django之基本配置
Python的WEB框架有Django、Tornado、Flask 等多种,Django相较与其他WEB框架其优势为:大而全,框架本身集成了ORM、模型绑定、模板引擎、缓存、Session等诸多功能。
零、安装
pip install django
一、创建django程序
- 终端命令:django-admin startproject sitename
- IDE创建Django程序时,本质上都是自动执行上述命令
其他常用命令:
python manage.py runserver 0.0.0.0 # 开始程序
python manage.py startapp appname # 程序内部增加新app
python manage.py syncdb
python manage.py makemigrations # 确认最新models的配置,如果与上一记录版本有出入,则生成新一版记录,与下面的migrate配对使用
python manage.py migrate # 根据信一半记录,修改数据库
python manage.py createsuperuser # 创建admin用户
启动程序
# dev python manager.py startapp 0.0.0.0:8000 # master gunicorn -w 4 xxadmin.wsgi # 4是cpu核数 # 下面是根据dev和master环境更改settings.py文件 wsgi.py os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'xxadmin.prod') manager.py os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'xxadmin.dev') # settings.py里的STATIC相关部分改成这样 STATIC_URL = '/static/' if DEBUG: STATICFILES_DIRS = (os.path.join(BASE_DIR, 'static'),) else: STATIC_ROOT = os.path.join(BASE_DIR, "static") # 对应的url改成这样 if not settings.DEBUG: # 这里没必要,如果是prod环境,则需要在nginx做指向,这里临时这样写 urlpatterns += re_path(r'^static/(?P<path>.*)$', static.serve, {'document_root': settings.STATIC_ROOT}, name='static'),
# dev环境由于STATICFILES_DIRS,不用上面这一步
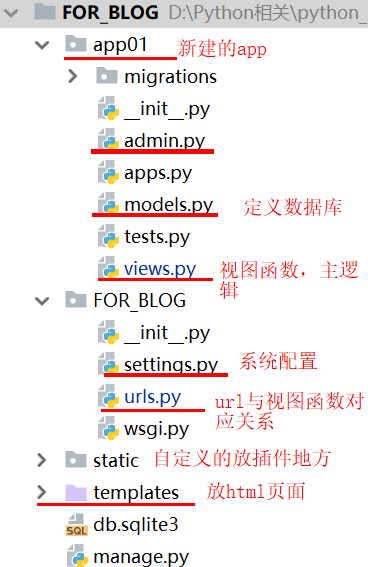
二、程序目录
三、配置文件
1.数据库
############### settings.py ############### # 使用sqllite,django默认 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } # 使用mysql ******* DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME':'dbname', 'USER': 'root', 'PASSWORD': 'xxx', 'HOST': '', 'PORT': '', } } ############### __init__.py ############### # 由于Django内部连接MySQL时使用的是MySQLdb模块,而python3中还无此模块,所以需要使用pymysql来代替 # 如下设置放置的与project同名的配置的 __init__.py文件中 import pymysql pymysql.install_as_MySQLdb()
2.模版
############### settings.py ############### TEMPLATE_DIRS = ( os.path.join(BASE_DIR,'templates'), )
3.静态文件(自定义放置插件的路径)
STATICFILES_DIRS = ( os.path.join(BASE_DIR,'static'), )
4.新增app
################# settings ############### INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'app01.apps.App01Config', # 注册app ]
四、直接执行某script
# -*- coding:utf-8 -*- import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "tmp_dj.settings") # NoQA import django django.setup() # NoQA if __name__ == '__main__': ''' 这里可以写django的逻辑,不需要侦听web端口了 '''


# -*- coding:utf-8 -*- import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "tmp_dj.settings") # NoQA import django django.setup() # NoQA if __name__ == '__main__': from taiyingshi import models import json from django.db import transaction from utils import logger import re import time error_log = logger.logger("error") dir = r"D:\临时\爬虫\scrapy\taiyingshi" dir_walk = os.walk(dir) def get_duration(t): if not t: return 0 h = re.findall("(\d+)小时", t) h = 0 if not h else h[0] M = re.findall("(\d+)分钟", t) M = 0 if not M else M[0] return int(h) * 60 + int(M) file_name_list = next(dir_walk)[2] # print(len(file_name_list)) # 49666 movie_obj_list = models.Movie.objects.all() movie_url_set = set(map(lambda obj:obj.url,movie_obj_list)) for idx,file_name in enumerate(file_name_list): file_path = os.path.join(dir, file_name) with open(file_path) as f: movie_dict = json.load(f) print(idx, movie_dict.get("movie_name")) if movie_dict["movie_url"] not in movie_url_set: try: release_time = movie_dict.get("movie_year") try: release_time = time.strftime("%Y-%m-%d", time.strptime(release_time, "%Y")) except: release_time = None context = { "name": movie_dict.get("movie_name"), "url": movie_dict.get("movie_url"), "release_time": release_time, # 直接格式化即可,这里顺便复习一下time模块 "length": get_duration(movie_dict.get("movie_length")), "rate_douban": movie_dict.get("movie_rate_douban") or None, "douban_link": movie_dict.get("movie_douban_link"), "rate_imdb": movie_dict.get("movie_rate_imdb") or None, "imdb_link": movie_dict.get("movie_imdb_link"), "download_links": "\n".join(movie_dict.get("movie_download_list")), } with transaction.atomic(): district = movie_dict.get("movie_district") district_obj = models.District.objects.filter(district=district).first() if not district_obj: district_obj = models.District.objects.create(district=district) movie_obj = models.Movie.objects.create(district=district_obj, **context) # 从爬虫发过来的type set movie_type_set = set(movie_dict.get("movie_type_list")) # db里所有的type objs movie_type_obj_list = models.Movie_type.objects.all() # 转为set movie_type_in_db_set = set(map(lambda obj: obj.movie_type, movie_type_obj_list)) # 需要新增的type movie_type_to_db_set = movie_type_set - movie_type_in_db_set # 增加新的type if movie_type_to_db_set: models.Movie_type.objects.bulk_create( [models.Movie_type(movie_type=movie_type) for movie_type in movie_type_to_db_set]) # 增加m2m关系 if movie_type_set: objs = models.Movie_type.objects.filter(movie_type__in=movie_type_set).all() movie_obj.movie_types.add(*objs) # 没有手动增加的第三张表才能使用这样的添加方法 # 从爬虫发过来的language set language_set = set(movie_dict.get("movie_language_list")) # db里所有的language objs language_obj_list = models.Languages.objects.all() # 转为set language_in_db_set = set(map(lambda obj: obj.language, language_obj_list)) # 需要新增的language language_to_db_set = language_set - language_in_db_set # 增加新的language if language_to_db_set: models.Languages.objects.bulk_create( [models.Languages(language=language) for language in language_to_db_set] ) # 增加m2m关系 if language_set: language_objs = models.Languages.objects.filter(language__in=language_set).all() models.Movie_m2m_Language.objects.bulk_create( [models.Movie_m2m_Language(movie=movie_obj, language=language_obj) for language_obj in language_objs]) # 从爬虫发过来的actor set actor_set = set(movie_dict.get("movie_actor_list")) # db里所有的actor objs actor_obj_list = models.Actors.objects.all() # 转为set actor_in_db_set = set(map(lambda obj: obj.name, actor_obj_list)) # 需要新增的actor actor_to_db_set = actor_set - actor_in_db_set # 增加新的actor if actor_to_db_set: models.Actors.objects.bulk_create( [models.Actors(name=actor) for actor in actor_to_db_set]) # 增加m2m关系 if actor_set: actor_objs = models.Actors.objects.filter(name__in=actor_set).all() models.Movie_m2m_Actor.objects.bulk_create( [models.Movie_m2m_Actor(movie=movie_obj, actor=actor_obj) for actor_obj in actor_objs] ) # 从爬虫发过来的director set director_set = set(movie_dict.get("movie_director_list")) # db里所有的director objs director_obj_list = models.Directors.objects.all() # 转为set director_in_db_set = set(map(lambda obj: obj.name, director_obj_list)) # 需要新增的director director_to_db_set = director_set - director_in_db_set # 增加新的director if director_to_db_set: models.Directors.objects.bulk_create( [models.Directors(name=director) for director in director_to_db_set]) # 增加m2m关系 if director_set: director_objs = models.Directors.objects.filter(name__in=director_set).all() models.Movie_m2m_Director.objects.bulk_create( [models.Movie_m2m_Director(movie=movie_obj, director=director_obj) for director_obj in director_objs]) movie_url_set.add(movie_dict["movie_url"]) except Exception as e: error_log.error("{} {}".format(movie_dict["movie_url"],str(e)))
依赖库
sudo apt-get install python3-dev libmysqlclient-dev
