

目录
何为通用新闻采阅系统?
通用新闻采阅系统按名字解释为“通用的新闻采集阅读系统”。笔者在北京邮电大学做本科毕业设计的时候曾经参与到徐蔚然、陈光老师的搜索项目组中,负责网页模板制作工作。在工作中深感这种模板制作工作的繁重,乏味与无趣(一个门户网站如腾讯:就要针对不同的版面设计不同的模板),同时在模板制作中发现目前主流新闻网站如腾讯,凤凰,人民,新浪,网易,南方报业等,能够总结出一些共性的规律:例如二级索引页面中的新闻地址列表要么放在若干个div中,要么放在若干的ul ,li,table中,或者是放在一些其他的特定HTML元素中。新闻正文页亦有如此特征。如果能充分利用些特征,那么就有希望制作出通用的新闻采集系统,把人们从繁重的“制作带爬取网页模板”的体力劳动中解放出来。
1.什么是索引页面
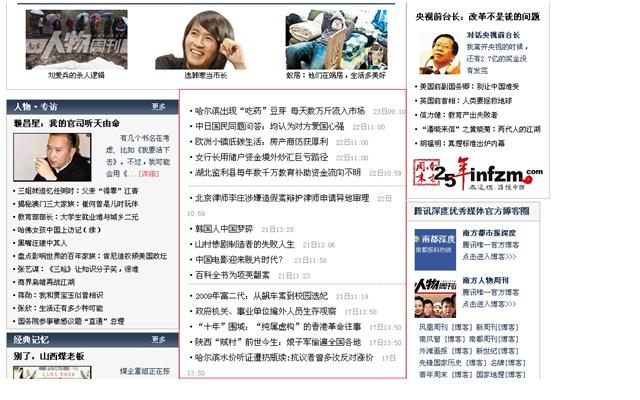
2.正文页面
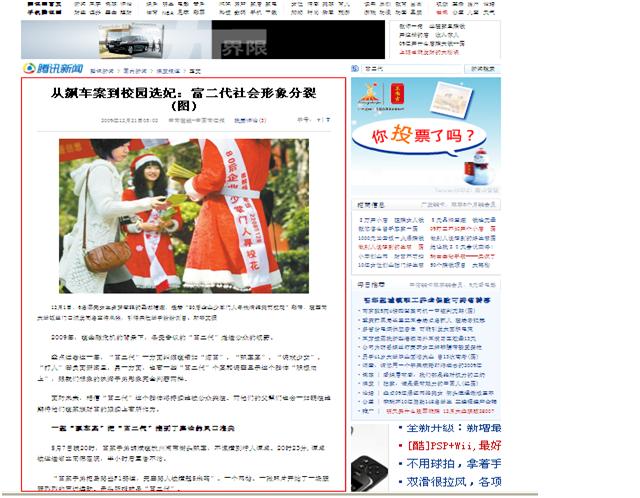
其中红色框出部分为我们要抽取的目标区域

 浙公网安备 33010602011771号
浙公网安备 33010602011771号