介绍
- 一个可用好用的百度图片爬取脚本,唯一的不足就是这是单线程的
- 运行环境 Python3.6.0
- 写该脚本的原因:获取图片
- 创作过程有参考
源码
import requests
import os
import re
import itertools
import urllib
import sys
str_table = {
'_z2C$q': ':',
'_z&e3B': '.',
'AzdH3F': '/'
}
char_table = {
'w': 'a',
'k': 'b',
'v': 'c',
'1': 'd',
'j': 'e',
'u': 'f',
'2': 'g',
'i': 'h',
't': 'i',
'3': 'j',
'h': 'k',
's': 'l',
'4': 'm',
'g': 'n',
'5': 'o',
'r': 'p',
'q': 'q',
'6': 'r',
'f': 's',
'p': 't',
'7': 'u',
'e': 'v',
'o': 'w',
'8': '1',
'd': '2',
'n': '3',
'9': '4',
'c': '5',
'm': '6',
'0': '7',
'b': '8',
'l': '9',
'a': '0'
}
char_table = {ord(key): ord(value) for key, value in char_table.items()}
def decode(url):
for key, value in str_table.items():
url = url.replace(key, value)
return url.translate(char_table)
def buildUrls(word):
word = urllib.parse.quote(word)
url = r"http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&fp=result&queryWord={word}&cl=2&lm=-1&ie=utf-8&oe=utf-8&st=-1&ic=0&word={word}&face=0&istype=2nc=1&pn={pn}&rn=60"
urls = (url.format(word=word, pn=x) for x in itertools.count(start=0, step=60))
return urls
re_url = re.compile(r'"objURL":"(.*?)"')
def resolveImgUrl(html):
imgUrls = [decode(x) for x in re_url.findall(html)]
return imgUrls
def downImgs(imgUrl, dirpath, imgName, imgType):
filename = os.path.join(dirpath, imgName)
try:
res = requests.get(imgUrl, timeout=15)
if str(res.status_code)[0] == '4':
print(str(res.status_code), ":", imgUrl)
return False
except Exception as e:
print('抛出异常:', imgUrl)
print(e)
return False
with open(filename + '.' + imgType, 'wb') as f:
f.write(res.content)
return True
def mkDir(dirName):
dirpath = os.path.join(sys.path[0], dirName)
if not os.path.exists(dirpath):
os.mkdir(dirpath)
return dirpath
if __name__ == '__main__':
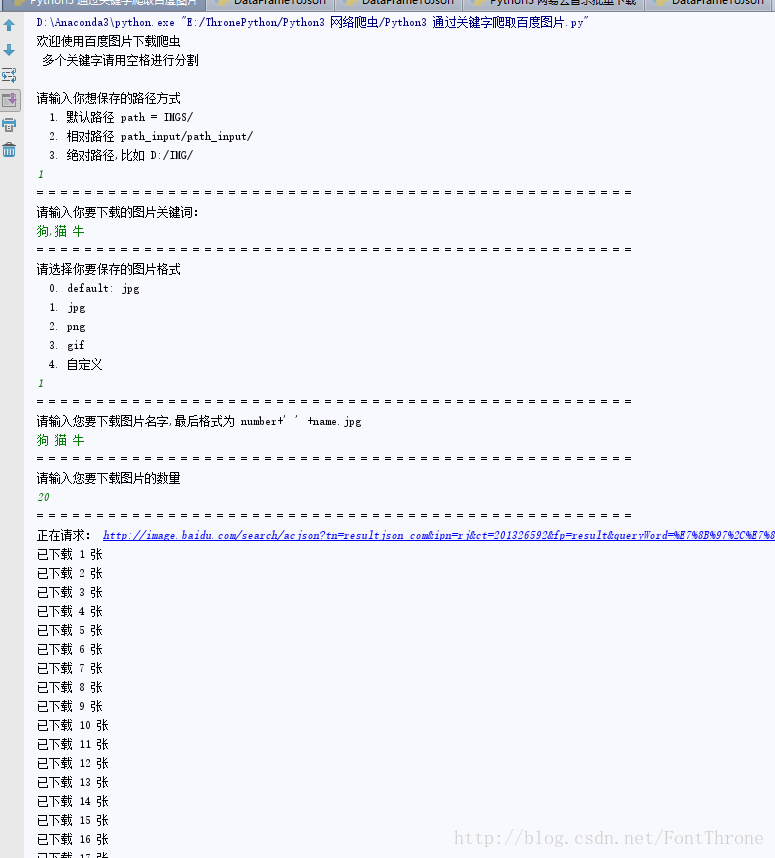
print("欢迎使用百度图片下载爬虫\n 多个关键字请用空格进行分割\n")
choosePath = input('请输入你想保存的路径方式\n 1. 默认路径 path = IMGS/ \n 2. 相对路径 path_input/path_input/ \n 3. 绝对路径,比如 D:/IMG/\n')
if int(choosePath) == 3:
dirpath = input('请输入您要保存图片的路径\n')
elif int(choosePath) == 2:
path = input('请输入您要保存图片的路径\n')
dirpath = mkDir(path)
else:
path = 'IMGS'
dirpath = mkDir(path)
print("= = " * 25)
word = input("请输入你要下载的图片关键词:\n")
print("= = " * 25)
chooseImgType = input('请选择你要保存的图片格式\n 0. default: jpg \n 1. jpg\n 2. png\n 3. gif\n 4. 自定义\n')
chooseImgType = int(chooseImgType)
if chooseImgType == 4:
imgType = input('请输入自定义图片类型\n')
elif chooseImgType == 1:
imgType = 'jpg'
elif chooseImgType == 2:
imgType = 'png'
elif chooseImgType == 3:
imgType = 'gif'
else:
imgType = 'jpg'
print("= = " * 25)
strtag = input("请输入您要下载图片名字,最后格式为 number+' ' +name.%s\n" % imgType)
print("= = " * 25)
numIMGS = input('请输入您要下载图片的数量\n')
numIMGS = int(numIMGS)
urls = buildUrls(word)
index = 0
print("= = " * 25)
for url in urls:
print("正在请求:", url)
html = requests.get(url, timeout=10).content.decode('utf-8')
imgUrls = resolveImgUrl(html)
if len(imgUrls) == 0:
break
for url in imgUrls:
if downImgs(url, dirpath, str(index + 1) + ' ' + strtag, imgType):
index += 1
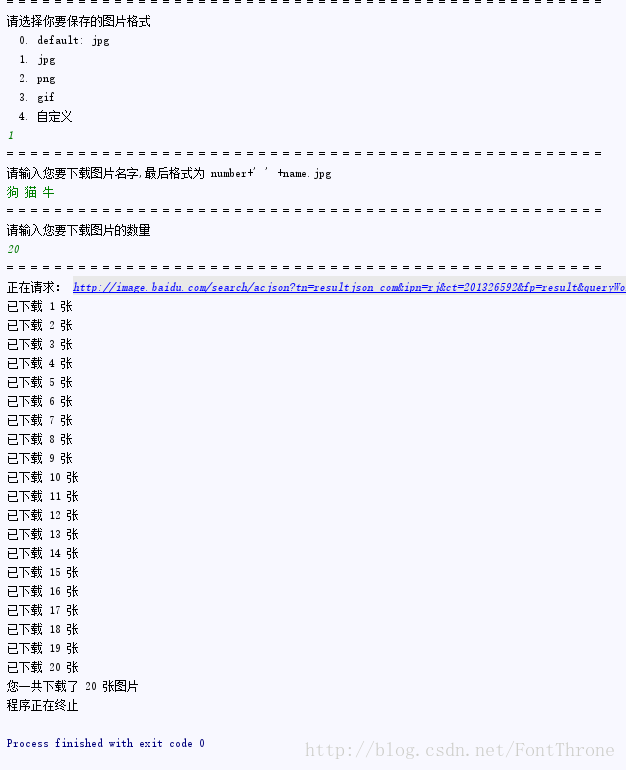
print("已下载 %s 张" % index)
if index == numIMGS:
break
if index == numIMGS:
print('您一共下载了 %s 张图片' % index)
print('程序正在终止')
break
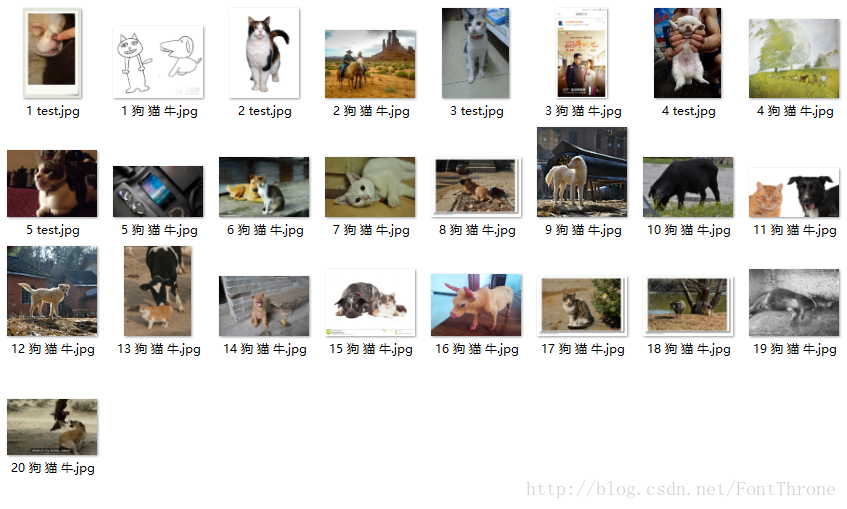
运行演示
参考


