Python3.x:Selenium+PhantomJS爬取带Ajax、Js的网页及获取JS返回值
前言
现在很多网站的都大量使用JavaScript,或者使用了Ajax技术。这样在网页加载完成后,url虽然不改变但是网页的DOM元素内容却可以动态的变化。如果处理这种网页是还用requests库或者python自带的urllib库那么得到的网页内容和网页在浏览器中显示的内容是不一致的。
解决方案
使用Selenium+PhantomJS。这两个组合在一起,可以运行非常强大的爬虫,可以处理cookie,JavaScript,header以及其他你想做的任何事情。
安装第三方库
Selenium是一个强大的网络数据采集工具,最初是为网站自动化测试开发的,其有对应的Python库;
Selenium安装命令:
pip install selenium
安装PhantomJS
PhantomJS是一个基于webkit内核的无头浏览器,即没有UI界面,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作需要程序设计实现。通过编写js程序可以直接与webkit内核交互,在此之上可以结合java语言等,通过java调用js等相关操作。需要去官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:http://phantomjs.org/download.html,按照不同的系统选择相应的版本
对windows系统来说,下载PhantomJs 然后将 解压后的执行文件放在被设置过环境变量的地方,不设置的话,后续代码就要设, 所以这里直接放进来方便;

然后检测下,在cmd窗口输入phantomjs:

出现这样的画面,即表示成功;
对Mac系统来说,下载后保存到一个路径中,可以直接保存在环境变了路径中,也可以在环境变量路径中创建一个指向phantomjs的软连接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
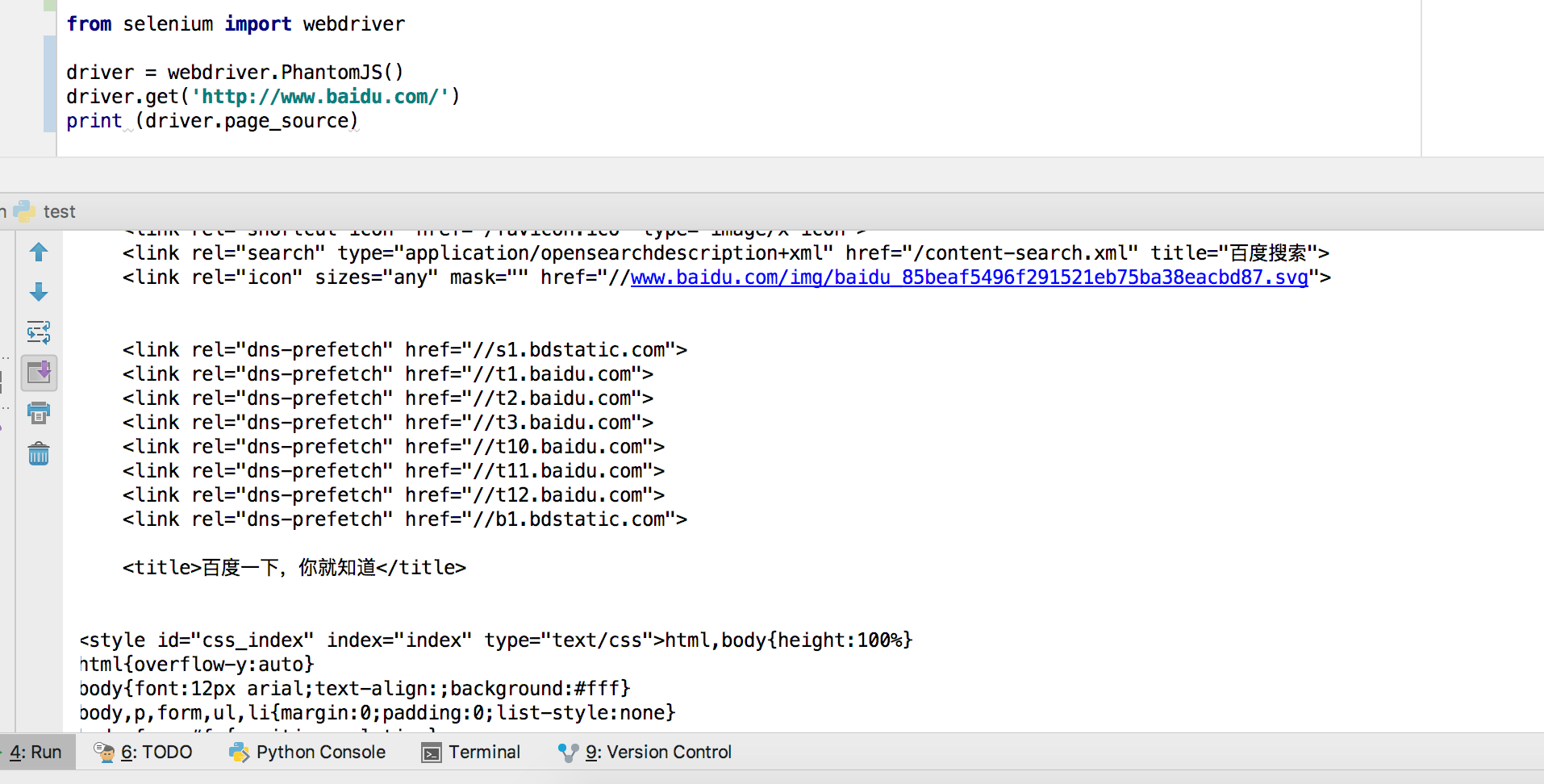
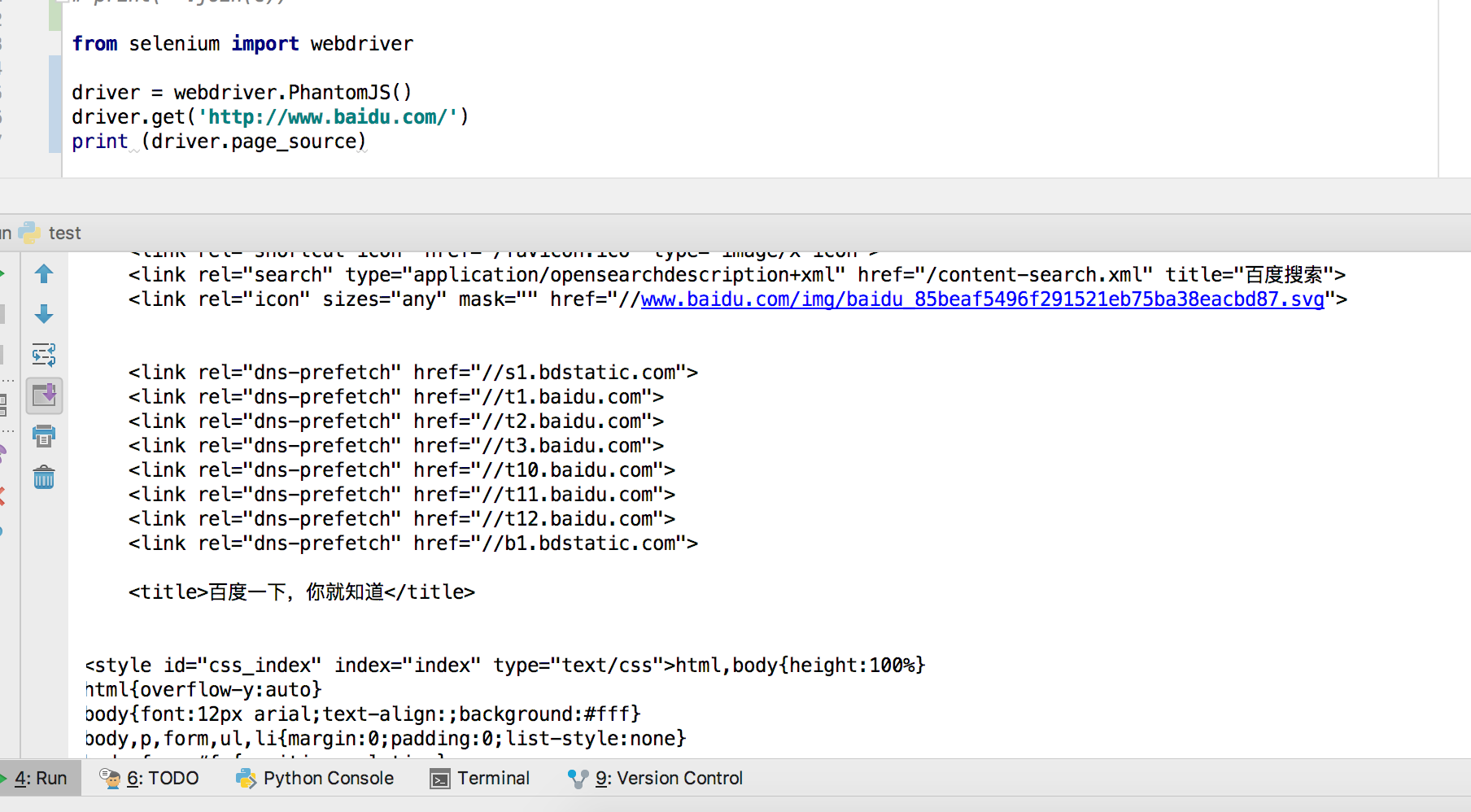
测试代码:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)
能成功获取到页面元素即为安装成功
示例一:
Selenium+PhantomJS示例代码:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()
能输出网页源码,说明安装成功
获取JS返回值