
Spark 简介
行业广泛使用Hadoop来分析他们的数据集。原因是Hadoop框架基于一个简单的编程模型(MapReduce)。这里,主要关注的是在处理大型数据集时在查询之间的等待时间和运行程序的等待时间方面保持速度。
Hadoop只是实现Spark的方法之一。Spark以两种方式使用Hadoop - 一个是存储,另一个是处理。由于Spark具有自己的集群管理计算,因此它仅使用Hadoop进行存储。
Apache Spark是一种快速的集群计算技术,专为快速计算而设计。它基于Hadoop MapReduce,它扩展了MapReduce模型,以有效地将其用于更多类型的计算,包括交互式查询和流处理。 Spark的主要特性是它的内存中集群计算,提高了应用程序的处理速度。
Spark安装
安装Hadoop
在大数据-01-安装Hadoop中, 我们已经安装好了Hadoop 2.7集群, 现在我们开始安装Spark, 因为我在上文中装的是jdk7,然而新的Spark需要JDK8,所有我们升级到JDK8:
# 在集群所有机器上,备份原JDK7
sudo mv /usr/local/java/jdk1.7.0_75 /usr/local/java/jdk1.7.0_75_bak
# 安装JDK 8
sudo apt-get install openjdk-8-jdk
# 安装成功后
java -version # 会显示java 1.8版本号
# 更新hadoop环境配置,
# hadoop_env.sh修改export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
sudo vim /usr/local/hadoop/etc/hadoop/hadoop_env.sh
# 修改了全局配置
# profile修改export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
sudo vim /etc/profile
安装Scala
Scala的安装参见,前述文章大数据-02-Scala入门
安装Spark
我们下载相应的spark-2.3.0-bin-hadoop2.7.tgz预先编译的版本。
sudo mkdir /usr/local/spark
sudo mv spark-2.3.0-bin-hadoop2.7.tgz /usr/local/spark
cd /usr/local/spark/
sudo tar -zxf spark-2.3.0-bin-hadoop2.7.tgz
添加环境变量
sudo vim ~/.bashrc
添加内容如下:
export SCALA_HOME=/usr/local/scala/scala-2.10.7
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SPARK_HOME=/usr/local/spark/spark-2.3.0-bin-hadoop2.7
export PATH=${SPARK_HOME}/sbin:${SCALA_HOME}/bin:$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
添加Spark运行环境
cd /usr/local/spark/spark-2.3.0-bin-hadoop2.7/conf
sudo cp spark-env.sh.template spark-env.sh
sudo vim spark-env.sh
添加如下内容
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SCALA_HOME=/usr/local/scala/scala-2.10.7
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
配置Spark服务器节点
cp slaves.template slaves
sudo vim slaves
添加节点, 我们HDFS集群有2个节点,分别Master和Slave1修改如下
#A Spark Worker will be started on each of the machines listed below.
Master
Slave1
同步Spark配置都其它服务器
sudo chown -R hadoop /usr/local/spark
scp /etc/profile Slave1:/etc/profile
scp -r /usr/local/spark Slave1:/usr/local/
启动Spark集群
cd /usr/local/spark/spark-2.3.0-bin-hadoop2.7/sbin
# 这里重命名一个,方便在外面访问
sudo cp start-all.sh spark-start-all.sh
# 启动Spark集群
spark-start-all.sh
然后访问自己的站点,效果如下
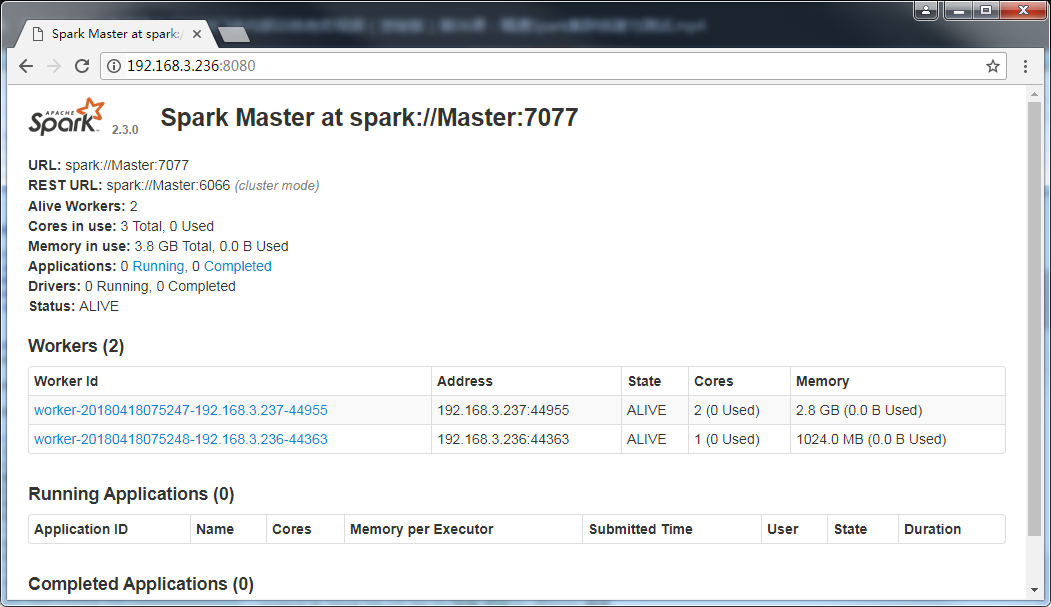
加载文件到HDFS
为了能够读取HDFS中的文件,请首先启动Hadoop中的HDFS组件。
start-dfs.sh
启动结束后,HDFS开始进入可用状态。如果你在HDFS文件系统中,还没有为当前Linux登录用户创建目录(本教程统一使用用户名hadoop登录Linux系统),请使用下面命令创建:
hdfs dfs -mkdir -p /user/hadoop
也就是说,HDFS文件系统为Linux登录用户开辟的默认目录是“/user/用户名”(注意:是user,不是usr),本教程统一使用用户名hadoop登录Linux系统,所以,上面创建了“/user/hadoop”目录,再次强调,这个目录是在HDFS文件系统中,不在本地文件系统中。创建好以后,下面我们使用命令查看一下HDFS文件系统中的目录和文件:
hdfs dfs -ls .
hdfs dfs -ls /user
hdfs dfs -ls /user/hadoop
hdfs dfs -ls / # 查看根目录
上面的一个点号“.”,表示要查看Linux当前登录用户hadoop在HDFS文件系统中与hadoop对应的目录下的文件,也就是查看HDFS文件系统中“/user/hadoop/”目录下的文件。
我们把本地文件系统中的“/usr/local/spark/spark-2.3.0-bin-hadoop2.7/README.md”上传到分布式文件系统HDFS中(放到hadoop用户目录下):
hdfs dfs -put /usr/local/spark/spark-2.3.0-bin-hadoop2.7/README.md .
我们使用cat命令查看一个HDFS中的README.md文件的内容,命令如下:
hdfs dfs -cat ./README.md
上面命令执行后,就会看到HDFS中README.md的内容了。
现在,让我们打开spark-shell窗口,编写语句从HDFS中加载文件,并显示第一行文本内容:
注意,在后凡是在scala>打头的命令, 都表示是在Spark Shell中输入,否则就是Shell !!!
cd /usr/local/spark/spark-2.3.0-bin-hadoop2.7
./bin/spark-shell
scala> val textFile = sc.textFile("hdfs://Master:9000/user/hadoop/README.md")
scala> textFile.first()
执行上面语句后,就可以看到HDFS文件系统中(不是本地文件系统)的README.md的第一行内容了。
需要注意的是,sc.textFile(“hdfs://Master:9000/user/hadoop/README.md”)中,“hdfs://Master:9000/”是前面介绍Hadoop安装内容时确定下来的端口地址9000t和服务器名字。实际上,也可以省略不写,如下三条语句都是等价的:
val textFile = sc.textFile("hdfs://Master:9000/user/hadoop/README.md")
val textFile = sc.textFile("/user/hadoop/README.md")
val textFile = sc.textFile("README.md")
下面,我们再把textFile的内容写回到HDFS文件系统中(写到hadoop用户目录下):
scala> textFile.saveAsTextFile("writeback")
执行上面命令后,文本内容会被写入到HDFS文件系统的“/user/hadoop/writeback”目录下,我们可以切换到Linux Shell命令提示符窗口查看一下:
hdfs dfs -ls .
hdfs dfs -ls ./writeback
执行结果中,可以看到存在两个文件:part-00000和_SUCCESS。我们使用下面命令输出part-00000文件的内容(注意:part-00000里面有五个零):
hdfs dfs -cat ./writeback/part-00000
执行结果中,就可以看到和README.md文件中一样的文本内容。
词频统计
有了前面的铺垫性介绍,下面我们就可以开始第一个Spark应用程序:WordCount。
请切换到spark-shell窗口:
scala> val textFile = sc.textFile("hdfs://Master:9000/user/hadoop/README.md")
scala> val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
scala> wordCount.collect()
上面只给出了代码,省略了执行过程中返回的结果信息,因为返回信息很多。
下面简单解释一下上面的语句。
- textFile包含了多行文本内容,textFile.flatMap(line => line.split(” “))会遍历textFile中的每行文本内容,当遍历到其中一行文本内容时,会把文本内容赋值给变量line
- 并执行Lamda表达式line => line.split(" ")。line => line.split(” “)是一个Lamda表达式,左边表示输入参数,右边表示函数里面执行的处理逻辑,这里执行line.split(” “),也就是针对line中的一行文本内容,采用空格作为分隔符进行单词切分,从一行文本切分得到很多个单词构成一个单词集合, 最终,多行文本,就得到多个单词集合。
- textFile.flatMap()操作就把这多个单词集合“拍扁”得到一个大的单词集合。
- 然后,针对这个大的单词集合,执行map()操作,也就是map(word => (word, 1)),这个map操作会遍历这个集合中的每个单词,当遍历到其中一个单词时,就把当前这个单词赋值给变量word,并执行Lamda表达式word => (word, 1),这个Lamda表达式的含义是,word作为函数的输入参数,然后,执行函数处理逻辑,这里会执行(word, 1),也就是针对输入的word,构建得到一个tuple,形式为(word,1),key是word,value是1(表示该单词出现1次)。
- 程序执行到这里,已经得到一个RDD,这个RDD的每个元素是(key,value)形式的tuple。最后,针对这个RDD,执行reduceByKey((a, b) => a + b)操作,这个操作会把所有RDD元素按照key进行分组,然后使用给定的函数(这里就是Lamda表达式:(a, b) => a + b),对具有相同的key的多个value进行reduce操作,返回reduce后的(key,value),比如(“hadoop”,1)和(“hadoop”,1),具有相同的key,进行reduce以后就得到(“hadoop”,2),这样就计算得到了这个单词的词频。
编写独立应用程序执行词频统计
(一)编写Scala独立应用程序
接着我们通过一个简单的应用程序 SimpleApp 来演示如何通过 Spark API 编写一个独立应用程序。使用 Scala 编写的程序需要使用 sbt 进行编译打包,相应的,Java 程序使用 Maven 编译打包,而 Python 程序通过 spark-submit 直接提交。
- 安装sbt
sbt是一款Spark用来对scala编写程序进行打包的工具,这里简单介绍sbt的安装过程,感兴趣的读者可以参考官网资料了解更多关于sbt的内容。
Spark 中没有自带 sbt,这里直接给出sbt-launch.jar的下载地址,直接点击下载即可。
我们选择安装在 /usr/local/sbt 中:
sudo mkdir /usr/local/sbt
sudo chown -R hadoop /usr/local/sbt # 此处的 hadoop 为你的用户名
cd /usr/local/sbt
下载后,执行如下命令拷贝至 /usr/local/sbt 中:
接着在 /usr/local/sbt 中创建 sbt 脚本(vim ./sbt),添加如下内容:
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java \$SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"
保存后,为 ./sbt 脚本增加可执行权限:
chmod u+x ./sbt
最后运行如下命令,检验 sbt 是否可用(请确保电脑处于联网状态,首次运行会处于 “Getting org.scala-sbt sbt 0.13.11 …” 的下载状态,请耐心等待。笔者等待了 7 分钟才出现第一条下载提示):
./sbt sbt-version
只要能得到如下图的版本信息就没问题:

2.编写Scala应用程序测试一下
在终端中执行如下命令创建一个文件夹 sparkapp 作为应用程序根目录:
cd ~ # 进入用户主文件夹
mkdir -p ./sparkapp/src/main/scala # 创建所需的文件夹结构
在 ./sparkapp/src/main/scala 下建立一个名为 SimpleApp.scala 的文件(vim ./sparkapp/src/main/scala/SimpleApp.scala),添加代码如下(目前不需要理解代码的具体含义,只需要理解如何编译运行代码就可以):
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/spark-2.3.0-bin-hadoop2.7/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
该程序计算 /usr/local/spark/README 文件中包含 “a” 的行数 和包含 “b” 的行数。代码第8行的 /usr/local/spark 为 Spark 的安装目录,如果不是该目录请自行修改。不同于 Spark shell,独立应用程序需要通过 val sc = new SparkContext(conf) 初始化 SparkContext,SparkContext 的参数 SparkConf 包含了应用程序的信息。
使用sbt打包Scala程序
该程序依赖 Spark API,因此我们需要通过 sbt 进行编译打包。 请在./sparkapp 中新建文件 simple.sbt(vim ./sparkapp/simple.sbt),添加内容如下,声明该独立应用程序的信息以及与 Spark 的依赖关系:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.3.0"
文件 simple.sbt 需要指明 Spark 和 Scala 的版本。在上面的配置信息中,scalaVersion用来指定scala的版本,sparkcore用来指定spark的版本,这两个版本信息都可以在之前的启动 Spark shell 的过程中,从屏幕的显示信息中找到。下面就是笔者在启动过程当中,看到的相关版本信息(备注:屏幕显示信息会很长,需要往回滚动屏幕仔细寻找信息)。
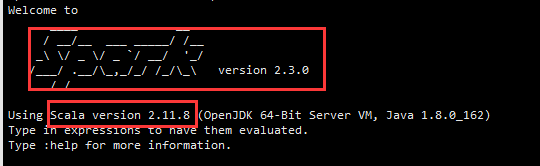
为保证 sbt 能正常运行,先执行如下命令检查整个应用程序的文件结构:
cd ~/sparkapp/
find .
文件结构应如下图所示:

接着,我们就可以通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包 ):
/usr/local/sbt/sbt package
对于刚安装好的Spark和sbt而言,第一次运行上面的打包命令时,会需要几分钟的运行时间,因为系统会自动从网络上下载各种文件。后面再次运行上面命令,就会很快,因为不再需要下载相关文件。
打包成功的话,会输出如下内容:
........
[info] Done packaging.
[success] Total time: 513 s, completed Apr 19, 2018 1:08:49 AM
生成的 jar 包的位置为 ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar。
4.通过 spark-submit 运行程序
最后,我们就可以将生成的 jar 包通过 spark-submit 提交到 Spark 中运行了,命令如下:
/usr/local/spark/spark-2.3.0-bin-hadoop2.7/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
/usr/local/spark/spark-2.3.0-bin-hadoop2.7/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar 2>&1 | grep "Lines with a:"
最终得到的结果如下:
Lines with a: 61, Lines with b: 30
自此,你就完成了你的第一个 Spark 应用程序了。
(二)编写Scala独立应用程序执行词频统计
下面我们编写一个Scala应用程序来实现词频统计。
请登录Linux系统(本教程统一采用用户名hadoop进行登录),进入Shell命令提示符状态,然后,执行下面命令:
# 这里加入-p选项,可以一起创建src目录及其子目录
mkdir -p /usr/local/spark/mycode/wordcount/src/main/scala
请在“/usr/local/spark/mycode/wordcount/src/main/scala”目录下新建一个test.scala文件,里面包含如下代码:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "hdfs://Master:9000/user/hadoop/README.md"
val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
注意,SparkConf().setAppName(“WordCount”).setMaster(“local2”)这句语句,也可以删除.setMaster(“local2”),只保留 val conf = new SparkConf().setAppName(“WordCount”)。
如果test.scala没有调用SparkAPI,那么,只要使用scalac命令编译后执行即可。但是,这个test.scala程序依赖 Spark API,因此我们需要通过 sbt 进行编译打包(前面的这个章节已经介绍过如何使用sbt进行编译打包)。下面我们再演示一次。
请执行如下命令:
cd /usr/local/spark/mycode/wordcount/
vim simple.sbt
通过上面代码,新建一个simple.sbt文件,请在该文件中输入下面代码:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.3.0"
注意, “org.apache.spark”后面是两个百分号,千万不要少些一个百分号%,如果少了,编译时候会报错。
下面我们使用 sbt 打包 Scala 程序。为保证 sbt 能正常运行,先执行如下命令检查整个应用程序的文件结构:
find .
应该是类似下面的文件结构:
.
./simple.sbt
./src
./src/main
./src/main/scala
./src/main/scala/test.scala
接着,我们就可以通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包 ):
/usr/local/sbt/sbt package
上面执行过程需要消耗几分钟时间,屏幕上会返回一下信息:
生成的 jar 包的位置为 /usr/local/spark/mycode/wordcount/target/scala-2.11/simple-project_2.11-1.0.jar。
最后,通过 spark-submit 运行程序。我们就可以将生成的 jar 包通过 spark-submit 提交到 Spark 中运行了,命令如下:
/usr/local/spark/spark-2.3.0-bin-hadoop2.7/bin/spark-submit --class "WordCount" /usr/local/spark/mycode/wordcount/target/scala-2.11/simple-project_2.11-1.0.jar
下面是笔者的word.txt进行词频统计后的结果(你的结果应该和这个类似):
(For,3)
(Programs,1)
(Spark,16)
(particular,2)
(The,1)
(than,1)
(processing.,1)
(APIs,1)
(computation,1)
(Try,1)
([Configuration,1)
(./bin/pyspark,1)
(A,1)
(through,1)
以上内容主要自 http://dblab.xmu.edu.cn/blog/spark/ 感谢原作者

