Spring Cloud Netflix Zuul 重试会自动跳过经常超时的服务实例的简单说明和分析
在使用E版本的Spring Cloud Netflix Zuul内置的Ribbon重试功能时,发现Ribbon有一个很精妙的特性:
如果某个服务的某个实例经常需要重试,Ribbon则会在自己维护的一个缓存(serverStatsCache)里将其临时标记为不可用(isCircuitBreakerTripped),后续的所有请求都不会到达该服务实例,直到30(maxCircuitTrippedTimeout的默认值)秒之后,才会放一个请求再次去请求该服务实例。
这其实是Ribbon新增的负载均衡策略之一:AvailabilityFilteringRule(可用性过滤)
—————————————————————————————————————————————————————————————————
———————————————分割线—————以下是一些简单的代码跟踪分析—————观看帮助:截图不是很重要,重要的是文字描述————
—————————————————————————————————————————————————————————————————
当使用Spring Cloud F版本的Gateway的重试功能时,发现并没有该策略,愈发对其感兴趣,想知道如何实现的,索性DEBUG跟着断点走了一百下。。。。在Zuul项目中跟代码分析的思路如下:
0、创建一个spring-cloud-starter-netflix-zuul的项目,和eureka、两个服务,其中一个服务处理时间较长,能触发Ribbon的“熔断”。
1、第一个想到的就是通过日志看一看Ribbon在重试失败的时候做了什么,要看日志当然要打开DEBUG日志级别,在application.yml配置文件中添加如下:
logging:
level:
root: debug
2、清理所有不相干的日志,发现发送HTTP请求的时候走的是RetryTemplate的doExeccute方法,反复debug几遍,发现其中的context在执行到以下代码时忽然有了服务实例信息:
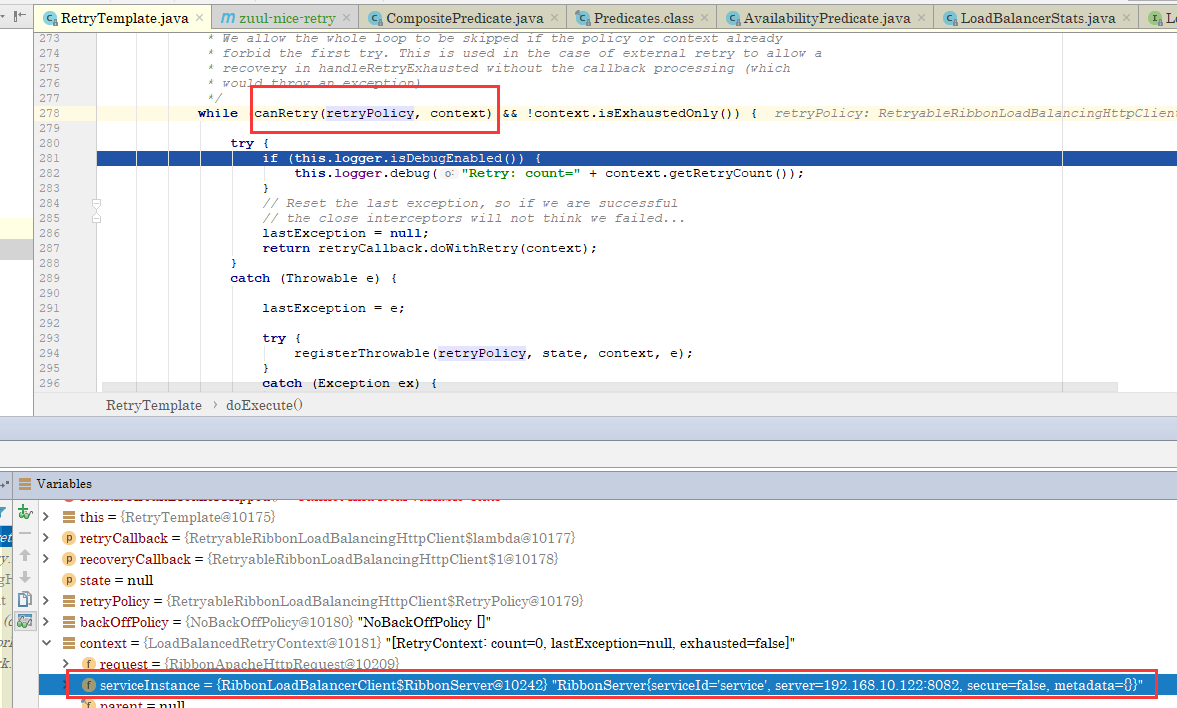
这是一个非常关键的线索,于是重新debug一路跟到给context的serviceInstance赋值的地方

继续跟
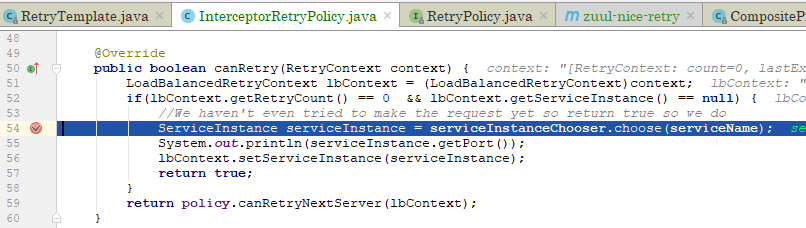
上图第56行可以看到赋值,第54行才是选择服务实例,继续
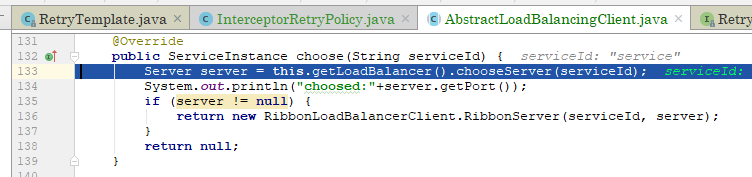
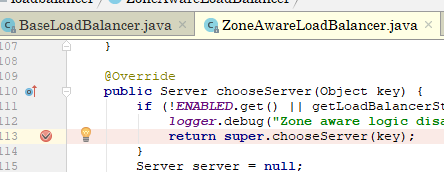
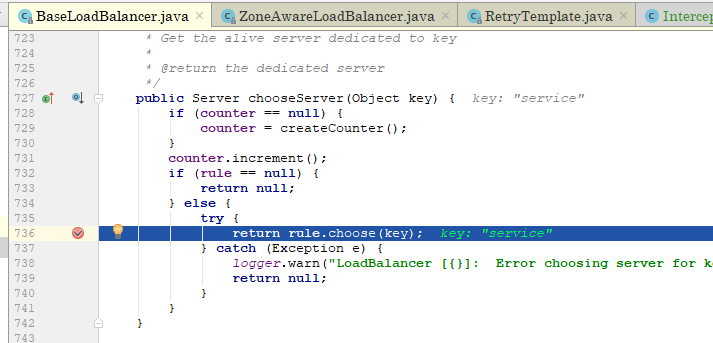
接着:
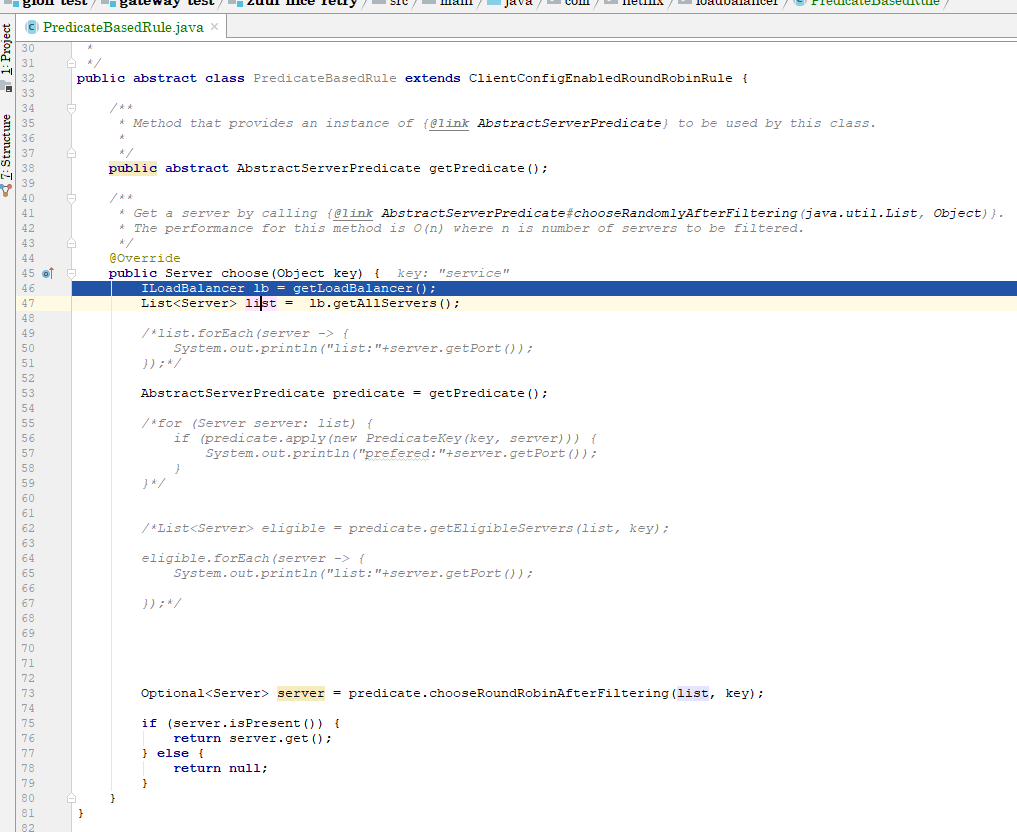
上图是我改后的源码,做了一些实验,发现当某个服务实例总是触发超时重试后,服务列表经过predicate.getEligibleServers(list,key)方法会把该服务实例给过滤掉。继续跟73行代码
中间略去几张截图,直到跟到
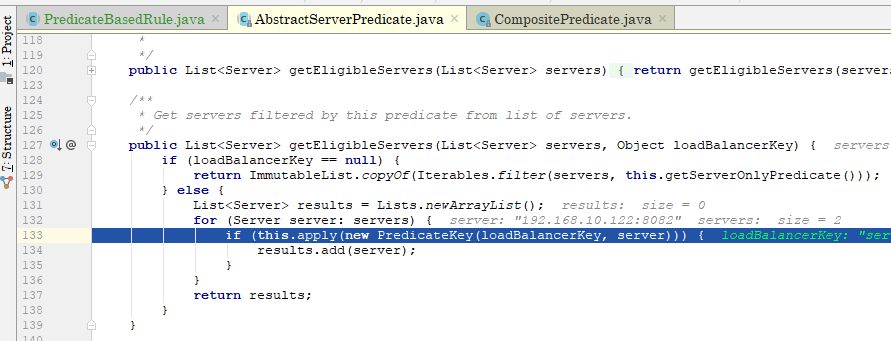
其中的apply方法对服务实例列表中的每个实例进行了过滤,继续跟到其实现
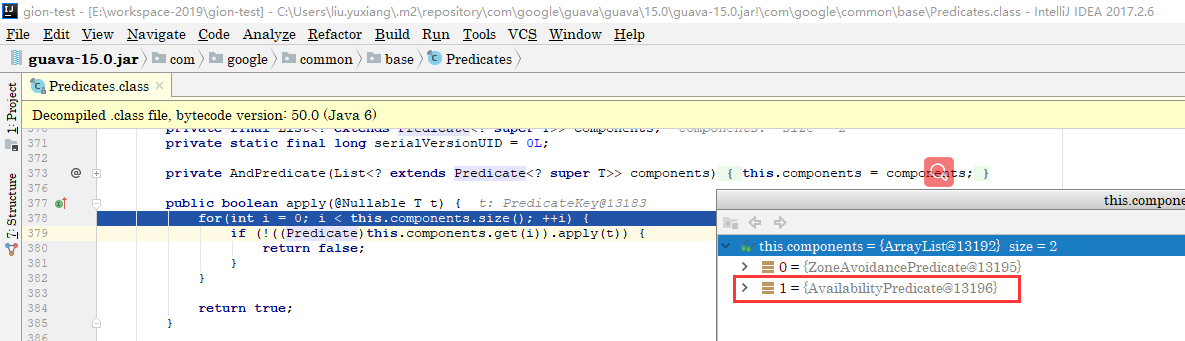
重点来了,用来判断服务实例可不可用的有两个Predicate,其中第二个AvailabilityPredicate就是我们的重点,跟到第二个类的apply方法:
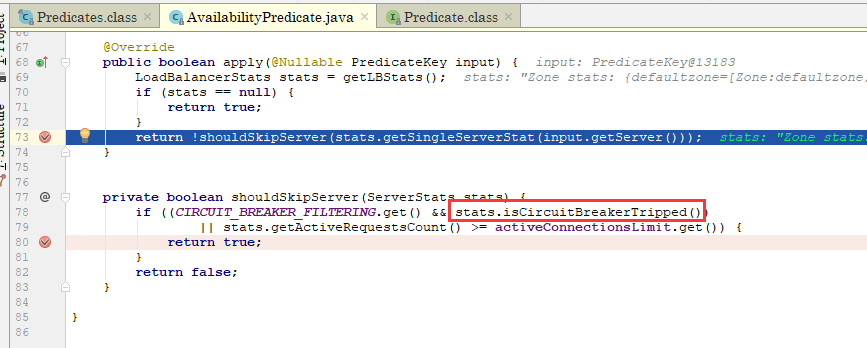
发现总是超时的服务实例,其熔断已经打开,而73行的
stats.getSingleServerStat(input.getServer())
则是整个Ribbon熔断的关键,
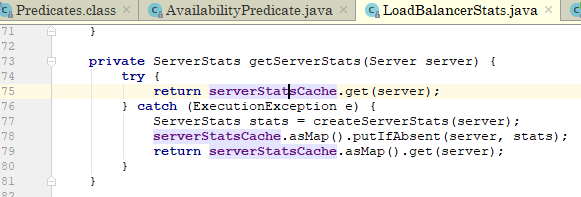
通过上图的变量名:serverStatsCache我们就能看明白,这个变量里保存着服务实例的状态,
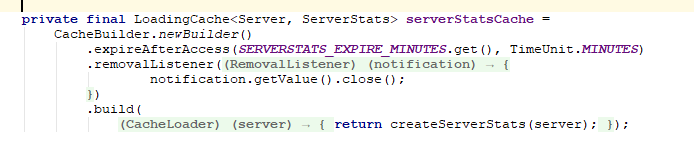
进一步查看ServerStats中的细节,
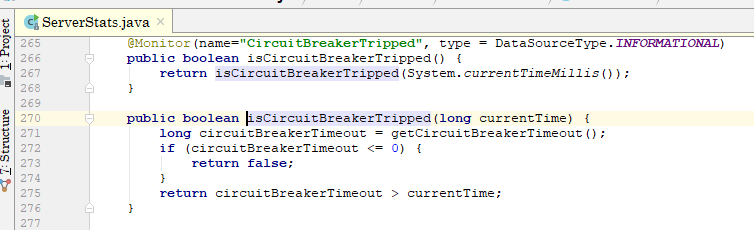
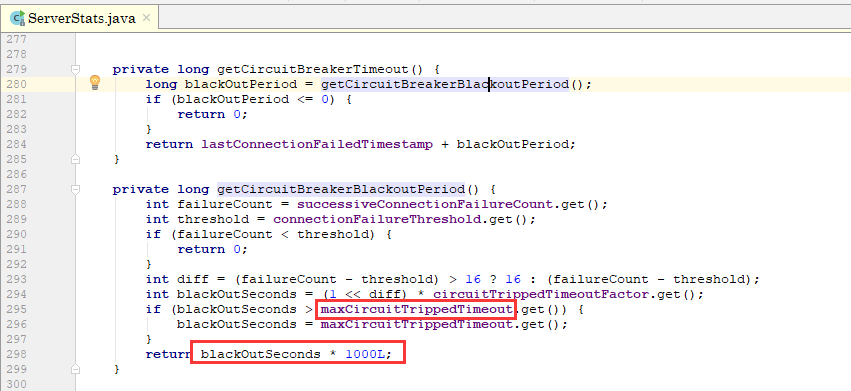
是否熔断的判断规则是最后一次触发熔断加上30秒(如下图),和当前时间对比
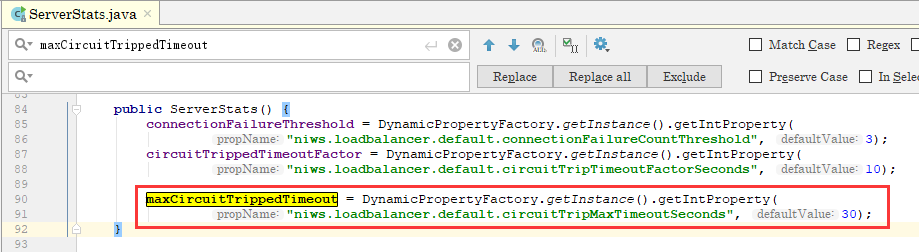
那么上一次熔断的时间是什么时候设置的呢?
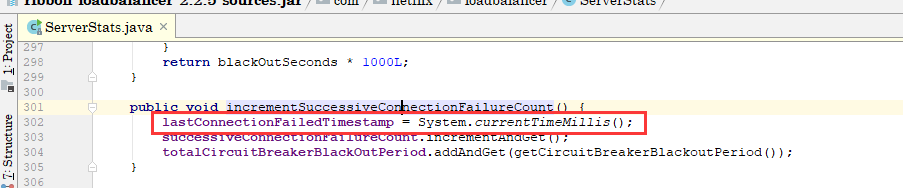
在该方法被调用的时候,至于该方法什么时候被调用的:
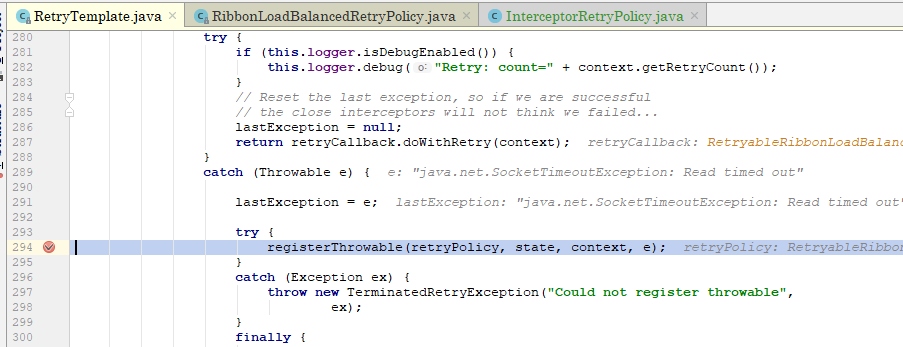
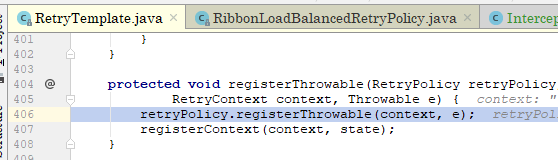
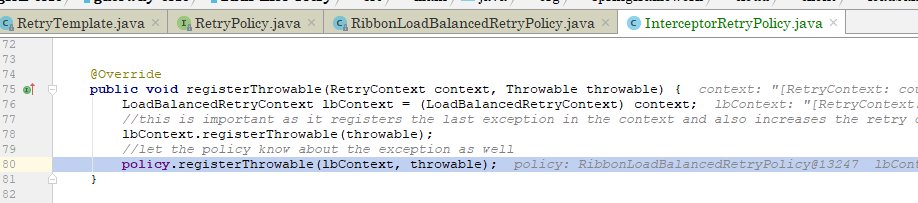
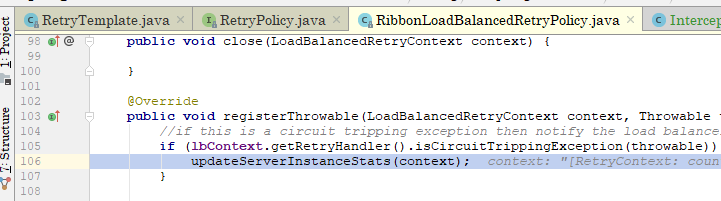
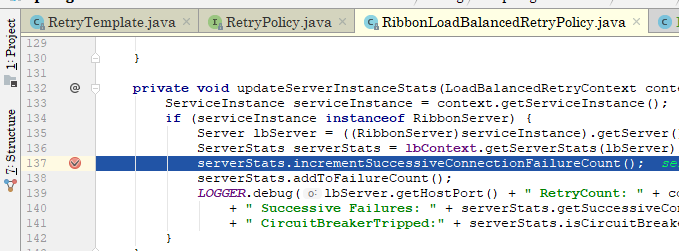
上边五张图对其调用时机进行了展示,简单来说就是在发生
java.net.SocketTimeoutException: Read timed out
异常的时候。
到此分析完毕。
分析完后百度上搜一下ServerStats类中的关键字,如
niws.loadbalancer.default.circuitTripMaxTimeoutSeconds
可以看到对Ribbon已经有了很多优秀而系统的源码分析,有时间可以读一下进一步提高。
本文旨在帮助大家分析Ribbon重试和自带熔断机制,并提供一种源码分析的思路,希望对同行有所帮助。
(完毕)

