
python实现简易数据库之二——单表查询和top N实现
上一篇中,介绍了我们的存储和索引建立过程,这篇将介绍SQL查询、单表查询和TOPN实现。
一、SQL解析
正规的sql解析是用语法分析器,但是我找了好久,只知道可以用YACC、BISON等,sqlite使用的lemon,捣整了一天没实现,就用了python的正则表达式。
1、删除无用的空格、跳格符、换行符等;
我们以分号‘;’作为一个sql语句的结束符,在输入分号之前,我们将输入的sql语句串接成一个string,在将整个sql语句的一些无用的字符删掉,
1 def rmNoUseChar(sql): 2 while sql.find("'") != -1:#将引号删除,不论什么类型都当字符类型处理 3 sql = sql.replace("'","") 4 while sql.find('"') != -1: 5 sql = sql.replace('"','') 6 while sql.find('\t') != -1:#删除制表符 7 sql = sql.replace("\t"," ") 8 while sql.find('\n') != -1:#删除换行符 9 sql = sql.replace("\n"," ") 10 statements = sql.split(" ")#分割成列表,删除多余空格后在拼接成字符串 11 while "" in statements: 12 statements.remove("") 13 sql="" 14 for stmt in statements: 15 sql += stmt+ " " 16 return sql[0:-1]#最后一个空格删掉
2、关键词大写;
在sql语句中扫描关键字,将关键字大写。这里我们使用了一个技巧,在每个select语句前面多加一个空格,每个关键字前后都加一个空格,这样可以替换单词的部分,如果不加空格,像charity 就会被替换为CHARrity,这不是我们想要的。
oneKeywords = [" SELECT "," FROM "," WHERE ", " DESC "," ASC ", " DATE "," DAY "," INT "," CHAR "," VARCHAR "," DECIMAL ", " SUM "," AVG ","MAX","MIN"," COUNT "," AS "," TOP "," AND "," OR "] twoKeywords = [" GROUP BY "," ORDER BY "]
3、解析和格式化SELECT子语句;
一个常见的select语句一般包含select、from、where、group by、order by五部分(不考虑嵌套查询),where、group by、order by可以不出现,但如果出现的,在sql语句中必定满足select、from、where、group by、order by的顺序,因此我们定义:
stmtTag = ["SELECT","FROM","WHERE","GROUP BY","ORDER BY",";"]#select 子语句标志词
找到各个子语句的标志词,根据标志词来解析子语句,这里我们定义了一个方法,用来找下一个标志词:
def nextStmtTag(sql,currentTag):#根据当前标志词找下一个标志词 index = sql.find(currentTag,0) for tag in stmtTag: if sql.find(tag,index+len(currentTag)) != -1: return tag
比如我们测试发现sql语句中有WHERE标志词,那么它一定有where子句,我们通过nextStmtTag()方法得到下一个关键词,如果sql中有GROUP BY, 则下一个标志词就是GROUP BY,如果没有GROUP BY而有ORDER BY,那下一个标志词就是ORDER BY,否则下一个标志词就是分号";",因为一个sql中一定有结束符分号。
4、结合元数据表检查语法错误;
解析完sql的子语句后,我们就可以进行简单的语法检查,结合元数据检查WHERE子句的表是否在数据库中存在,以及其他子语句中的属性是否在WHERE子句的表中,检查的过程中,顺便将属性大写,并将的表名添上,属性的格式统一为:[表名].[属性名],同时对多表查询的where条件做优化,即将单表查询条件放在列表的前面,多表连接放在后面。具体请看下面的例子:
我们输入如下sql语句:
select l_orderkey,o_orderdate,o_shippriority, min(l_orderkey) as min_odkey, max(o_shippriority) as max_priority from customer,orders,lineitem where c_mktsegment = "MACHINERY" and c_custkey = o_custkey and l_orderkey = o_orderkey and o_orderdate < "1995-05-20" and l_shipdate > "1995-05-18" group by l_orderkey,o_orderdate,o_shippriority order by o_orderdate desc,o_orderdate;
解析的结果(已通过语法检查):
{'FROM': ['CUSTOMER', 'ORDERS', 'LINEITEM'],
'GROUP': ['LINEITEM.L_ORDERKEY',
'ORDERS.O_ORDERDATE',
'ORDERS.O_SHIPPRIORITY'],
'ORDER': [['ORDERS.O_ORDERDATE', 'DESC'], ['ORDERS.O_ORDERDATE', 'ASC']],
'SELECT': [['LINEITEM.L_ORDERKEY', None, None],
['ORDERS.O_ORDERDATE', None, None],
['ORDERS.O_SHIPPRIORITY', None, None],
['LINEITEM.L_ORDERKEY', 'MIN', 'min_odkey'],
['ORDERS.O_SHIPPRIORITY', 'MAX', 'max_priority']],
'WHERE': [['CUSTOMER.C_MKTSEGMENT', '=', 'MACHINERY'],
['ORDERS.O_ORDERDATE', '<', '1995-05-20'],
['LINEITEM.L_SHIPDATE', '>', '1995-05-18'],
['CUSTOMER.C_CUSTKEY', '=', 'ORDERS.O_CUSTKEY'],
['LINEITEM.L_ORDERKEY', '=', 'ORDERS.O_ORDERKEY']]}
可以看到我们将整个sql解析成一个字典,字典的键是子语句标志词,值是格式化的子语句,这个解析结果跟JSON格式差不多。对于group by和from子语句只是简单的表名和属性名,因此就使用一个list表示,而其他子语句比较复杂,我们对其子语句的每个部分用list表示,如order子语句,不光有属性还有升序或降序描述;而select还有聚集函数和重命名;where子句我们只考虑大于、等于和小于的条件,即每个where条件可以用过一个三元组表示。不出现的部分我们用None补齐。
这就是我们的解析select sql的大体过程,细节不再介绍,因为这个解析方法实在不高明,上不了台面,正规军都是用的句法和语法解析器,我们打游击战的。
二、单表查询
上一篇,我们将存储结构和索引建立好了,现在sql解析部分也已经完成了,接下来我们来实现一个简单的单表查询。
1、一个简单的示例
先来看一个简单示例,我们输入的查询如下:
select O_CUSTKEY from ORDERS where o_orderdate= '1995-02-08';
在orders表中查找o_orderdate= '1995-02-08'的记录的o_custkey属性值。先来看查询结果:
Input SQL: select O_CUSTKEY from ORDERS where o_orderdate= '1995-02-08'; {'FROM': ['ORDERS'], 'GROUP': None, 'ORDER': None, 'SELECT': [['ORDERS.O_CUSTKEY', None, None]], 'WHERE': [['ORDERS.O_ORDERDATE', '=', '1995-02-08']]} Quering: ORDERS.O_ORDERDATE = 1995-02-08 The result hava 669 rows, here is the fisrt 10 rows: ------------------- rows ORDERS.O_CUSTKEY ------------------- 1 72703 2 65566 3 81263 4 65561 5 127322 6 16642 7 38953 8 82663 9 14543 10 21053 ------------------- Take 0.388 seconds.
从查询结果中我们可以看到,ORDERS.O_ORDERDATE = 1995-02-08的记录有669条,为了方便,我们将查询结果写了文件保存,这里只显示10条结果,orders表共有150万条记录,这个等值查询只有用了0.388秒,速度算比较快了。下面详细介绍这个查询的实现过程。
2、单表查询详解
单表查询的流程图如下:
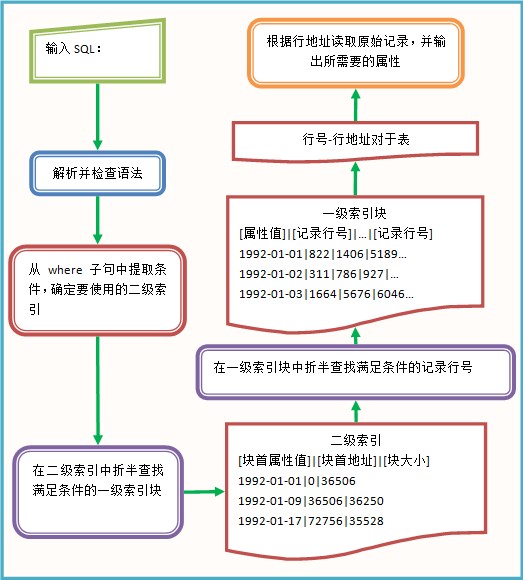
当我们输入完sql语句后,先解析并进行语法检查,解析的结果我们打印出来了,在上面的示例中可以看到。解析并通过语法检查后,开始执行sql。很明显,执行的第一步是从where子句中开始,where子句只有一个条件:o_orderdate= '1995-02-08',于是我们去查找ORDERS的O_ORDERDATE的二级索引,二级索引是建立在一级索引块上的索引,二级索引文件通常很小,只有几十KB,我们可以把它放入内存,进行折半查找,折半查找速度相当快,对100万长度的表查找最多只需要20次,关于折半查找可以参看非等值折半查找。
在二级索引中查找到满足条件的块后,将一级索引块读入内存,一块的大小通常不大(后面会讨论),可以在内存中进行折半查找,找到满足属性条件的记录行。然后将行号转换为行地址,就可以直接读取原始记录,选择需要的属性输出,选择输出属性需要结合元数据表确定属性所在的列。看下图,一目了然:

上面的示例是等值查询o_orderdate= '1995-02-08',对于小于或大于查询,处理方法稍微麻烦一些,比如我们查询o_orderdate< '1995-02-08',也是先找到o_orderdate= '1995-02-08'所在的块,在块内找到满足条件的行(上图中的02-01--02-07),同时将前面的块全部读取,提取出行号;大于查询也是类似的处理。
得到行地址后读取原始记录是很简单的:
for recordLoc in satisLoc: tableFile.seek(int(recordLoc))#定位到行首 record = tableFile.readline().split("|")
读取原记录时,先定位再读取一整行。tableFile.seek(loc)移动文件指针,而我们的loc没有排序,所以会造成文件指针抖动,比如我们先tableFile.seek(0),定位到文件开始,下一次tableFile. seek(20000),接着tableFile.seek(10),这样磁盘定位会比较花时间。读记录前将行满足条件首地址集合排序,可以实现顺序读取,读取记录速度可以增加,但排序也是会花很长时间的,这两者需要折中(我们的实现中没有排序,因为我们发现排序话费的时间比乱序读取话费的时间更多)。
另外注意在二级索引和一级索引中折半查找是不同的,因为二级索引是稀疏索引,并不包含所有的属性值,即使找不到等值的条件也需要返回一个可能包含该记录的块,除非是要比较的值比第一个块的第一个块首属性值都小,此时可以断定原记录集中没有满足条件的记录。
细心的读者可能会发现,我们定义的块>=32KB,因此会出现有一个块很大,大到内存放不下。测试数据的orders表共有150万条记录,而其o_shippriority属性只有一个值:”0“,因此一级索引文件ORDERS_O_SHIPPRIORITY只有一行:”0|0|1|2|3|4|5|6|7|8|9|10|11|...1500000“,这一行单独成一块,这一块的大小为11MB,当然还可以放入内存,但假设orders有1500万条记录,那么单个块就是110MB,直接放入内存就不适合了,但仔细想一想,这个块中所有的行号都是属性值等于’0‘的记录,因此不需要再这个块上作折半查找,我们直接得到满足记录的行号便可以分多次读取这110MB的大块。
三、TOP N
上面我们已经实现了一个单表单条件的查询。接下来实现一个top N查询,在top N语句中必定含有order by子句,即取最大或最小的N条记录;否则top N的结果将是不确定的。最直接的方法实现top N就是先根据where记录塞选记录,然后在根据order by属性排序,排序完毕后,取前N条记录输出即可。但这样效率比较低,如果N很小,而where子句的条件又不严格,满足条件的记录很多,将会花大量的时间去读取原始记录和排序,当然也可以进行N趟冒泡排序,可以提高效率。
但我们已经建立好了顺序索引,相当于我们已经事先排序好了,TOP N必定是有更快的方法的。现在来看这样一个sql语句:
select top 10 O_ORDERKEY,O_ORDERPRIORITY,O_TOTALPRICE,o_orderdate from ORDERS where o_orderdate<'1995-02-08' order by o_totalprice;
从orders表中找1995-02-08以前总价格最低的10条记录,这里默认是升序。首先根据where条件找出1995-02-08以前的记录的行号,下一步我们不是直接读取记录并按o_totalprice排序,而是先对满足条件的行号排序,然后去扫描o_totalprice的索引,因为o_totalprice的索引已经有序了,我们从前往后依次扫描o_totalprice属性值得行号,查找每一个行号是否在满足条件的行号集合中,如果在,就添加到一个新的行号集合中,只要添加了10条记录,我们就停止扫描,这样就已经找到前10条满足条件的记录。还是看图比较容易理解:

如果是降序,则需要找出最大的前10个,那我们只需要从后往前扫描o_totalprice的索引,找到10个行号即可。
对于记录记录数为m的表,最多可能需要进行mlog(m1)次比较操作,其中m1是where子语句选出的记录个数,m1<=m,但实际情况中,需要比较的次数远远小于mlog(m1)。这样的方法可以减少I/O次数,因为满足 o_orderdate<'1995-02-08'有上10万条记录,如果直接读这10万条记录进内存并排序,显然浪费了时间,因为最终又只需要10条记录。
来看一下执行的结果:
Input SQL: select top 10 O_ORDERKEY,O_ORDERPRIORITY,O_TOTALPRICE,o_orderdate from ORDERS where o_orderdate<'1995-02-08' order by o_totalprice; Quering: ORDERS.O_ORDERDATE < 1995-02-08 ------------------------------------------------------------ rows O_ORDERKEY O_ORDERPRIORITY O_TOTALPRICE O_ORDERDATE ------------------------------------------------------------ 1 1600323 1-URGENT 866.90 1992-04-18 2 823814 1-URGENT 870.88 1992-01-31 3 5267200 3-MEDIUM 875.52 1993-11-21 4 5363650 5-LOW 877.30 1994-01-14 5 4318946 4-NOT SPECIFIED 884.82 1993-08-29 6 5195557 1-URGENT 891.74 1993-05-02 7 3309383 1-URGENT 908.18 1992-07-01 8 674436 1-URGENT 908.20 1993-08-06 9 2934784 3-MEDIUM 912.10 1992-02-23 10 5174117 2-HIGH 913.92 1993-07-30 ------------------------------------------------------------ Take 8.479 seconds.
再看一下降序的结果:
Input SQL: select top 10 O_ORDERKEY,O_ORDERPRIORITY,O_TOTALPRICE,o_orderdate from ORDERS where o_orderdate<'1995-02-08' order by o_totalprice desc; Quering: ORDERS.O_ORDERDATE < 1995-02-08 ------------------------------------------------------------ rows O_ORDERKEY O_ORDERPRIORITY O_TOTALPRICE O_ORDERDATE ------------------------------------------------------------ 1 1750466 4-NOT SPECIFIED 555285.16 1992-11-30 2 4722021 1-URGENT 544089.09 1994-04-07 3 3586919 1-URGENT 522644.48 1992-11-07 4 2185667 1-URGENT 511359.88 1992-10-08 5 4515876 4-NOT SPECIFIED 510061.60 1993-11-02 6 972901 3-MEDIUM 508668.52 1992-07-18 7 1177378 4-NOT SPECIFIED 508010.56 1992-09-19 8 631651 5-LOW 504509.06 1992-06-30 9 3883783 1-URGENT 500241.33 1993-07-28 10 3342468 3-MEDIUM 499794.58 1994-06-12 ------------------------------------------------------------ Take 11.04 seconds.
看到结果了吧,由于记录数比较多,查询的时间还是比较长,但相比而言还是比较快了。
这一篇讲述了sql的语法解析和单表查询与TOP N 查询,下一篇将讲述多表查询和group by实现,敬请关注。

