httpd三种MPM的原理剖析
apache httpd系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
本文专讲httpd MPM。为了更完整、权威,我先把apache httpd 2.4关于prefork、worker和event的官方手册大致翻译了一遍,也就是本文的前3节。水平有限,难免翻译的"鬼才看得懂",还请见谅。不过在此之后,我专门拿出一节(第4节)对3种MPM做总结分析,比较通俗易懂,在看翻译有疑惑时,可以参照这一节对应的内容,我想我描述的应该比较清晰,也已经非常详细了。本来还想把MPM相关的通用性指令翻译一遍,但发现写完前面4节,篇幅已经很大了,所以,偷个懒算了。
注:内容有些多,如有错误,盼请指出。
1. prefork模式
1.1 概述
这种MPM实现了一种非线程、预先fork好服务进程(即主httpd进程外的所有派生httpd进程)的web服务。每个服务进程都可以响应流入的请求、而父进程负责维护服务进程池中服务进程的数量。对于隔离每个请求以避免单个请求出问题时殃及池鱼来说,prefork是最佳的MPM。
prefork有很强的自我调节能力,几乎不用调整它的配置指令就可以很好地工作。最重要的指令是MaxRequestWorkers,要尽量将其设置大一些,以便能处理大量的并发请求,但不能设置的太大,因为要确保能剩余足够多的物理内存供其它进程使用。
1.2 prefork工作机制
一个单独的控制进程(主httpd进程)负责产生用于监听和处理连接的子进程,并控制这些子进程的存活周期。httpd主进程总是尝试保留一些备用或空闲的服务进程,以便能够随时处理新流入的请求。这种方式下,客户端在得到服务前就不用等待httpd fork一个新的子进程。
指令StartServers, MinSpareServers, MaxSpareServers和MaxRequestWorkers调节了父进程如何创建服务子进程。通常情况下,主httpd进程有很好的自我调节能力,绝大多数站点没有必要去调整这些指令的默认值。对于要处理大于256个并发请求的站点来说,可能需要增大MaxRequestWorkers指令的值,但如果没有足够的内存,应该减小MaxRequestWorker指令的值以保证不使用swap分区而降低整体的性能。
在Unix系统中,父进程通常以root身份运行以便绑定特权80端口,而主httpd的子进程通常以一个低特权的用户运行。User和Group指令可以设置子进程的身份权限。运行子进程的用户必须要对它所服务的内容有读权限,但对服务内容之外的其他资源应该尽可能少地拥有权限。
MaxConnectionsPerChild指令用于控制杀死旧子进程和生成新子进程的频率。
1.3 prefork相关指令
-
MaxSpareServers
默认为10。
该指令设置期望的最大空闲子进程数。空闲子进程指的是当前没有在处理任何请求。如果空闲子进程数比该指令指定的数量还多,则父进程会杀掉多余的子进程。
只有在非常繁忙的站点上才有必要调整该指令的值。强烈建议不要将该指令的值设置交大。如果尝试设置该值小于或等于MinSpareServer的值,主httpd进程将自动调整该指令的值为MinSpareServers+1。 -
MinSpareServers
默认值为5。
该指令设置期望的最小空闲子进程数。空闲子进程指的是当前没有在处理任何请求。如果空闲子进程数少于该指令指定的值,则父进程会新创建子进程补足缺少的空闲子进程。此时创建空闲子进程的方式:派生一个子进程,等一秒,派生两个子进程,等一秒,派生4个子进程,依次下去最多到每秒32个子进程,并强制停止派生。
只有在非常繁忙的站点上才有必要调整该指令的值。强烈建议不要将该指令的值设置较大。
2. worker模式
2.1 概述
这种MPM实现了一种多进程、多线程混合的web服务。相比使用进程来处理请求,使用线程处理请求可以使用更少的系统资源处理更多的请求。但是,它也使用了多个进程(每个进程下有很多线程),以更多地获得基于进程处理方式的稳定性。
该MPM最重要的指令是ThreadsPerChild和MaxRequestWorkers,前者控制了每个子进程展开的线程数量,后者控制了最大总线程数量。
2.2 worker工作机制
一个单独的控制进程(父进程)负责产生子进程。每个子进程创建固定数量的服务线程,数量由ThreadsPerChild指令设置,同时还会额外创建一个监听线程,负责监听请求并在它们到达的时候将它们交给服务线程来处理。(即N个服务线程+1个监听线程。)
apache http服务总是尝试保留一些备用或空闲的服务线程池,以便可以随时处理流入的请求。这种情况下,客户端在它们的请求被处理前无需等待产生新线程。初始化时产生的进程数由指令StartServers指定。在操作期间,父进程会评估所有子进程中所有空闲线程的总数,还会新建或杀死子进程使得空闲进程总数在MinSpareThreads和MaxSpareThreads指定的边界值内。由于进程的自我调节能力很好,很少需要修改该指令的默认值。能处理的最大客户端并发数(如所有进程中的所有线程数)由MaxRequestWorkers指令决定。激活的最大子进程数计算方式为:MaxRequestWorkers/ThreadsPerChild。
有两个指令可以硬限制激活的子进程数和每个子进程中的服务线程数,硬限制的数量只能通过完全关闭http server再启动它来改变。ServerLimit指令硬限制激活的子进程数,它必须大于或等于MaxRequesetWorkers/ThreadsPerChild。ThreadLimit指令硬限制每个子进程中的服务线程数,必须大于或等于ThreadsPerChild的值。
除了激活的子进程之外,可能还有其他的正在被中断的子进程,这种子进程中可能还至少有一个服务线程正在处理请求。所以,可能在线程总数达到了MaxRequestWorkers的数量时,仍存在正被中断的子进程。可以通过下面的方式禁止某个单独的子进程终止行为:
- 设置MaxConnectionsPerChild值为0。
- 设置MaxSpareThreads的值等于MaxRequestWorkers的值。
一个典型的worker MPM进程-线程的配置大致如下:
ServerLimit 16
StartServers 2
MaxRequestWorkers 150
MinSpareThreads 25
MaxSpareThreads 75
ThreadsPerChild 25
在Unix系统中,父进程通常以root身份运行以便绑定特权80端口,而主httpd的子进程通常以一个低特权的用户运行。User和Group指令可以设置子进程的身份权限。运行子进程的用户必须要对它所服务的内容有读权限,但对服务内容之外的其他资源应该尽可能少地拥有权限。此外,除非使用了suexec,否则这两个指令设置的权限也会被CGI脚本继承。
MaxConnectionsPerChild指令用于控制杀死旧子进程和生成新子进程的频率。
3. event模式
3.1 概述
设计event MPM旨在将工作线程(worker thread)正在处理的请求转移给监听线程(listener threads),以释放工作线程来接收新请求,从而能够并发处理更多请求。
要使用event MPM,需要在编译httpd的时候在configure的配置中加上"--with-mpm=event"。(当然,只要将它动态编译,以后可以使用LoadModule动态切换。)
3.2 和worker工作模式的关系
event工作模式是基于进程、线程混合的worker模式的。一个单独的控制进程(父进程)负责生成子进程,每个子进程创建由固定数量的服务线程,服务线程数由ThreadsPerChild指令设置,同时还创建一个监听线程,负责监听请求并在它们到达的时候将它们交给服务线程来处理。(即N个服务线程+1个监听线程。)
运行时的配置指令和worker模式的指令完全相同,除了AsyncRequestWorkerFactor指令。
3.3 event工作机制
这种MPM尝试修复http中的"长连接问题"。当客户端完成了第一次请求后,可以继续保持它的连接不被关闭,以便之后可以使用相同的套接字发送其他的请求,而且这样可以节省多次创建TCP连接带来的大量消耗。但是,传统的apache httpd会保留那个负责处理请求的子进程或线程来等待客户端随后可能发送的请求,这不免带来了它自身的缺陷:资源浪费且"占着茅坑不拉屎"。为了解决这种问题,event MPM在每个子进程中使用一个专门的监听线程,不仅负责监听套接字,还负责处理所有处于长连接状态的套接字,这些套接字都是已经被所有handler和协议过滤器(通过过滤器,可以修改请求、待响应内容)处理完毕后的套接字,它们只剩下一件事没完成:发送数据给客户端。
这种新的架构方式,利用了非阻塞套接字(non-blocking sockets)和实现现代内核特性的APR(类似于Linux的epoll),而不再使用可能会导致"惊群问题"(thundering herd problem)的mpm-accept mutex(互斥锁方式)。
注:惊群问题,从英文单词来翻译是"暴怒中的野兽问题",在计算机领域,它的意思是大量进程/线程都在等待同一个事件,当事件发生时,所有进程/线程都被唤醒,它们都想拥有这个资源,于是在讨论一段时间后,除了那个获得资源的进程/线程,其余进程/线程又再次进入睡眠,当再次发生事件,又被全部唤醒、争论、睡眠,一直重复直到所有进程/线程都获取了资源。这样的结果是进程/线程抖动极度严重,每次上下文切换都消耗极大的资源,很容易导致服务器崩溃。但如果每次只唤醒一个进程,则不会出现抖动问题),这可以避。
单个进程或线程块可以处理的总连接数由AsyncRequestWorkerFactor指令控制。
3.3.1 异步连接(Async connections)
异步连接需要一个固定的专用的工作线程。mod_status模块的status显示页中将展示一个新的异步连接列,如下:(在配置了mod_status模块时,可以使用apachectl fullstatus或在浏览器中www.example.com/server-status获取,以下是某次用ab命令测试过程中的数据)
Slot PID Stopping Connections Threads Async connections
total accepting busy idle writing keep-alive closing
0 42480 no 27 yes 25 0 1 0 1
1 42481 no 26 yes 25 0 2 0 0
2 42482 no 27 yes 25 0 0 0 2
3 42564 no 28 no 25 0 1 0 2
4 42618 no 26 yes 25 0 1 0 1
5 42651 no 27 yes 25 0 1 0 1
6 42652 no 26 yes 25 0 2 0 0
7 42709 no 26 no 24 1 1 0 1
8 42710 no 26 no 25 0 2 0 0
9 42711 no 26 yes 24 1 2 0 0
10 42712 no 27 yes 25 0 2 0 0
11 42824 no 27 yes 25 0 1 0 1
12 42825 no 26 yes 25 0 0 0 1
13 42826 no 27 yes 25 0 2 0 0
14 42827 no 28 no 25 0 1 0 3
15 42828 no 26 no 25 0 1 0 1
Sum 16 0 426 398 2 20 0 14
它有以下几个字段:
-
Writing
当工作线程发送响应数据给客户端时,可能会因为连接太慢而导致内核的TCP写缓冲区(tcp write buffer,严格地说是tcp send buffer,但httpd手册上写的是write buffer,所以就使用它了,后文可能会随机使用两种描述,看心情)填满的情况。通常这种情况下,该套接字的write()调用会返回EWOULDBLOCK或EAGAIN,只有经过一段空闲时间后才可以再次可写。持有套接字的工作线程可以卸掉这种等待任务,并将该套接字交给监听线程,之后按顺序轮询直到该套接字的事件升级(例如该套接字已经可写)时,监听线程会将该套接字分配给第一个空闲的工作线程。(这是在IO写等待的情况下把套接字交给监听线程) -
Keep-alive
相比worker MPM,event MPM对长连接的处理方式是它最本质的提高。当工作线程完成了对客户端的响应(数据已经发送结束了),它可以将套接字卸给监听线程,然后按顺序轮询等待来自操作系统的所有事件信息,例如"该套接字现在可读"。如果该客户端再次发起了新请求,监听线程将把该套接字转交给第一个空闲的工作线程。相反,如果到了KeepAliveTimeout指定的时长,该套接字将被监听线程关闭。在这种方式下,工作线程不需要负责空闲的套接字,它可以被重新利用来处理其他请求。(这是在请求结束后把空闲的套接字交给监听线程) -
Closing
某些时候,event MPM需要实现延迟关闭(lingering_close)的行为,换句话说,发一个之前的错误信息给仍在向httpd传输请求的客户端。直接发送响应并立即关闭连接是错误的行为,因为客户端(仍在尝试发送剩余的请求)在连接关闭后可以获取一个新的已RST包,使得它无法读取httpd的已经发送的错误响应信息。因此在这种情况下,httpd尝试读取剩余的请求以使得客户耗尽响应。延迟关闭的行为有时间限定,但相对来说它有足够长的时间,因此工作线程可以将其卸给监听线程。
注:关于lingering_close,在nginx中也有这个概念。它表示延迟关闭TCP连接。当客户端或服务端发生错误时,一般情况下,我们期待的是把错误信息告诉客户端,并关闭连接,且不要再建立连接。但直接关闭tcp连接会导致处理不当的问题。这要从关闭TCP连接的过程来解释。
在执行close()系统调用关闭某个tcp连接时,内核会检查tcp连接的read buffer中是否还有数据(对httpd来讲,就是保持这个tcp连接的子进程/线程是否还有没有处理的请求)。如果没有,则等待tcp的write buffer中的数据(对httpd来讲,即响应或转发数据)向客户端传输完毕,最后四次挥手关闭连接;如果有,则向客户端发送一个RST包,以便关闭TCP连接,但只要发送了RST包,tcp的write buffer中的数据就会被丢弃。
于是就存在一种特殊情况,在发送close()系统调用想要关闭tcp连接之前,如果write buffer和read buffer中都有数据,在发送RST包之后,write buffer中的数据就丢弃了(其中就包括想要响应给客户端的错误信息),也就是说客户端收不到这里面的响应数据。这种特殊的情况也不难理解,在write buffer中有数据是很正常的,因为传输响应数据给客户端占用了子进程/线程大多数时间,在read buffer中有数据也很正常,例如客户端还在源源不断地发送请求,就会导致tcp的read buffer总是非空。
解决的办法是让服务端先不要发送RST包,且不要再往tcp write buffer中添加新数据(即关闭向writer buffer的写操作)。这样一来,子进程/线程只读read buffer中的请求,但却直接忽略请求不做任何处理,而客户端请求总有发完的时候,只要不再发请求了,read buffer就可以读完变成空buffer。于此同时,write buffer中的数据也在不断地传输给客户端,最终会让客户端收到write buffer尾部的错误信息数据。当然,nginx可以设置读超时lingering_timeout,如果客户端还是不断地发请求,对服务端来说,我都不理你了,你还没完没了,那啥,只能对不起了。此外,nginx还可以设置一个写超时lingering_time,在这个超时时间内,如果write buffer中的数据还是没有传输完,也就是说客户端最终还是没有收到错误响应消息,还是对不起,因为可能网速太慢了,对服务器来说,我不能在你身上等死。至于httpd有没有设置读超时和写超时的指令,官方手册上暂时没找到,可能需要修改源码吧。
在官方的nginx中,lingering_close默认值为ON,也就是会经过上面所说的一大堆过程来延迟关闭。但是在tengine中,默认为off,也就是会直接关闭tcp连接,但这样会导致一些不合理的错误处理。
另外,套接字选项SO_LINGER和lingering_close并没有半毛钱关系,SO_LINGER只是控制close()函数默认行为的。而lingering_close则描述了一种需要特殊处理的情况。
这3种提升方式对HTTP和HTTPS连接都适用。
3.3.2 Graceful进程终止和记分牌(ScoreBoard)的使用方式
早期event MPM有一些扩展能力的瓶颈,它会报这样的错:"scoreboard is full, not at MaxRequestWorkers"(记分牌已被占满,但没有达到允许的最大并发数量)。MaxRequestWorkers限制了任意时刻可以同时处理的请求数量,也限制了允许激活的进程数(MaxRequestWorkers/ThreadsPerChild)。于此同时,记分牌中记录了所有正在运行的进程以及它们的工作线程的状态信息。如果记分牌占满了(所有的线程的状态都不是idle),但是正在处理的请求数量却没有达到MaxRequestWorkers值,意味着有某些线程阻塞了本可以处理但却排在队列中的请求。线程的大多数时间被用在了Graceful的状态,也就是说,它们为了让TCP连接安全地终止,正在等待结束他们的工作,然后释放记分牌中的槽位。有两种很常见的情况:
-
在graceful restart时。父进程向所有子进程发送信号,通知它们完成它们的工作并终止,同时它重读配置文件并派生新的子进程。如果旧的子进程仍然运行了一段时间,记分牌可能仍被它们占用,直到它们终止,记分牌中的槽位才被释放。
-
当server需要以一种让httpd杀子进程的方式来降低负载时(例如MaxSpareThreads的缘故)。这是一种非常严重的情况,因为当负载再次增高时,httpd将会重新生成新的进程。如果重复出现这种情况,进程的数量会增多很多,最终导致正要尝试被停止的进程和新创建的进程混合,使得进程管理的乱七八糟,记分牌中的信息也乱七八糟。
从httpd 2.4.24开始,event MPM可以足够智能地处理graceful终止导致的问题。有以下一系列的提升:
- 允许记分牌中的槽位扩展到ServerLimit的数量。MaxRequestWorkers和ThreadsPerChild用于限制激活的进程数,于此同时,ServerLimit会考虑正在graceful关闭的进程,以便在需要的时候能提供更多的槽位。所以实现的方式是,使用ServerLimit的值来指导httpd关于在影响系统资源之前可以容忍多少总进程数。
- 强制正在graceful stop的进程关闭长连接状态的连接。
- 在graceful stop期间,如果给定子进程中正在运行的工作线程数多于该子进程中已打开的连接数,终止这些多出的线程以便能更快地释放资源。(在新建进程时可能需要这样,因为当前线程数量会影响子进程的数量。)
- 如果记分牌已经满了,阻止在降低负载杀进程时graceful stop进程,直到旧的子进程已经全部终止了才允许graceful stop(否则当负载再次增高时,情况会更糟,如前文所述)。
最后一点所描述的行为,完全可以通过mod_status中的连接状态表中的"Slot"和"Stopping"列看出来。前者是槽位号,与PID对应,后者表示的是进程是否正在终止;
3.3.3 不足之处Limitations
对于那些已经声明自己和event不兼容的特定连接过滤器,上面所说的event的提升方式可能无法正确处理。这种情况下,event MPM将切回worker MPM,并为每个连接都保留一个工作线程(即再次将连接和线程绑定)。
一个类似的限制是,当前存在会调用输出过滤器的请求,且这个输出过滤器需要读取或修改整个响应body。如果到客户端的连接被阻塞了,但过滤器却正在处理数据,正好过滤器产生的数据又非常大以致tcp写缓冲区(tcp write buffer)无法装下,那么处理该请求的线程不会被释放,httpd会一直等待直到待发送的数据已经全部发送给客户端。
为了解决这个问题,我们考虑了下面两种途径:提供一个静态内容(例如一个CSS文件)和提供从FCGI/CGI或代理服务器检索的内容。前面的情况是可预见的,也就是说,直到到内容尾部,所有的内容对event MPM都是完全可见的:工作线程提供响应内容,并且可以向客户端传输数据直到write()返回EWOULDLOCK或EAGAIN,然后将这种需要写等待的套接字卸给监听线程。这种情况下会等待发生在这个套接字上的事件,并且在等待到事件后找合适的时机将套接字重新分配给第一个空闲的工作线程以便将剩下的数据传输完。而后面一种情况(FCGI/CGI/代理内容),event MPM无法预测响应内容的结尾,这时工作线程在控制权返回给监听线程前,它必须老老实实完成它的所有工作(包括将数据全部响应给客户端)。
3.3.4 背景资料Background material
通过在操作系统中引入新型API(如下所列),使得事件驱动模型成为可能:
- epoll (Linux)
- kqueue (BSD)
- event ports (Solaris)
在新型API引入之前,只能使用的select和poll这两种API。这些API在处理大量连接时速度很慢,在连接组(set of connections)的变化频率较高时也会很慢。新型的API允许监控更多的连接,即使在连接组变化频率较高时也能更好地工作。因此,这些新型的API使得event MPM成为可能:在有大量空闲连接时,这种模式比典型的httpd有更好的扩展能力。
这种MPM假定底层的apr_pollset的实现是线程安全的,这使得event MPM可以避免过高的锁级别以及必须唤醒监听线程以便转交长连接状态的套接字。当前仅支持KQueue和EPoll。
3.3.5 相关指令:AsyncRequestWorkerFactor
默认值为2。可设置为小数,例如1.5。
event MPM以异步方式处理连接。异步情况下,监听线程会为每个连接请求分配一个很短时间的工作线程以建立异步连接。但那些正在处理请求的工作线程则会保留对应的连接,这可能会导致一种场景:所有的工作线程都被连接绑定了,没有空闲的工作线程来迎接新的请求以建立异步连接。
event MPM会做以下两件事来解决这个问题:
- 限制每个进程允许接受的连接数量,这依赖于空闲工作线程的数量。
- 如果某个进程中的所有工作线程都在忙,将关闭长连接状态的连接,即使还没有达到长连接的超时时间。这使得那个长连接的客户端可以连接到其他进程,而这个进程中可能有空闲的线程。
该指令可以用来调整每个进程允许的连接数。只有当当前连接数(不包括正处于closing状态的连接)小于下面的表达式的值时,子进程才允许接收新连接。
ThreadsPerChild + (AsyncRequestWorkerFactor * number of idle workers)
评估所有进程可以接受的最大并发连接数:
(ThreadsPerChild + (AsyncRequestWorkerFactor * number of idle workers)) * ServerLimit
示例:
ThreadsPerChild = 10
ServerLimit = 4
AsyncRequestWorkerFactor = 2
MaxRequestWorkers = 40
idle_workers = 4 (为了方便,取所有进程中空闲线程的平均数)
max_connections = (ThreadsPerChild + (AsyncRequestWorkerFactor * idle_workers)) * ServerLimit
= (10 + (2 * 4)) * 4 = 72
当所有的工作线程都是空闲状态时,可以使用下面的表达式计算最大并发连接数:
(AsyncRequestWorkerFactor + 1) * MaxRequestWorkers
示例:
ThreadsPerChild = 10
ServerLimit = 4
MaxRequestWorkers = 40
AsyncRequestWorkerFactor = 2
如果所有进程的所有线程都是空闲时:
idle_workers = 10
我们可以用下面两种方法计算绝对最大允许的并发连接数:
max_connections = (ThreadsPerChild + (AsyncRequestWorkerFactor * idle_workers)) * ServerLimit
= (10 + (2 * 10)) * 4 = 120
max_connections = (AsyncRequestWorkerFactor + 1) * MaxRequestWorkers
= (2 + 1) * 40 = 120
调整AsyncRequestWorkerFactor需要基于各种httpd处理的流量情形,因此要改变它的默认值时需要做很多测试和数据收集(从mod_status获取)
4. httpd三种MPM工作机制总结分析
到了httpd 2.4版本,prefork模式已经算比较弱势了,特别是现在的event模式已经去掉了"该MPM正处于实验阶段"的标记。在完全支持event模式后,3种模式中无疑event模式性能最好,由于它也基于epoll,所以在并发处理能力上,和nginx的差距会缩小不少。
这样说来,似乎都不需要再用prefork、worker了?但event毕竟从长期的"实验阶段"翻身不久,谁知道有没有什么"隐疾"呢?而且,据php官方说明,当php以模块方式安装到apache httpd中时,不建议httpd使用线程的工作方式,也就是说应该使用prefork模式。当然,使用php-fpm方式管理php-cgi时就无所谓了。
4.1 web服务处理请求的过程
在分析三种MPM之前,先以worker模式对httpd从监听开始到处理请求的过程做个全局的分析。再此建议先阅读套接字和TCP连接的过程。
首先是监听过程。假设没有使用套接字重用技术(默认情况下都没有开启),那么每个子进程中的监听线程都在争抢监听同一个监听套接字。为了避免"饥饿问题",在某一个时刻,应该只能有一个监听线程监听在这个套接字上,而其他监听线程需要被阻塞,那么哪个监听线程才有资格监听在这个套接字上呢?
在说明这个问题之前,先说说httpd的监听线程和工作线程的交互。
4.1.1 监听线程和工作线程的交互
当监听线程监听到客户端发起了TCP连接请求时,它将请求接进来,并创建连接套接字放入到套接字队列中(注意,监听线程创建的这个套接字是连接套接字,和监听套接字不是同一个,监听套接字是被监听者通过select/poll或epoll来轮询的,而连接套接字是提供给工作线程用来和客户端通信的。还是那句话,如果不明白两种套接字请先阅读套接字和TCP连接的过程)。至此,监听线程就完成了一个任务,准备去监听下一个连接请求。而工作线程则在空闲时取出队列中的第一个连接套接字,在得到连接套接字时它就和客户端建立了联系,可以进行数据交互,于是开始处理客户端发送的请求。
回到监听资格的问题上。如果监听线程发现这个子进程中已经没有空闲的工作线程,那么监听线程就不应该去监听新的连接请求,因为即使接进来了也无法立即处理。如何才能不去监听呢?httpd通过accept互斥锁(accept mutex)来实现,当它发现这个子进程中还可以接受新请求时,它就会持有accept互斥锁,持有这个锁时它就可以通过类似accept()函数去接受新请求、返回连接套接字并放入套接字队列中,等待空闲的工作线程取走。于是可以得出结论:监听线程除了select/poll/epoll监控套接字,还判断子进程中空闲工作线程的数量(每当工作线程从忙转为空闲,都会通知监听线程)。
也就是说,accept mutex就是监听者的监听资格。如果多个子进程同时都有空闲工作线程,这些监听者不就又开始争抢了吗?没错,这就是前面说的"惊群问题",在event模式下,监听线程采用非阻塞IO的epoll来避免这个问题,而worker模式如何解决的我不清楚,假设通过一次唤醒一个监听线程来解决,那么结合上面所说的,监听线程和工作线程的交互方式如下图所示:
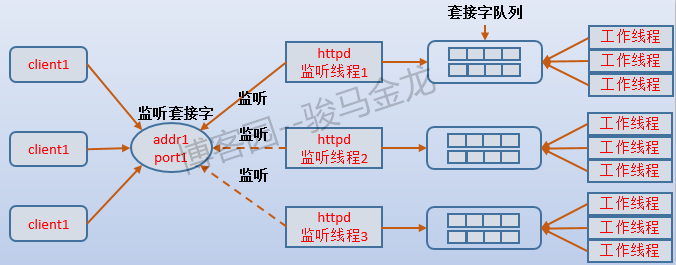
借此可以想象得到,prefork模式下,一个子进程既要负责监听又要负责工作,它的套接字队列存在与否并不重要,而且子进程的最大数量决定了某一个时刻可以处理的最大请求数量。worker模式下,每个子进程的套接字队列至少要大于或等于最大工作线程数,因为是否有空闲工作线程决定了监听线程是否可以获得accpet mutex,子进程能否接受新请求的yes/no状态也取决于该子进程是否有idle worker。对于event模式则要特殊一点,因为event模式采用epoll监控非阻塞的监听套接字,且它还维持了工作卸载给监听线程的writing、keep-alive和closing三种状态的连接,所以对监听线程判断空闲工作线程数量时,会因为接收到这3种状态的连接时而导致一些"误判"。这样可能导致的情况是,工作线程全都是busy状态,但子进程能否接受新请求的yes/no状态却为yes,连接数也大于工作线程数。
例如,下面是某次event模式的部分记分板信息。
Slot PID Stopping Connections Threads Async connections
total accepting busy idle writing keep-alive closing
0 42480 no 25 yes 25 0 1 0 0
1 42481 no 26 yes 25 0 2 0 0
2 42482 no 27 yes 25 0 3 0 2
3 42564 no 27 yes 24 1 2 0 1
4 42618 no 28 yes 25 0 3 0 1
5 42651 no 28 yes 24 1 1 0 2
其中每个子进程最大工作线程数位25,但当busy=25时,却仍显示"accepting=yes,total>25",这正是异步连接导致的。而prefork和worker都是同步连接,能否继续接受新请求,严格受限于是否有空闲工作者。(同步、异步连接和同步、异步IO模型是不同的概念)
4.1.2 工作线程获取数据的过程分析
一张图说明。
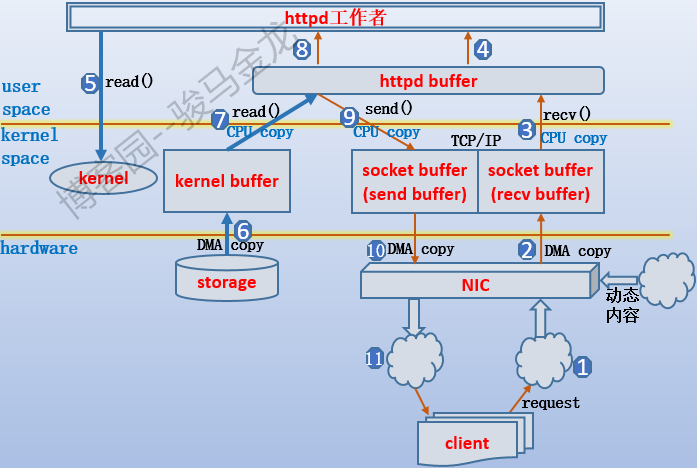
如果对IO过程熟悉,这张图也很容易理解,如果不熟悉,这张图就像天书,具体可参考网络数据传输的全过程的这一小节。下面大致描述下这张图的过程。需要说明,这张图是工作者和客户端的通信过程,和监听者的监听过程没有关系,也就是说监听者已经把连接套接字交给了工作者,假设是worker下的工作线程。
首先客户端发送http请求,通过网卡将请求数据传输到TCP的recv buffer中,worker线程将请求数据从recv buffer中复制到它自己的httpd buffer,于是worker线程可以访问、修改该请求数据,例如URL重写、url翻译转换等。如果分析出这个http请求是某个静态文件,则需要从硬件中加载对应文件,于是发起系统调用通知内核去加载,数据从磁盘中加载到内核的kernel buffer中,再从kernel buffer中复制到httpd buffer,于是worker线程开始准备构建响应数据,这个过程中worker线程可以修改httpd buffer中的数据,例如添加一个相应首部,构建完成后将数据复制到TCP的send buffer中,再复制到网卡中通过网络传输给客户端。假如worker线程分析到这次请求的是动态内容,则需要将动态请求转发给对应的服务器,并最终从该服务器中获取到结果,这个结果很可能也是通过TCP连接进行传输的(假设动静分离了),那么数据就从网卡复制到recv buffer,再复制到httpd buffer,再构建响应。
4.2 prefork模式
这种模式是最简单的模式,而且设置成这种模式后,连指令的值都基本可以采用默认值,因为httpd主进程有很强的自我调节能力。
prefork模式下,一个以root身份运行的主httpd进程(父进程)负责fork一堆以普通身份运行的子httpd进程。启动httpd时,初始化创建的子进程数量由StartServers指令指定。对于prefork模式来说,默认值为5。
4 S root 69856 1 0 80 0 - 56536 poll_s 19:47 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
5 S apache 69857 69856 0 80 0 - 57057 inet_c 19:47 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
5 S apache 69858 69856 0 80 0 - 57057 inet_c 19:47 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
5 S apache 69859 69856 0 80 0 - 57057 inet_c 19:47 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
5 S apache 69860 69856 0 80 0 - 57057 inet_c 19:47 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
5 S apache 69861 69856 0 80 0 - 57057 inet_c 19:47 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
父进程只负责管理维护子进程,例如把超出空闲数量的子进程杀掉,空闲子进程数量不足时创建几个新的子进程,杀掉出了故障的子进程等。子进程才是负责监听和处理web请求的进程,当有请求到达,空闲的子进程会迎接该请求并和该客户端建立连接。通过ServerLimit指令可以硬控制最大的子进程数量,默认值为256,这个值已经很高了,不用改。
为了保证新进来的请求能尽可能快地被处理,prefork的父进程会维护一个空闲子进程池,最大空闲子进程数量和最小空闲子进程数量分别由MaxSpareServers(默认值为10)和MinSpareServers(默认值为5)指定,但通常来说不需要去改变这两个指令的默认值,除非在非常繁忙的站点上。此外,MaxRequestWorkers指令用于设置最大允许的并发连接数量,如果某一刻涌进了大量连接请求,超出该指令值的连接请求会暂时放入等待队列中。
prefork的缺点就是用进程去处理请求,相比于线程,进程太过重量级,对于繁忙的站点来说,不断处理新请求,就需要不断地在进程之间进行切换,进程切换动作对cpu来说是没有生产力的,切换太频繁会浪费很多cpu资源。另一方面,httpd的各子进程之间不共享内存,在一定程度上性能也够好。但它也有优点,基于进程的处理方式,稳定性和调节能力比较好。
另外,由于进程之间的地址空间是相互独立的,多个子进程请求同一个文件时,各子进程都会使用一个独立内存空间去存放这段数据,所以对内存的利用可能浪费比较严重。而如果采用线程,由于子进程中的线程可以共享存放这段数据的空间,所以只需使用少量内存即可。
4.3 worker模式
worker模式是对prefork模式的改进,在进程方面,它和prefork一样,有root身份的父httpd进程,普通身份的子httpd进程。httpd启动时,初始化创建的子进程数量由StartServers指令决定(worker模式下默认为3)。但不同的是,在每个子进程下还有一堆线程。这些线程包括工作线程(worker thread)和一个额外的监听线程(listener thread)。
[root@xuexi ~]# pstree -p | grep http[d]
|-httpd(43510)-+-httpd(43512)-+-{httpd}(43516)
| | |-{httpd}(43520)
| | |-{httpd}(43521)
| | |-{httpd}(43523)
| | |-{httpd}(43524)
| | |-{httpd}(43525)
| | |...............
| |-httpd(43513)-+-{httpd}(43518)
| | |-{httpd}(43546)
| | |-{httpd}(43547)
| | |-{httpd}(43548)
| | |...............
| `-httpd(43514)-+-{httpd}(43522)
| |-{httpd}(43551)
| |-{httpd}(43553)
| |-{httpd}(43555)
| |-{httpd}(43556)
| |-{httpd}(43558)
| |...............
监听线程负责轮询(poll模式)监控开放的服务端口,接收请求并建立连接,然后将连接套接字放入套接字队列中,当工作线程"闲"下来时,将套接字从套接字队列中读走并开始处理。每当工作线程闲下来,都会通知监听线程它当前空闲,这样一来,监听线程就知道它所在子进程中是否还有空闲的工作线程,如果没有空闲工作线程,即满负荷状态,则监听线程暂时不会去接受新连接请求,因为即使接进来放到套接字队列中,也没有工作线程可以立即处理它们。
由于每个子进程中的监听线程都在轮询地监听开放的端口,所以必须要让每个监听线程去获取一种互斥锁(mpm-accept mutex),只有非满负荷的监听线程才能去争抢互斥锁,也才能将连接请求抢到自己的地盘。
这同样说明了,无论是prefork/worker/event或者其他网络模型,在某一刻总是只有一个子进程/线程在监听这个端口,更严格地说是监听已经bind好的套接字描述符。这个效率是不怎么高的,所以现在的Linux内核中已经加入了端口重用选项SO_REUSEPORT,再加上地址重用选项SO_REUSEADDR,就可以让bind将套接字描述符绑定在同一个地址:端口上,这意味着多实例、多进程、多线程可以同时监听同一个套接字。举个简单的例子,默认情况下,同一台主机上行如果要启动两个sshd服务程序,必须让前后启动的服务程序加载含有不同"ADDR:PORT"选项的配置文件,否则会报错。而通过端口重用技术,就可以让这两个sshd同时监听在同一个套接字上,当请求到达时,会通过round-robin均衡算法进行轮询。关于apache开启以及配置端口重用的指令见ListenCoresBucketsRatio。关于地址重用和端口重用技术,见地址/端口重用技术。
回归正题。当子进程中的工作线程处于满负荷状态时,监听线程不会接收新的连接请求。当变为非满负荷状态,那么空闲下来的那个工作线程必然是第一个空闲进程,它必须去通知监听线程,让监听线程知道现在有空闲工作线程,可以读取套接字队列,于是监听线程会去争抢互斥锁以监听开放的端口。
和prefork一样,父进程负责维护子进程的数量。而子进程负责维护该子进程下的线程数量。无论是子进程还是每个子进程下的线程以及空闲的线程数,都有数量限制。ThreadsPerChild指令用于设置每个子进程中的线程数量,MaxSpareThreads和MinSpareThreads指令分别设置每个子进程中最大和最小的空闲线程数,MaxRequestWorkers指定最大允许的并发连接数。
由于每个线程处理一个请求,所以在某一时刻,MaxRequestWorkers的值和此刻线程的数量决定了是否要新创建子进程,以及创建几个子进程。例如某一个时刻线程数量为40,MaxRequestWorkers指令的值为400,那么应该至少要提供10个子进程,少了就要新创建,这都是httpd主进程自动调节的。同理,子进程内的线程也一样,少了就要创建。但显然,不能无限制地创建子进程和线程,所以提供了两个硬限制指令ServerLimit和ThreadLimit,表示即使自动调节时会创建新子进程或线程,但也不能分别超过这两个指令指定的数量。
在理论上,worker比prefork更优,不仅因为它继承了prefork的多进程稳定性和自我调节能力,更重要的是它使用线程来处理每个请求,且还提供了一个专门的监听线程。由于进程中的线程可以共享所在进程的资源,且某个线程的阻塞不会影响进程内其它线程的运行,再一方面,线程共享了子进程的很多资源,它在上下文切换时只需保存、恢复它自己所负责的那一小部分上下文,比进程的切换要轻量的多。因此,线程的工作方式在处理web请求时,无疑比进程性能要好的多。
但是,那只是理论上的。在Linux系统上,实现的线程仅仅只是轻量级的进程,而不是真正意义上的线程。线程没有自己的内存地址空间,有时候一个线程的"崩溃"会导致整个进程"死掉"(例如对公共资源造成了破坏),而且,一个线程写坏另一个线程的栈空间也是很正常的。也就是说,使用线程是不安全的,它的稳定性不如进程。所以,无论是worker还是event模式,都明确说明了要保证线程安全。
关于线程对进程的影响,举个网上找来的例子,虽然不太合理,但描述它们的相互相互影响的方式很合适。
主进程是整辆火车,子进程是每一小节车厢,车厢里的每个乘客是各个线程。每节车厢都有自己公共的卫生间(进程内线程的公共资源:如堆内存),每个乘客也有自己的座位(线程自身的资源:栈空间)。如果某个乘客把自己的座椅搞坏了,那是他自己倒霉,不会影响其他乘客,也不会影响这一节车厢,更不会影响整辆火车。如果某个乘客把别的乘客的座椅搞坏了,比如他旁边的,那么那个人就倒霉,这样也不会影响车厢。但如果某个乘客把公共卫生间搞坏了,这节车厢就整个一起"死",其他乘客只能陪葬。
即使如此,对于httpd来说,在大并发时,使用worker线程处理请求的方式,比使用prefork处理请求的方式性能要好的多。即使某个子进程死了,原本它的线程保持的连接也可以找新的子进程里的线程,只不过对这不幸的一小部分请求来说,它们有可能要重新排排队。
4.4 event模式
event模式的优点在前面就已经说了。它是在worker模式上改进的,也是"主进程-->子进程-->工作线程+监听线程"的方式。它改进的地方是使用了事件驱动IO复用模型(基于epoll),强化了监听线程的工作能力。相比worker模式,它最直观的提升是大大改善了处理长连接(keep alive)的方式,可以一个线程处理多个连接请求。
先说说httpd响应客户端的过程。当httpd进程/线程处理完请求后,就需要构建响应并把相关数据传输给客户端。从开始响应的那一刻开始,内核将数据从内核缓冲区(kernel buffer)源源不断地复制到用户空间的httpd的缓冲区(app buffer),于此同时,httpd进程/线程在app buffer有数据时立即将其中的数据复制到TCP的send buffer中,然后通过网络传输给客户端,直到所有数据都传输完,这次响应才算真正结束。
再说说长连接。当某个请求已经响应结束了,相应的TCP连接也应该立即断开(套接字也被关闭)。如果启用了长连接功能,那么在响应结束后,和发起这个请求的客户端的TCP连接会继续保持着而不会立即断开,这时的TCP连接称为"长连接状态"。当长连接的客户端再次发起请求时,就可以继续使用这个TCP连接进行通信,也就是说不用再重新建立TCP连接。没有开启长连接时,每次建立TCP连接和断开TCP连接都要消耗资源,特别是并发很大的时候,发起一次请求就要建立一次连接、断开一次连接,通常一个页面几十上百个资源是很正常的,这样一来不仅消耗大量资源、速度缓慢,还会占用数以好多倍计的套接字,而每个套接字又都占用一个文件描述符,这又是资源。开启长连接后,这些问题都不再是问题,但它自身却有一个极大的缺陷:占着茅坑不拉屎。既然要保持连接状态,那么这个进程/线程必然要和这个连接绑定在一起,也就必然会有一段时间处于空闲状态,但此时却无法处理其它请求。所以,总会提供一个参数设置长连接的超时时间,时间到了还没有新的请求发送,就关闭连接,有新的请求发送过来,则长连接的超时时间重新计算。但即使设置了超时时间,在没有处理请求的时候,也是一种极大的浪费,对资源的浪费就是对性能的损耗。
现在可以说说event模式的改进了。当请求进来时,监听线程接待它,并将它分配给一个空闲的工作线程进行处理。
- 在响应客户端的时候,数据从kernel buffer复制到app buffer,再从app buffer复制到TCP的send buffer中,最后复制给网卡并通过网络传输到客户端。假如网速很慢,且待传输的数据量比send buffer空间还要大,这时可能会出现send buffer被写满的情况,通常表现为write()函数返回EWOULDBLOCK或EAGAIN。这种情况下,工作线程只能乖乖地等待send buffer中的数据传输给客户端,直到send buffer有足够的空间才会继续从app buffer复制数据进去。在高并发的情况,从请求到响应结束,其中响应数据阶段占用了线程的绝大多数时间。例如,以下是一次简单的并发测试结果的线程记分牌中的一部分状态,共400个工作线程,只有2个工作线程是空闲的,其他工作线程全在sending reply。
event模式对此做出了优化,当某工作线程对应的TCP连接的send buffer被写满时,将这种写等待任务交给监听线程,工作线程自身去处理其它请求。由于event是基于epoll(event poll)的,套接字可以自己站出来告诉监听线程它已经满足条件了,在当监听线程收到了这个等待套接字的相关事件后(例如send buffer已经比较空了,可继续写数据了),它会把这个套接字分配给第一个空闲的工作线程,让该工作线程传输剩余的数据给客户端。WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW_WWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW_WWWWWWWWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWW
以下是某次并发测试的子进程记分牌状态,其中writing列表示的就是此刻每个子进程中因为send buffer写满而交给监听线程的数量。Slot PID Stopping Connections Threads Async connections total accepting busy idle writing keep-alive closing 0 42480 no 25 yes 25 0 1 0 0 1 42481 no 26 yes 25 0 2 0 0 2 42482 no 27 yes 25 0 3 0 2 3 42564 no 27 yes 24 1 2 0 1 4 42618 no 28 yes 25 0 3 0 1 5 42651 no 28 yes 24 1 1 0 2 6 42652 no 26 yes 25 0 1 0 1 7 42709 no 26 no 25 0 1 0 1 8 42710 no 27 no 24 1 1 0 1 9 42711 no 26 yes 25 0 1 0 1 10 42712 no 26 no 25 0 2 0 0 11 42824 no 26 yes 25 0 0 0 2 12 42825 no 26 yes 25 0 1 0 1 13 42826 no 27 yes 22 3 2 0 0 14 42827 no 28 yes 25 0 1 0 2 15 42828 no 26 yes 25 0 1 0 0 Sum 16 0 425 394 6 23 0 15 - 再就是长连接方面的提升。非event模式处理长连接的方式总会有占着茅坑不拉屎的浪费,而event模式下,当工作线程对某次请求的响应结束后,会将处于长连接状态的套接字交给监听线程。如果这个套接字的客户端没有继续发送请求,正常情况下会一直等到直到长连接超时,然后会关闭套接字,断开长连接。如果客户端又发送了请求,由于基于epoll,这个套接字会自己站出来告诉监听线程它有事件发生,于是监听线程会把这个套接字交给第一个空闲的工作线程。
无论什么服务软件,只要它能有效地处理长连接,无疑对性能会有极大的提升。
4.5 记分板
apache httpd采用记分板(ScoreBoard)的方式记录主进程、子进程、线程的状态信息,除了状态信息,还有其他很多信息。记分板为httpd主进程管理各子进程、线程提供了最重要的数据。无论是prefork、worker还是event模式,都采用了记分板,且记分板都是主进程和子进程、线程之间的通信方式之一。因此对于主进程或子进程,它们查找最多的数据就是从记分板获取并计算的。记分板的信息可以通过加载mod_status模块来查看。例如再加载mod_status后,如下设置:
<Location "/server-status">
SetHandler server-status
Require all granted
</Location>
设置之后就可以使用apachectl fullstatus命令或者在浏览器中输出www.example.com/server-status来获取模块的信息。例如,某次prefork的部分信息如下:
[root@xuexi ~]# apachectl fullstatus
Apache Server Status for localhost (via 127.0.0.1)
Server Version: Apache/2.4.6 (CentOS)
Server MPM: prefork
Server Built: Aug 4 2017 03:19:10
----------------------------------------------------------------------
Current Time: Friday, 29-Sep-2017 06:03:52 CST
Restart Time: Friday, 29-Sep-2017 06:03:50 CST
Parent Server Config. Generation: 1
Parent Server MPM Generation: 0
Server uptime: 2 seconds
Server load: 0.00 0.01 0.05
Total accesses: 0 - Total Traffic: 0 kB
CPU Usage: u0 s0 cu0 cs0
0 requests/sec - 0 B/second -
1 requests currently being processed, 4 idle workers
W____...........................................................
................................................................
................................................................
................................................................
httpd启动时,主进程首先会创建记分板对象,然后才创建子进程。httpd中使用的记分板分为3种:全局记分板(global_score)、子进程记分板(process_score)和线程记分板(worker_score)。在include/scoreboard.h中定义了它们。
typedef struct {
global_score *global;
process_score *parent;
worker_score **servers;
} scoreboard;
4.5.1 全局记分板
其中global_score的数据结构为:
typedef struct {
int server_limit;
int thread_limit;
ap_generation_t running_generation; /* the generation of children which
* should still be serving requests.
*/
apr_time_t restart_time;
} global_score;
从中可以看出(看不懂源码也没关系,知道它里面大概是什么单词就够了),全局记分板记录的是子进程和线程的硬限制数量,还包括进程的代数(第几代),最后还记录了这次重启httpd的时间点。
关于子进程的硬限制数量N,httpd在启动时,先在记分板中创建N个槽位(slot),然后创建子进程。每创建一个子进程,就占用一个槽位,每杀死一个子进程,就释放一个槽位。在httpd比较空闲的情况下,槽位可能会空出一些,但是比较繁忙时,会逐渐创建子进程,开始不断占用槽位。直到槽位占尽,就无法再创建子进程,所以,称为硬限制。
同理,线程的硬限制数也是一样的。在httpd启动时,根据子进程的硬限制数,再根据设置的每个子进程的硬限制数,就能计算出总的线程硬限制数,于是主进程会创建这些数量的占位符。
running_generation表示的是进程的代数。所谓代数,表示的是某次启动httpd,那么这次启动后的所有主进程、子进程、线程都是属于这一代的。由于apache httpd支持graceful重启、重读配置文件等等方式重启(graceful的内容下一小节说明),httpd需要使用代数来区分子进程、线程是属于哪个父进程的。每次httpd stop后,再次启动httpd,代数会重置。每次graceful restart或reload(即向主进程发送HUP信号),代数都会加1。
例如,以下某次记分板中的代数信息:
Parent Server Config. Generation: 1
Parent Server MPM Generation: 0
执行一次apachectl graceful操作,或者向主进程发送HUP信号来reload配置文件。它的代数会加1。
Parent Server Config. Generation: 2
Parent Server MPM Generation: 1
4.5.2 子进程记分板
子进程记分板的数据结构如下:
struct process_score {
pid_t pid;
ap_generation_t generation; /* generation of this child */
char quiescing; /* the process whose pid is stored above is
* going down gracefully
*/
char not_accepting; /* the process is busy and is not accepting more
* connections (for async MPMs)
*/
apr_uint32_t connections; /* total connections (for async MPMs) */
apr_uint32_t write_completion; /* async connections doing write completion */
apr_uint32_t lingering_close; /* async connections in lingering close */
apr_uint32_t keep_alive; /* async connections in keep alive */
apr_uint32_t suspended; /* connections suspended by some module */
int bucket; /* Listener bucket used by this child */
};
其中pid是父进程即主httpd进程的进程号,generation记录了该子进程所属的代数。quiescing用来记录将要被graceful停止的子进程号,not_accepting则表示在event模式下,该子进程正忙,无法再接受新的连接请求,connections表示的是event模式下该子进程已建立的总连接数,write_completion是event模式下由于socket send buffer被写满而交给监听线程的套接字(连接)数量,lingering_close是正要被延迟关闭的连接数量,keep_alive是处于长连接状态的连接数量,suspended是被挂起的连接数量,bucket则是在开启端口重用功能时该子进程所监听的套接字。至于write_completion、lingering_close和keep_alive的意义,见前文关于event的内容,而bucket端口重用的内容则见上面worker模型分析总结部分。
由此可见,异步MPM(即event模式)时,子进程的记分板中记录的东西要多一些。以下是event模式下,全局和子进程的记分板信息,当然也包括了一些线程记分板的信息。
Current Time: Friday, 29-Sep-2017 00:19:31 CST
Restart Time: Friday, 29-Sep-2017 00:17:00 CST
Parent Server Config. Generation: 1
Parent Server MPM Generation: 0
Server uptime: 2 minutes 31 seconds
Server load: 11.02 2.51 0.86
Total accesses: 45506 - Total Traffic: 3.4 GB
CPU Usage: u3.46 s27.9 cu0 cs0 - 20.8% CPU load
301 requests/sec - 22.9 MB/second - 77.9 kB/request
394 requests currently being processed, 6 idle workers
Slot PID Stopping Connections Threads Async connections
total accepting busy idle writing keep-alive closing
0 42480 no 25 yes 25 0 1 0 0
1 42481 no 26 yes 25 0 2 0 0
2 42482 no 27 yes 25 0 3 0 2
3 42564 no 27 yes 24 1 2 0 1
4 42618 no 28 yes 25 0 3 0 1
5 42651 no 28 yes 24 1 1 0 2
6 42652 no 26 yes 25 0 1 0 1
7 42709 no 26 no 25 0 1 0 1
8 42710 no 27 no 24 1 1 0 1
9 42711 no 26 yes 25 0 1 0 1
10 42712 no 26 no 25 0 2 0 0
11 42824 no 26 yes 25 0 0 0 2
12 42825 no 26 yes 25 0 1 0 1
13 42826 no 27 yes 22 3 2 0 0
14 42827 no 28 yes 25 0 1 0 2
15 42828 no 26 yes 25 0 1 0 0
Sum 16 0 425 394 6 23 0 15
在这段状态信息中,可以得出很多信息:当前开启的子进程数位16个(slot的位数),正在停止或被杀的进程为0(stopping),每个子进程已经建立的连接数(total),每个子进程当前是否允许接收新套接字(accepting),即该子进程是否正处于满负荷状态,正在忙的线程数(busy),空闲的线程数(idle),因为send buffer被写满而交给监听线程的连接数(writing),处于长连接状态的连接数(keep-alive),正在lingering_close的连接数。此外,还能得出服务器的CPU状态、load(Server load)等信息。
4.5.3 线程记分板
数据结构如下:
typedef struct worker_score worker_score;
struct worker_score {
#if APR_HAS_THREADS
apr_os_thread_t tid;
#endif
int thread_num;
/* With some MPMs (e.g., worker), a worker_score can represent
* a thread in a terminating process which is no longer
* represented by the corresponding process_score. These MPMs
* should set pid and generation fields in the worker_score.
*/
pid_t pid;
ap_generation_t generation;
unsigned char status;
unsigned short conn_count;
apr_off_t conn_bytes;
unsigned long access_count;
apr_off_t bytes_served;
unsigned long my_access_count;
apr_off_t my_bytes_served;
apr_time_t start_time;
apr_time_t stop_time;
apr_time_t last_used;
#ifdef HAVE_TIMES
struct tms times;
#endif
char client[32]; /* Keep 'em small... */
char request[64]; /* We just want an idea... */
char vhost[32]; /* What virtual host is being accessed? */
char protocol[16]; /* What protocol is used on the connection? */
};
这线程记分板里记录的东西有点多,懒得管它,只要知道它会记录很多线程的状态信息就够了。其实看一点状态显示结结果,大概就知道记录的都是些什么了。如下,是event模式下的一次状态信息。
WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW_WWWWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWW_WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWW_WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWW_WW_WWWWWWWWWWWWWWWWWWWW_WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWW
Scoreboard Key:
"_" Waiting for Connection, "S" Starting up, "R" Reading Request,
"W" Sending Reply, "K" Keepalive (read), "D" DNS Lookup,
"C" Closing connection, "L" Logging, "G" Gracefully finishing,
"I" Idle cleanup of worker, "." Open slot with no current process
Srv PID Acc M CPU SS Req Conn Child Slot Client Protocol VHost Request
0-0 42480 0/137/137 W 2.51 0 0 0.0 10.43 10.43 192.168.100.17 http/1.1
customer.sharktech.net:80 GET /index.php HTTP/1.0
0-0 42480 0/141/141 W 2.31 2 0 0.0 10.73 10.73 192.168.100.17 http/1.1
customer.sharktech.net:80 GET /index.php HTTP/1.0
0-0 42480 0/83/83 W 2.42 1 0 0.0 6.32 6.32 192.168.100.17 http/1.1
customer.sharktech.net:80 GET /index.php HTTP/1.0
........................................................................
此处省略大部分内容
........................................................................
__________________________________________________________________
Srv Child Server number - generation
PID OS process ID
Acc Number of accesses this connection / this child / this slot
M Mode of operation
CPU CPU usage, number of seconds
SS Seconds since beginning of most recent request
Req Milliseconds required to process most recent request
Conn Kilobytes transferred this connection
Child Megabytes transferred this child
Slot Total megabytes transferred this slot
4.6 graceful restart问题
先说下graceful restart在daemon类进程中的意思。
通常,服务类的程序都采用daemon类进程的管理方式进行管理,这类进程一般都会脱离终端,直接挂靠在祖先进程init/systemd之下。也就是说,关闭终端不会影响服务的继续运行。通常这类程序可以接受SIGHUP信号,这是reload的功能,即不重启服务的情况下重新加载配置文件。除此之外,经常看到有些服务程序(如httpd/nginx)的启动脚本中使用WINCH、USR1这两个信号,发送这两个信号时它们分别表示graceful stop和graceful restart。所谓的graceful,译为优雅,不过使用这两个字去描述这种环境实在有点不伦不类。它对于后台服务程序而言,传达了几个意思:(1)当前已经运行的进程不再接受新请求(2)给当前正在运行的进程足够多的时间去完成正在处理的事情(3)允许启动新进程接受新请求(4)可能还有日志文件是否应该滚动、pid文件是否修改的可能,这要看服务程序对信号的具体实现。
再来说说,为什么后台服务程序可以使用这两个信号。以httpd为例,在其头文件mpm_common.h中有如下几行代码:
/* Signal used to gracefully restart */
#define AP_SIG_GRACEFUL SIGUSR1
/* Signal used to gracefully stop */
#define AP_SIG_GRACEFUL_STOP SIGWINCH
这说明注册了对应信号的处理函数,它们分别表示将接收到信号时,执行对应的GRACEFUL函数。
注意,SIGWINCH是窗口程序的尺寸改变时发送改信号,如vim的窗口改变了就会发送该信号。但是对于后台服务程序,它们根本就没有窗口,所以WINCH信号对它们来说是没有任何作用的。因此,大概是约定俗成,程序员们都喜欢用它来作为后台服务程序的GRACEFUL信号。但注意,WINCH信号对前台程序是有影响的,不能乱发这种信号。同理,USR1和USR2也是一样的,如果源代码中明确为这两个信号注册了对应函数,那么发送这两个信号就可以实现对应的功能,反之,如果没有注册,则这两个信号对进程来说是错误信号。
由此,graceful restart看上去感觉很美好,但是对于httpd主进程来说,它很不美好,因为进程所属代数的原因,使得主进程不好处理新、旧两代子进程、线程、连接数等指标。例如,以下是某次httpd正在处理大量请求的时执行apachectl graceful的状态信息:
Slot PID Stopping Connections Threads Async connections
total accepting busy idle writing keep-alive closing
0 42480 yes (old gen) 2 no 0 0 0 0 0
1 42481 yes (old gen) 1 no 0 0 0 0 0
2 42482 yes (old gen) 1 no 0 0 0 0 0
3 42564 yes (old gen) 3 no 0 0 0 0 0
4 42618 yes (old gen) 3 no 0 0 0 0 0
5 42651 yes (old gen) 4 no 0 0 0 0 0
6 42652 yes (old gen) 3 no 0 0 0 0 0
7 43618 no 28 yes 25 0 2 0 1
8 42710 yes (old gen) 2 no 0 0 0 0 0
9 42711 yes (old gen) 1 no 0 0 0 0 0
10 42712 yes (old gen) 3 no 0 0 0 0 0
11 42824 yes (old gen) 3 no 0 0 0 0 0
12 42825 yes (old gen) 2 no 0 0 0 0 0
13 42826 yes (old gen) 1 no 0 0 0 0 0
14 42827 yes (old gen) 5 no 0 0 0 0 0
15 42828 yes (old gen) 4 no 0 0 0 0 0
Sum 16 15 66 25 0 2 0 1
..................G....G...............G........................
...G.........G...GG.....................G.G...............G.....
........GG........G.G..G................G...G..WWWWWWWWWWWWWWWWW
WWWWWWWW....G........G...................................G......
...G.G......G........G.G............G..........GG...............
...........G....................G...G...G.G......G.............G
.....G........GG
其中标记了"old gen"的表示这是老一代的子进程,"G"表示正在graceful stop的线程。正在graceful重启时,无疑请求处理的速度要慢很多,很可能导致大量并发连接请求被排队直到连接超时。目前看上去,graceful restart的管理没什么问题,但在以前没有使用ServerLimit来指导生成slot数量的时候,graceful重启的问题非常大,因为主进程不知道是不是应该继续创建子进程,而通过serverlimit来指导初始化时的slot数量,不管子进程是否在graceful stop,只要slot槽位有空的就创建。另外,当服务器极度繁忙时,繁忙到杀子进程来降低压力,graceful restart时到底要杀哪个新一代的还是老一代的子进程?再就是长连接的问题,graceful restart时,必须等待连接完全断开才会换代,但是长连接的问题导致断开时间可能比较长,要不要杀掉呢?当然要杀掉。
当然,graceful的问题在目前版本来说是没有多大问题的,因为httpd已经通过各种方法解决了大方向上的问题,而且在不繁忙的时候,graceful restart也没什么影响。而在繁忙时,谁吃傻逼了在这个时候去graceful restart?
转载请注明出处:https://www.cnblogs.com/f-ck-need-u/p/7628728.html
如果觉得文章不错,不妨给个打赏,写作不易,各位的支持,能激发和鼓励我更大的写作热情。谢谢!

Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html







【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!