python基础学习笔记(十三)
2013-05-20 23:10 虫师 阅读(118797) 评论(9) 编辑 收藏 举报
re模块包含对 正则表达式。本章会对re模块主要特征和正则表达式进行介绍。
什么是正则表达式
正则表达式是可以匹配文本片段的模式。最简单的正则表达式就是普通字符串,可以匹配其自身。换包话说,正则表达式’python’ 可以匹配字符串’python’ 。你可以用这种匹配行为搜索文本中的模式,并且用计算后有值并发特定模式,或都将文本进行分段。
** 通配符
正则表达式可以匹配多于一个的字符串,你可以使用一些特殊字符创建这类模式。比如点号(.)可以匹配任何字符。在我们用window 搜索时用问号(?)匹配任意一位字符,作用是一样的。那么这类符号就叫 通配符。
** 对特殊字符进行转义
通过上面的方法,假如我们要匹配“python.org”,直接用用‘python.org’可以么?这么做可以,但这样也会匹配“pythonzorg”,这可不是所期望的结果。
好吧!我们需要对它进行转义,可以在它前面加上发斜线。因此,本例中可以使用“python\\.org”,这样就只会匹配“python.org”了。
** 字符集
我们可以使用中括号([ ])括住字符串来创建字符集。可以使用范围,比如‘[a-z]’能够匹配a到z的任意一个字符,还可以通过一个接一个的方式将范围联合起来使用,比如‘[a-zA-Z0-9]’能够匹配任意大小写字母和数字。
反转字符集,可以在开头使用^字符,比如‘[^abc]’可以匹配任何除了a、b、c之外的字符。
** 选择符
有时候只想匹配字符串’python’ 和 ’perl’ ,可以使用选择项的特殊字符:管道符号(|) 。因此, 所需模式可以写成’python|perl’ 。
** 子模式
但是,有些时候不需要对整个模式使用选择符---只是模式的一部分。这时可以使用圆括号起需要的部分,或称子模式。 前例可以写成 ‘p(ython | erl)’
** 可选项
在子模式后面加上问号,它就变成了可选项。它可能出现在匹配字符串,但并非必须的。
r’(heep://)?(www\.)?python\.org’
只能匹配下列字符:
‘http://www.python.org’
‘http://python.org’
‘www.python.org’
‘python.org’
** 重复子模式
(pattern)* : 允许模式重复0次或多次
(pattern)+ : 允许模式重复1次或多次
(pattern){m,n} : 允许模式重复m~ n 次
例如:
r’w * \.python\.org’ 匹配 ‘www.python.org’ 、’.python.org’ 、’wwwwwww.python.org’
r’w + \.python\.org’ 匹配 ‘w.python.org’ ;但不能匹配 ’.python.org’
r’w {3,4}\.python\.org’ 只能匹配‘www.python.org’ 和‘wwww.python.org’
re模块的内容
re模块中一些重要的函数:
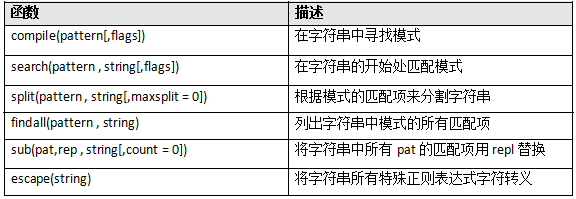
re.compile 将正则表达式转换为模式对象,可以实现更有效率的匹配。
re.search 会在给定字符串中寻找第一个匹配给正则表式的子字符串。找到函数返回MatchObject(值为True),否则返回None(值为False) 。因为返回值的性质,所以该函数可以用在条件语句中:
if re.serch(pat, string):
print ‘found it !’
re.math 会在给定字符串的开头匹配正则表达式。因此,re.math(‘p’ , ‘python’)返回真,re.math(‘p’ , ‘www.python’) 则返回假。
re.split 会根据模式的匹配项来分割字符串。
>>> import re >>> some_text = 'alpha , beta ,,,gamma delta ' >>> re.split('[,]+',some_text) ['alpha ', ' beta ', 'gamma delta ']
re. findall以列表形式返回给定模式的所有匹配项。比如,要在字符串中查找所有单词,可以像下面这么做:
>>> import re >>> pat = '[a-zA-Z]+' >>> text = '"Hm...err -- are you sure?" he said, sounding insecure.' >>> re.findall(pat,text) ['Hm', 'err', 'are', 'you', 'sure', 'he', 'said', 'sounding', 'insecure']
re.sub的作用在于:使用给定的替换内容将匹配模式的子符串(最左端并且重叠子字符串)替换掉。
>>> import re >>> pat = '{name}' >>> text = 'Dear {name}...' >>> re.sub(pat, 'Mr. Gumby',text) 'Dear Mr. Gumby...'
re.escape 函数,可以对字符串中所有可能被解释为正则运算符的字符进行转义的应用函数。
如果字符串很长且包含很多特殊字符,而你又不想输入一大堆反斜线,可以使用这个函数:
>>> re.escape('www.python.org') 'www\\.python\\.org' >>> re.escape('but where is the ambiguity?') 'but\\ where\\ is\\ the\\ ambiguity\\?'
匹配对象和组
简单来说,组就是放置在圆括号里内的子模块,组的序号取决于它左侧的括号数。组0就是整个模块,所以在下面的模式中:
‘There (was a (wee) (cooper)) who (lived in Fyfe)’
包含组有:
0 There was a wee cooper who lived in Fyfe
1 was a wee cooper
2 wee
3 cooper
4 lived in Fyfe
re 匹配对象的重要方法

下面看实例:
>>> import re >>> m = re.match(r'www\.(.*)\..{3}','www.python.org') >>> m.group() 'www.python.org' >>> m.group(0) 'www.python.org' >>> m.group(1) 'python' >>> m.start(1) 4 >>> m.end(1) 10 >>> m.span(1) (4, 10)
group方法返回模式中与给定组匹配的字符串,如果没有组号,默认为0 ;如上面:m.group()==m.group(0) ;如果给定一个组号,会返回单个字符串。
start 方法返回给定组匹配项的开始索引,
end方法返回给定组匹配项的结束索引加1;
span以元组(start,end)的形式返回给组的开始和结束位置的索引。
----------------------------
正则表达式应该是不容易理解的一个知识点;python没意思的基础终于学完了。虽然学的不扎实,但大体有了个印象;后面的将会非常有意思,读取文件,编写图形窗口,连接数据库,web编程....

