中Excel2HtmlUtils是入口类,其它三个均是关联Excel2HtmlUtils类处理Excel样式,需要注意的是:工具类处理Excel的时候一定要限制处理记录的数量,以免造成内存溢出错误,顺便说下:如果您解析的html供移动端使用,建议给html设置可缩放大小=>transform: scale(0.7,0.7);-webkit-transform: scale(0.7,0.7);。
说完Excel解析,下面给出pdf(图片ZIP包)解析html的代码片段,由于代码较为简单,不多的解释,以下是具体的实现代码:
1 /**
2 * 根据文件名中的数字排列图片
3 * a>提取文件名中的数字放入int数组(序列)
4 * b>判断序列数组元素个数与文件个数是否一致,不一致则抛出
5 * c>将序列数组从小到大排列
6 * d>遍历序列数组获取Map中的文件名(value)并写html
7 */
8 String nm=null;
9 int[] i=new int[imgNames.size()];
10 Map<Integer,String> names=new HashMap<Integer,String>();
11 Pattern p=Pattern.compile("[^0-9]");
12 for(int j=0;j<imgNames.size();j++){
13 nm=imgNames.get(j).substring(0,imgNames.get(j).lastIndexOf("."));//提取名称
14 String idx=p.matcher(nm).replaceAll("").trim();
15 i[j]=Integer.parseInt("".equals(idx)?"0":idx);
16 names.put(i[j],imgNames.get(j));
17 }
18 if(names.keySet().size()!=i.length){
19 //System.out.println("====请检查您的图片编号====");/*重复或者不存在数字编号*/
20 return new ProcessFileInfo(false,null,null);
21 }
22 Arrays.sort(i);//int数组内元素从小到大排列
23
24 //包装成html
25 StringBuilder html=new StringBuilder();
26 html.append("<!DOCTYPE html><html><head><meta charset='UTF-8'><title>PDF</title></head>");
27 html.append("<body style=\"margin:0px 0px;padding:0px 0px;\">");
28 for (int k : i) {
29 html.append(String.format("%s%s%s%s%s","<div style=\"width:100%;\"><img src=\"./",fileName,File.separator,names.get(k),"\" style=\"width:100%;\" /></div>"));
30 }
31 html.append("</body></html>");
32 File indexFile=new File(String.format("%s%s%s",basePath,File.separator,"index.html"));
33 Writer fw=null;
34 PrintWriter bw=null;
35 //构建文件(html写入html文件)
36 try{
37 fw= new BufferedWriter( new OutputStreamWriter(new FileOutputStream(indexFile),"UTF-8"));//以UTF-8的格式写入文件
38 bw=new PrintWriter(fw);
39 bw.write(html.toString());
40 }catch(Exception e){
41 throw new Exception(e.toString());//错误扔出
42 }finally{
43 if (bw != null) {
44 bw.close();
45 }
46 if(fw!=null){
47 fw.close();
48 }
49 }
50 String zipFilePath=String.format("%s%s%s.%s", uploadPath,File.separator,file.hashCode(),"ZIP");
51 scormService.zip(basePath, zipFilePath);
52 //删除文件
53 file.delete();
54 FileUtils.forceDelete(new File(basePath));
55 return new ProcessFileInfo(true,new File(zipFilePath).getName(),zipFilePath);
56 }
同Excel,由于我将ppt存为mp4格式,上传后只需要做简单包装就可以了,处理的时候一定要注意html对视频的相对引用,以下是具体的实现代码:
1 /**
2 *
3 * @param file 上传的文件的路径 c://xx.//xxx.mp4
4 * @param uploadPath 保存html的基目录路径
5 * @return
6 * @throws Exception
7 */
8 public ProcessFileInfo processPPTX(File file,String uploadPath)throws Exception{
9 String fileName=file.getName().substring(0,file.getName().lastIndexOf("."));//获取文件名称
10 String suffix=file.getName().substring(file.getName().lastIndexOf(".")+1,file.getName().length()).toLowerCase();//音频文件后缀名
11 String basePath=String.format("%s%s%s", uploadPath,File.separator,fileName);
12 FileUtils.forceMkdir(new File(basePath));
13 //将视频文件copy到basePath内
14 String videoPath=String.format("%s%s%s", basePath,File.separator,file.getName());
15 FileUtils.copyFile(file, new File(videoPath));
16 StringBuilder html=new StringBuilder();
17 html.append("<!DOCTYPE html><html><head><meta charset='utf-8'><title>powerpoint</title></head>");
18 html.append("<body style=\"margin:0px 0px;\"><div style=\"width:100%;margin:auto 0% auto 0%;\">");
19 html.append("<video controls=\"controls\" width=\"100%\" height=\"100%\" name=\"media\" >");//无背景图片
20 html.append(String.format("%s%s.%s%s%s%s%s","<source src=\"",fileName,suffix,"\" type=\"audio/",suffix,"\" >","</video></div>"));//视频
21 html.append("</body></html>");//结尾
22 File indexFile=new File(String.format("%s%s%s",basePath,File.separator,"index.html"));
23 Writer fw=null;
24 PrintWriter bw=null;
25 //构建文件(html写入html文件)
26 try{
27 fw= new BufferedWriter( new OutputStreamWriter(new FileOutputStream(indexFile),"UTF-8"));//以UTF-8的格式写入文件
28 bw=new PrintWriter(fw);
29 bw.write(html.toString());
30 }catch(Exception e){
31 throw new Exception(e.toString());//错误扔出
32 }finally{
33 if (bw != null) {
34 bw.close();
35 }
36 if(fw!=null){
37 fw.close();
38 }
39 }
40 String zipFilePath=String.format("%s%s%s.%s", uploadPath,File.separator,fileName,"ZIP");
41 scormService.zip(basePath, zipFilePath);
42 //删除文件
43 file.delete();
44 FileUtils.forceDelete(new File(basePath));
45 return new ProcessFileInfo(true,new File(zipFilePath).getName(),zipFilePath);
46 }
虽然需求最终还是改成最简单的实现方式,这中间近乎白忙活的结果研究出来的实现方案还是有必要分享的,以上如能帮助到开发者,哪怕只有一位,也是非常值得的。

