

机器学习那些事儿(一)

当大多数人听到“机器学习(Machine Learning )”这个词时,他们首先想到的可能是科幻电影里的机器人:可靠的男管家,致命终结者......事实上,机器学习并不是未来幻想曲,有些地方已经是现实了:从一开始的垃圾邮件过滤,OCR(Optical Character Recognition光学字符识别),再到推荐系统和语音识别等地方都有了很成熟的应用.
什么是机器学习?机器学习什么?为什么要机器学习?
在我们探索机器学习新大陆之前,我们先来看看手中的“地图”,了解这个新大陆的主要地区和最著名的地标:supervised(监督) VS unsupervised(非监督) learning, online(在线) VS batch(批处理) learning, instance-based(基于样本的) VS model-based(基于模型的) learning. 然后我们会介绍一个典型的ML项目的工作流程,讨论你可能会面临的主要挑战,涵盖了如何对机器学习进行模型评估和参数调优。
什么是机器学习?
机器学习是计算机编程的科学和艺术,他可以从数据中学习。通俗点说,机器学习是一种方法,这种方法能够赋予机器学习的能力,这种能力能让它完成直接编程无法完成的任务。Tom Mitchell对“学习”给出的英文定义被很多人经常引用:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.(如果一个系统能够通过执行某个过程改进它的性能,这就是学习)。
举个例子:基于机器学习的垃圾邮件过滤就可以看作是program,他可以从一些已经被标记是否是垃圾邮件的邮件样本中学习如何标记邮件,用于学习的那些邮件称作是训练集,训练集中的每个邮件称为训练样本。在这个例子中任务T是一个决策问题(也称为分类),它需要标记每一封新的邮件是否为垃圾邮件,经验E就是我们所收集的邮件,P就是垃圾邮件识别的准确性。
为什么要使用机器学习?
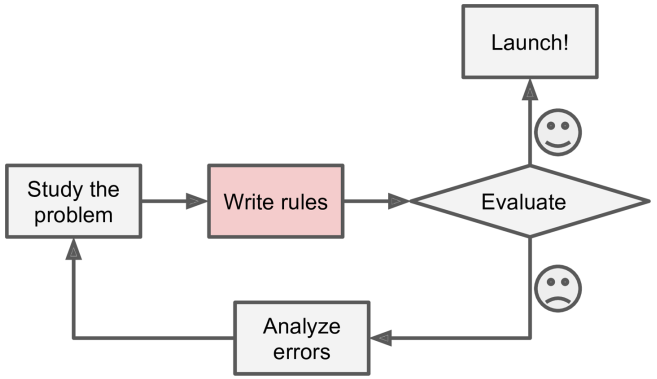
还是用上面垃圾邮寄过滤的例子,如下图,如果不使用机器学习,你可能会制订很多标准来判断一封邮件是不是垃圾邮件,比如,这封邮件里是否包含“信用卡”,“免费”等内容,这样的硬编码会让你写出很多类似于if-else的处理规则,这样的系统不容易维护。
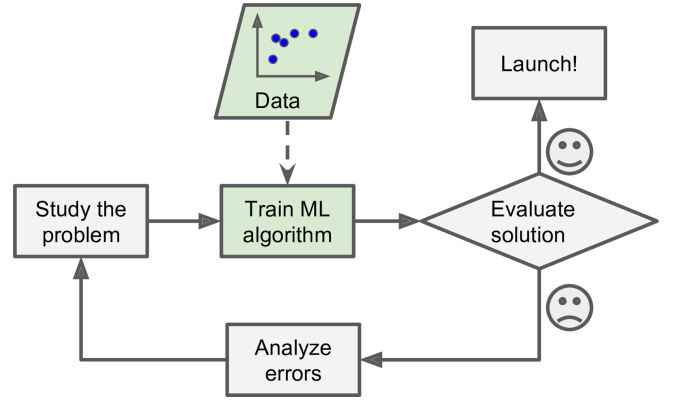
相反,基于机器学习的垃圾邮件过滤技术能自动的挖掘出垃圾邮件的特征,比如,哪一些单词或短语能够作为分辨垃圾邮件的特征。这样的程序短小精湛,更易于维护,效果也会更好。
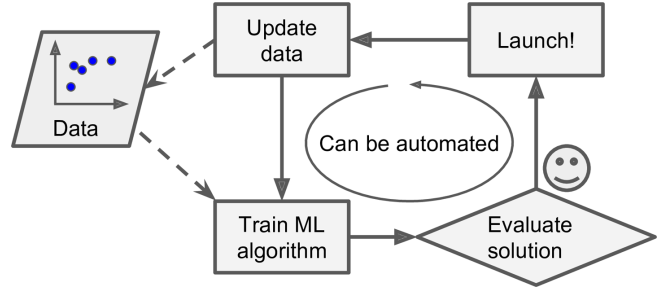
除此之外,如果垃圾邮件制造者发现他们所有包含“4U”的邮件都被拦截了,他们可能用“four U”来代替。针对这样的情况,对于传统的垃圾邮件过滤程序,将会添加新的规则。如果垃圾邮件制造者随后又用新的词汇代替“four U”,传统的垃圾邮件过滤程序也要随后添加新的规则,如此反复。基于机器学习的垃圾邮件过滤技术就显得很灵活了,因为它能自动调整垃圾邮件的特征:如果他发现用户经常把含有four U的邮件标记为垃圾邮件,下一次无需人工干预的情况下他会自动的把含有four U的邮件标记为垃圾邮件。
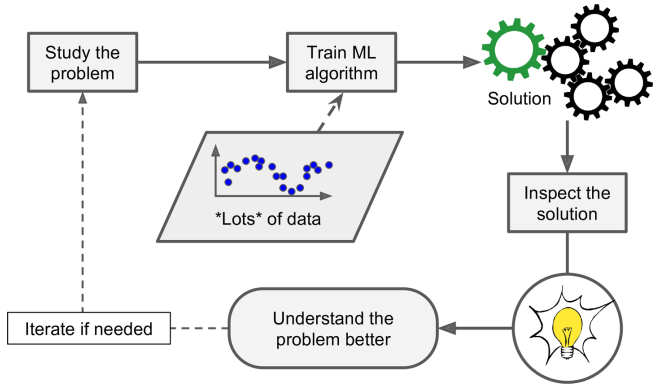
总结一下,机器学习适用于处理一下问题:
现有的解决方案需要大量手工调整或长规则列表的问题:一种机器学习算法通常可以简化代码并且执行得更好。
- 使用传统的方法根本没有好的解决方案:最好的机器学习算法可以找到一个解决方案。
- 变化不定的环境:机器学习系统可以适应新的数据
- 能够从复杂的问题和海量的数据中挖掘出隐含的知识和规律
作者:鱼果
本文地址:http://www.cnblogs.com/fingerling/p/8287966.html
欢迎转载,请在明显位置给出出处及链接。
