全国(不包括港澳台)行政区划代码爬取
概述
网络爬虫主要工作就是跟据指定的url地址 去发送请求,获得响应, 然后解析响应 , 一方面从响应中查找出想要查找的数据,另一方面从响应中解析出新的URL路径。
爬取目标
之前在验证身份证是否符合规则,其中有一项是验证前六位数是否是实际存在的区划代码,就从国家统计局:http://www.stats.gov.cn/找了数据。最新的是2019年1月31号发布的数据http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/index.html, 整体思路依次获取省、市、县/区、镇、村的信息,根据上一级的链接获取下一级的数据。
爬取步骤
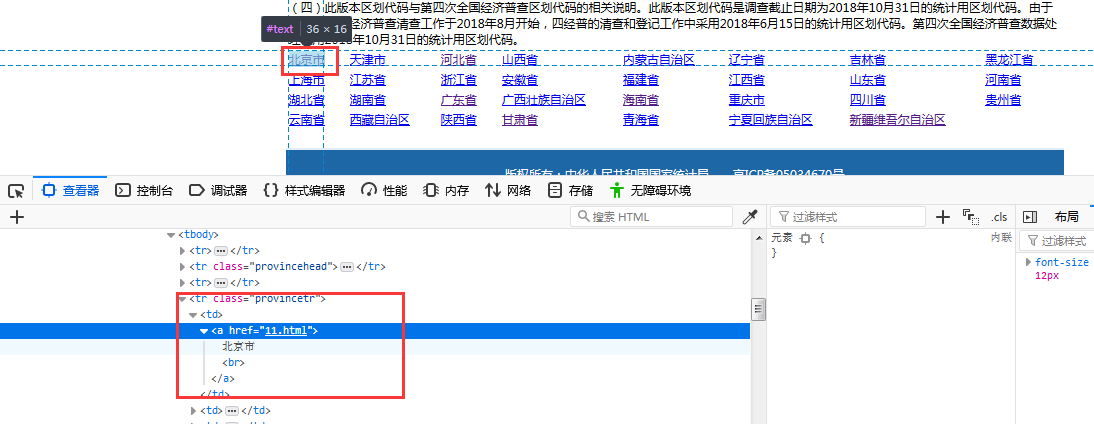
- 1、页面分析:主页面如下,用开发人员查看工具分析页面(F12可以直接调出来)
- 2、分析页面HTML信息:
a、获取省的信息,省的信息是在一个class="provincetr"的tr里面,要提取的信息包括名称、链接;
b、市、县\区、镇信息页面差不多,只有class不一样,分别在class="citytr"、“countytr”、“towntr”的tr里面,要提取的信息包括名称、链接、区划代码,这里注意一些区划,比如市辖区是没有下一级的,要特殊判断一下。大部分区划是市、县\区、镇的顺序,也有一些没有县\区(貌似就广东省中山市、东莞市,海南市儋州市),市直接到镇,也要特殊处理;
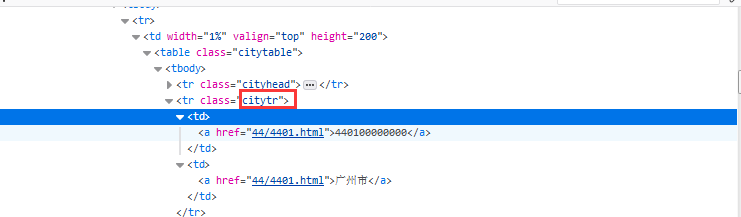
c、村的信息在class=“villagetr”的tr里面,要提取的信息包括名称、城乡分类代码、区划代码;
以上获取的信息都可以经过上一级获取的链接得到下一级的信息,那么就先获取上一级的数据到CSV,再根据上一级的数据获取下一级数据,省、市、县\区数量比较少,可以直接获取页面信息,镇、村的数量比较多,加了代理、爬取过程随机停留一会,分段爬取。以下是获取省、市、县\区信息的代码:
1 import urllib.request 2 import requests 3 import csv 4 import random 5 from urllib import parse 6 from bs4 import BeautifulSoup 7 import time 8 user_agent_list = [ \ 9 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", \ 10 "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \ 11 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \ 12 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \ 13 "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \ 14 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \ 15 "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \ 16 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ 17 "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ 18 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ 19 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \ 20 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \ 21 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ 22 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ 23 "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ 24 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \ 25 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \ 26 "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" 27 ] 28 head = {'User-Agent': random.choice(user_agent_list)} 29 def get_province(url,file_str):#解析省页面信息,获取省信息,返回类似("北京市","http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/11.html")组成的链表 30 province_list=[] 31 my_html= requests.get(url, headers=head) 32 my_html.encoding = 'GB2312' 33 my_soup = BeautifulSoup(my_html.text, 'lxml') 34 my_tr = my_soup.find_all("tr", class_="provincetr") 35 for my_td in my_tr: 36 my_a=my_td.find_all("td") 37 for my_href in my_a: 38 my_url=parse.urljoin(url,my_href.a["href"]) 39 province_list.append((my_href.a.get_text(),my_url)) 40 with open(file_str, 'a', newline='', encoding='gb2312',errors='ignore')as f: 41 write = csv.writer(f) 42 for province_item in province_list: 43 write.writerow([1,province_item[0],province_item[1]]) 44 f.close() 45 46 47 def get_info(url,class_str,file_str,*upper_name_list):#获取市、县\区、镇信息,url是要获取信息的网址,class_str是要提取信息的html内容的class,upper_name_list是上级路径,个数可变 48 if(url==""): 49 return 50 info_list=[] 51 head = {'User-Agent': random.choice(user_agent_list)} 52 my_html= requests.get(url, headers=head) 53 time.sleep(random.random())#随机暂停01秒 54 my_html.encoding = 'GB2312' 55 my_soup = BeautifulSoup(my_html.text, 'lxml') 56 my_tr = my_soup.find_all("tr", class_=class_str)#从html页面提取类型class_str的元素 57 for my_td in my_tr: 58 if(my_td.find("td").a):#有些有链接的,有些没有链接的 59 my_href=my_td.find("td").a["href"] 60 my_href=parse.urljoin(url,my_href) 61 my_code=my_td.find("td").a.get_text() 62 my_name=my_td.find("td").next_sibling.a.get_text() 63 info_list.append((my_name,my_code,my_href)) 64 else: 65 my_href="" 66 my_code=my_td.find("td").get_text() 67 my_name=my_td.find("td").next_sibling.get_text() 68 info_list.append((my_name,my_code,my_href)) 69 with open(file_str, 'a', newline='', encoding='gb2312',errors='ignore')as f: 70 write = csv.writer(f) 71 for info_item in info_list: 72 write.writerow([len(upper_name_list)+1,]+list(upper_name_list)+[info_item[0],info_item[1],info_item[2]]) 73 f.close() 74 return 1 75 76 77 if __name__ == '__main__': 78 base_url = "http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/index.html"#链接网址 79 get_province(base_url,"province_code.csv")#获取省信息 80 81 province_list=[]#根据省链接获取市信息 82 with open('province_code.csv','r')as f: 83 read=csv.reader(f) 84 for province in read: 85 province_list.append(province) 86 f.close() 87 for province in province_list: 88 print(province) 89 #print(province[2],"citytr","city_code.csv",province[1]) 90 city=get_info(province[2],"citytr","city_code.csv",province[1]) 91 92 city_list=[]#根据市链接获取县\区信息 93 with open('city_code.csv','r')as f: 94 read=csv.reader(f) 95 for city in read: 96 city_list.append(city) 97 f.close() 98 for city in city_list: 99 print(city) 100 #print(city[4],"countytr","county_code.csv",city[1],city[2]) 101 town=get_info(city[4],"countytr","county_code.csv",city[1],city[2])
最后获取省、市、县\区的信息如下
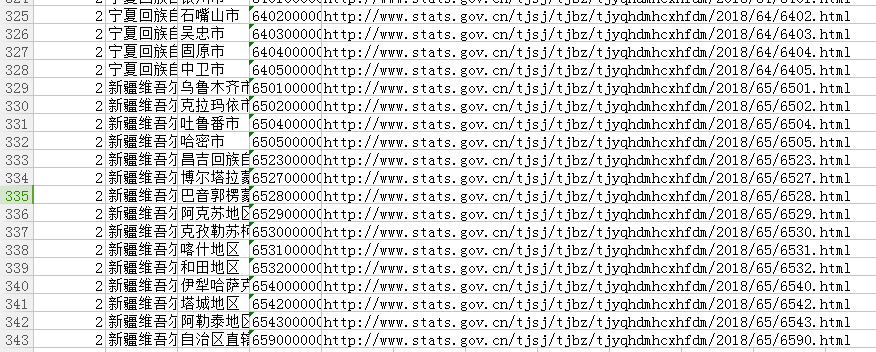

在获取县\区信息的时候中途会有获取失败现象,有各种原因:Max retries exceeded with url、服务器拒绝连接、我使用的网络本身会偶尔断开一下,加了IP代理,使用requests.session,测试了几次,获取获取县\区信息失败的次数减少,但还是有获取失败。村的数量大概是县\区的几十倍,后来想了一个方法,获取失败的时候,暂停一会,继续获取,直到成功为止,代码大概如下:
try:#获取页面内容,如果失败了,停止10s后,继续获取页面内容 my_html= s.get(url, headers=head,proxies = proxy) except: print("#############################################################") time.sleep(10) a=get_info(url,class_str,file_str,*upper_name_list) else: ……
最终代码如下:
import urllib.request import requests import csv import random from urllib import parse from bs4 import BeautifulSoup import time user_agent_list = [ \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", \ "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \ "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \ "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \ "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \ "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \ "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] user_ip_list = [ \ "http://171.41.80.142:9999", \ "http://171.41.80.231:9999", \ "http://112.85.172.58:9999", \ "http://111.79.199.161:9999", \ "http://110.52.235.184:9999", \ "http://110.52.235.198:9999", \ "http://122.193.244.244:9999", \ "http://223.241.78.26:8010", \ "http://110.52.235.54:9999", \ "http://116.209.53.214:9999", \ "http://112.85.130.221:9999", \ "http://60.190.250.120:8080", \ "http://183.148.151.218:9999", \ "http://183.63.101.62:53281", \ "http://112.85.164.249:9999", ] requests.adapters.DEFAULT_RETRIES = 5#重连次数 head = {'User-Agent': random.choice(user_agent_list)} proxy={'proxies': random.choice(user_ip_list)} def get_province(url,file_str):#解析省页面信息,获取省信息,返回类似("北京市","http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/11.html")组成的链表 province_list=[] my_html= requests.get(url, headers=head) my_html.encoding = 'GB2312' my_soup = BeautifulSoup(my_html.text, 'lxml') my_tr = my_soup.find_all("tr", class_="provincetr") for my_td in my_tr: my_a=my_td.find_all("td") for my_href in my_a: my_url=parse.urljoin(url,my_href.a["href"]) province_list.append((my_href.a.get_text(),my_url)) with open(file_str, 'a', newline='', encoding='gb2312',errors='ignore')as f: write = csv.writer(f) for province_item in province_list: write.writerow([1,province_item[0],province_item[1]]) f.close() def get_info(url,class_str,file_str,*upper_name_list):#获取市、县\区、镇信息,url是要获取信息的网址,class_str是要提取信息的html内容的class,upper_name_list是上级路径,个数可变 if(url==""): return info_list=[] head = {'User-Agent': random.choice(user_agent_list)} proxy={'proxies': random.choice(user_ip_list)} s = requests.session() s.keep_alive = False # 关闭多余连接 try:#获取页面内容,如果失败了,停止10s后,继续获取页面内容 my_html= s.get(url, headers=head,proxies = proxy) except: print("#############################################################") time.sleep(10) a=get_info(url,class_str,file_str,*upper_name_list) else: #my_html= requests.get(url, headers=head) #time.sleep(random.random())#随机暂停0~1秒 my_html.encoding = 'GB2312' my_soup = BeautifulSoup(my_html.text, 'lxml') my_tr = my_soup.find_all("tr", class_=class_str)#从html页面提取类型class_str的元素 for my_td in my_tr: if(my_td.find("td").a):#有些有链接的,有些没有链接的 my_href=my_td.find("td").a["href"] my_href=parse.urljoin(url,my_href) my_code=my_td.find("td").a.get_text() my_name=my_td.find("td").next_sibling.a.get_text() info_list.append((my_name,my_code,my_href)) else: my_href="" my_code=my_td.find("td").get_text() my_name=my_td.find("td").next_sibling.get_text() info_list.append((my_name,my_code,my_href)) with open(file_str, 'a', newline='', encoding='gb2312',errors='ignore')as f: write = csv.writer(f) for info_item in info_list: write.writerow([len(upper_name_list)+1,]+list(upper_name_list)+[info_item[0],info_item[1],info_item[2]]) f.close() return 1 def get_village(url,file_str,*upper_name_list):#获取行政村的信息,行政村和市、县\区、镇页面有较大区别,独立一个函数获取行政村信息 if(url==""): return village_list=[] head = {'User-Agent': random.choice(user_agent_list)} proxy={'proxies': random.choice(user_ip_list)} s = requests.session() s.keep_alive = False # 关闭多余连接 try:#获取页面内容,如果失败了,停止10s后,继续获取页面内容 my_html= s.get(url, headers=head,proxies = proxy) except: print("#############################################################") time.sleep(10) a=get_village(url,file_str,*upper_name_list) else: #my_html= requests.get(url, headers=head) my_html.encoding = 'GB2312' my_soup = BeautifulSoup(my_html.text, 'lxml') my_tr = my_soup.find_all("tr", class_="villagetr")#从html页面提取类型class_str的元素 for my_td in my_tr: my_code=my_td.find("td").get_text() my_class_code=my_td.find("td").next_sibling.get_text() my_name=my_td.find("td").next_sibling.next_sibling.get_text() village_list.append((my_name,my_class_code,my_code)) with open(file_str, 'a', newline='', encoding='gb2312',errors='ignore')as f: write = csv.writer(f) for village_item in village_list: write.writerow([len(upper_name_list)+1,]+list(upper_name_list)+[village_item[0],village_item[1],village_item[2]]) f.close() return 1 if __name__ == '__main__': base_url = "http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/index.html"#链接网址 get_province(base_url,"province_code.csv")#获取省信息 province_list=[]#根据省链接获取市信息 with open('province_code.csv','r')as f: read=csv.reader(f) for province in read: province_list.append(province) f.close() for province in province_list: print(province) #print(province[2],"citytr","city_code.csv",province[1]) city=get_info(province[2],"citytr","city_code.csv",province[1]) city_list=[]#根据市链接获取县\区信息 with open('city_code.csv','r')as f: read=csv.reader(f) for city in read: city_list.append(city) f.close() for city in city_list: print(city) #print(city[4],"countytr","county_code.csv",city[1],city[2]) town=get_info(city[4],"countytr","county_code.csv",city[1],city[2]) city_list=[]#根据市链接获取县\区信息,大部分区划是市、县\区、镇的顺序,也有一些没有县\区,市直接到镇,貌似就广东省中山市、东莞市,海南市儋州市 with open('city_code.csv','r')as f:#从市里面获取镇信息 read=csv.reader(f) for city in read: city_list.append(city) f.close() for city in city_list: print(city) #print(city[4],"countytr","county_code.csv",city[1],city[2]) town=get_info(city[4],"towntr","town_code_1.csv",city[1],city[2],"") county_list=[] with open('county_code.csv','r')as f:#从县\区里面获取镇信息 read=csv.reader(f) for county in read: county_list.append(county) f.close() for county in county_list: print(county) #print(city[4],"countytr","county_code.csv",city[1],city[2]) town=get_info(county[5],"towntr","town_code_2.csv",county[1],county[2],county[3]) town_list=[] with open('town_code_1.csv','r')as f:#从县\区里面获取镇信息 read=csv.reader(f) for town in read: town_list.append(town) f.close() with open('town_code_2.csv','r')as f:#从县\区里面获取镇信息 read=csv.reader(f) for town in read: town_list.append(town) f.close() for town in town_list: print(town) #print(city[4],"countytr","county_code.csv",city[1],city[2]) village=get_village(town[6],"village_code.csv",town[1],town[2],town[3],town[4])#url在第7列,也就是town[6],town[1]~[4]是上级区划
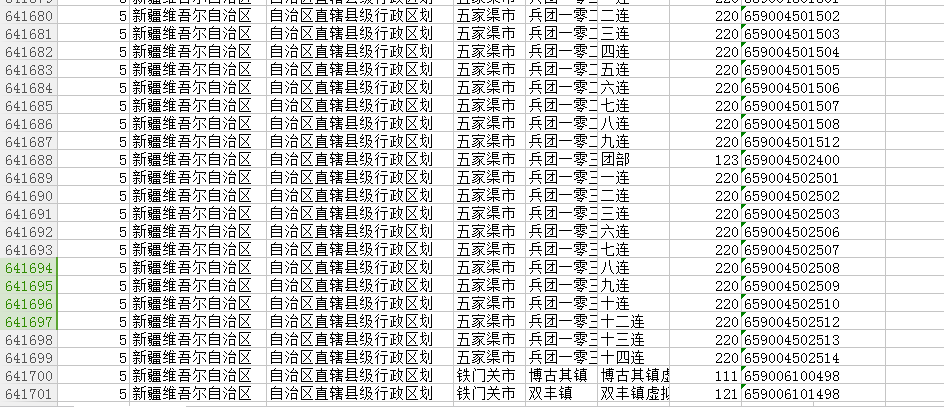
最后获取了全部行政村的数据,64W左右: