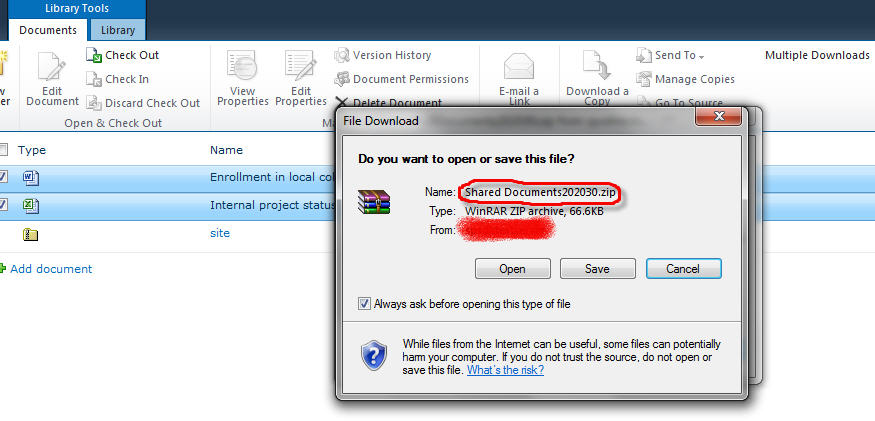
在SharePoint 2010文档库中,结合单选框,在Ribbon中提供了批量处理文档的功能,比如,批量删除、批量签出、批量签入等,但是,很遗憾,没有提供批量下载,如图:
若选中多个文档后,会发现Download a Copy这个Ribbon按钮变灰了,这几天,我自己做了一个Ribbon,实现了批量下载的功能,向大家介绍一下。
先来说一下我这个批量下载的原理:
1. Ribbon按钮。在前端有一个Ribbon按钮,我也把它安置在Copies这个group里,它的作用是取得当前的文档库ID和所有被选中的条目的ID,作为参数传给下载页,下载页是一个Application Page。
2. 获取文档库中的文档。在下载页完成,根据传递来的文档库ID和item ID, 获得对应的SPDocumentLibrary和SPFile。
3. 把存放在数据库中的文档转化为实际的文档。在下载页完成,由于文档库中的文档是以二进制存放在数据库中,因此需要转化为实际的文档,为了打包方便,在服务器创建一个单独的文件夹存放,我以文档库的名字+当前的时间来作为文件夹的名称。
4. 打包下载。在下载页完成,将对应的文件夹打包成.zip包,完成下载。
要用到的技术:
1. 自定义Ribbon。请参阅我的另一篇随笔:SharePoint 2010自定义开发Ribbon。
2. Application Page。不再赘述。
3. 压缩。我使用的开源的ICSharpCode.SharpZIPLib。
开发工具还是使用Visual Studio 2010:
通过Visual Studio 2010,可以非常方便的开发自定义Ribbon和Application Page。
分别介绍一下:
1. Ribbon。
主要来看一下这个Ribbon按钮的Command Action:
2 var c=ctx.dictSel;
3 for (var key in c)
4 {
5 ids=ids+c[key].id+',';
6 };
7 if(ids!='')
8 {
9 url=ctx.HttpRoot+'/_layouts/downloads/download.aspx?listid='+ctx.listName+';'+ids;
10 window.open(url);
11 }
12
其中,ctx为current context,类似于我们在后台使用SPContext,在SharePoint 2010页面中都会有这个context,它是一个ContextInfo对象,在一个页面的源文件中,可以看到
ctx = new ContextInfo();
var existingHash = '';
if(window.location.href.indexOf("#") > -1)
{ existingHash = window.location.href.substr(window.location.href.indexOf("#"));
}
ctx.existingServerFilterHash = existingHash;
if (ctx.existingServerFilterHash.indexOf("ServerFilter=") == 1)
{ ctx.existingServerFilterHash = ctx.existingServerFilterHash.replace(/-/g, '&').replace(/&&/g, '-'); var serverFilterRootFolder = GetUrlKeyValue("RootFolder", true,ctx.existingServerFilterHash); var currentRootFolder = GetUrlKeyValue("RootFolder", true);
if("" == serverFilterRootFolder && "" != currentRootFolder)
{ ctx.existingServerFilterHash += "&RootFolder=" + currentRootFolder; } window.location.hash = ''; window.location.search = '?' + ctx.existingServerFilterHash.substr("ServerFilter=".length + 1); }
ctx.listBaseType = 1;
ctx.NavigateForFormsPages = false;
ctx.listTemplate = "101";
ctx.listName = "{E1616EE0-C898-435C-BFA8-CBC1C5D86B67}";
ctx.view = "{FCBEAC6C-FAC6-4951-A06B-9561E7C8E8EC}";
ctx.listUrlDir = "/Shared%20Documents";
ctx.HttpPath = "http://TestSite:8080/_vti_bin/owssvr.dll?CS=65001";
ctx.HttpRoot = "http://TestSite:8080";
ctx.imagesPath = "/_layouts/images/"; ctx.PortalUrl = ""; ctx.SendToLocationName = ""; ctx.SendToLocationUrl = ""; ctx.RecycleBinEnabled = 1; ctx.OfficialFileName = ""; ctx.OfficialFileNames = ""; ctx.WriteSecurity = "1"; ctx.SiteTitle = "KevinTest"; ctx.ListTitle = "Shared Documents"; if (ctx.PortalUrl == "") ctx.PortalUrl = null; ctx.displayFormUrl = "http://TestSite:8080/_layouts/listform.aspx?PageType=4&ListId={E1616EE0-C898-435C-BFA8-CBC1C5D86B67}"; ctx.editFormUrl = "http://TestSite:8080/_layouts/listform.aspx?PageType=6&ListId={E1616EE0-C898-435C-BFA8-CBC1C5D86B67}"; ctx.isWebEditorPreview = 0; ctx.ctxId = 59; ctx.isXslView = true; if (g_ViewIdToViewCounterMap["{FCBEAC6C-FAC6-4951-A06B-9561E7C8E8EC}"] == null) g_ViewIdToViewCounterMap["{FCBEAC6C-FAC6-4951-A06B-9561E7C8E8EC}"]= 59; ctx.CurrentUserId = 1; ctx.ContentTypesEnabled = true; ctx59 = ctx; g_ctxDict['ctx59'] = ctx;
</script>
2. 下载页。
很好理解,直接看代码吧。
2 using Microsoft.SharePoint;
3 using Microsoft.SharePoint.WebControls;
4 using System.Web;
5 using System.IO;
6 using System.Diagnostics;
7
8 using ICSharpCode.SharpZipLib.Zip;
9 using ICSharpCode.SharpZipLib.Core;
10
11
12 namespace ProjectFor8080.Layouts.Downloads
13 {
14 public partial class Download : LayoutsPageBase
15 {
16 protected void Page_Load(object sender, EventArgs e)
17 {
18 if (!string.IsNullOrEmpty(Request.Params["listid"]))
19 {
20 SPContext context = SPContext.Current;
21
22 SPWeb web = context.Web;
23
24 string folder = @"C:\Program Files\Common Files\Microsoft Shared\Web Server Extensions\14\template\LAYOUTS\Downloads\Files\";
25
26 string listid = Request.Params["listid"];
27 string[] downloadParams=listid.Split(';');
28 string[] fileIds = downloadParams[1].Split(',');
29
30 Guid listGuid=new Guid(downloadParams[0]);
31
32 SPDocumentLibrary sdl = web.Lists[listGuid] as SPDocumentLibrary;
33
34 //create the files folder under Downloads\Files
35 string time = DateTime.Now.ToString("yyyy_MM_dd_HH_mm_ss_fff");
36
37 string folderPath = folder + sdl.Title + time;
38
39 Directory.CreateDirectory(folderPath);
40
41 //download the files from library
42 for(int i=0;i<fileIds.Length-1;i++)
43 {
44 SPFile file = sdl.GetItemById(Int32.Parse(fileIds[i])).File;
45 string path = folderPath+@"\"+ file.Name;
46 FileStream fs = new FileStream(path, FileMode.OpenOrCreate);
47 byte[] fileByte = file.OpenBinary();
48 fs.Write(fileByte, 0, fileByte.Length);
49 fs.Flush();
50 fs.Close();
51
52 }
53
54 //zip file
55
56 string zipName = sdl.Title+time+".zip";
57 string zipPath=folder+zipName;
58 CreateZipFile(folderPath, zipPath);
59 string downloadUrl = context.Site.Url + @"/_layouts/downloads/files/" + zipName;
60
61 Response.Redirect(downloadUrl);
62 }
63 else
64 return;
65 }
66 private static void CreateZipFile(string filesPath, string zipFilePath)
67 {
68 try
69 {
70 string[] filenames = Directory.GetFiles(filesPath);
71
72 using (ZipOutputStream s = new ZipOutputStream(File.Create(zipFilePath)))
73 {
74 s.SetLevel(9); // 压缩级别 0-9
75
76 //s.Password = "123"; //Zip压缩文件密码
77
78 byte[] buffer = new byte[4096]; //缓冲区大小
79
80 foreach (string file in filenames)
81 {
82 ZipEntry entry = new ZipEntry(Path.GetFileName(file));
83
84 entry.DateTime = DateTime.Now;
85
86 s.PutNextEntry(entry);
87
88 using (FileStream fs = File.OpenRead(file))
89 {
90 int sourceBytes;
91 do
92 {
93 sourceBytes = fs.Read(buffer, 0, buffer.Length);
94 s.Write(buffer, 0, sourceBytes);
95 } while (sourceBytes > 0);
96 }
97 }
98 s.Finish();
99 s.Close();
100 }
101 }
102 catch (Exception ex)
103 {
104 HttpContext.Current.Response.Write(ex.Message);
105 }
106 }
107 }
108 }
109
运行效果:
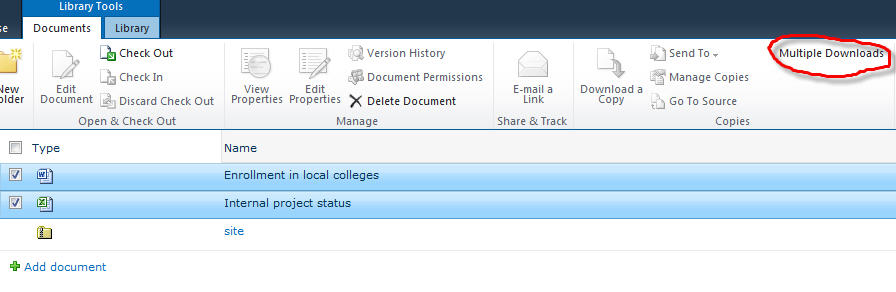
选中文档,点击“Multiple Downloads”后,直接弹出IE的下载对话框: