零复制(zero copy)技术
1.1 背景说明:网络数据传输的全过程
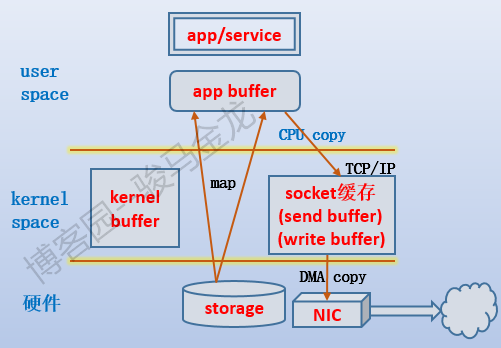
在每一次网络io过程,数据都要经过几个缓存,再发送出去。如下图:

以右侧为浏览器,左侧为httpd服务器为例。
- 当httpd服务收到浏览器发送的index.html文件的请求时,负责处理请求的httpd子进程/线程总是会先发起系统调用,让内核将index.html从存储设备中加载出来。但是加载到的位置是内核空间的缓冲区kernel buffer,而不是直接给进程/线程的内存区。由于是内存设备和存储设备之间的数据传输,没有CPU的参与,所以这次是DMA操作。
- 当数据准备好后,内核唤醒httpd子进程/线程,让它使用read()函数把数据复制到它自己的缓冲区,也就是图中的app buffer。到了app buffer中的数据,已经独属于进程/线程,也就可以对它做读取、修改等等操作。由于这次是使用CPU来复制的,所以会消耗CPU资源。由于这个阶段从内核空间切换到用户空间,所以进行了上下文切换。
- 当数据修改完成(也可能没做任何操作)后,按我们所想的,需要把它响应给浏览器,也就是说要通过TCP连接传输出去。但TCP协议栈有自己的缓冲区,要通过它发送数据,必须将数据写到它的buffer中,对于发送者就是send buffer,对于接受者就是recv buffer。于是,通过write()函数将数据再次从app buffer复制到send buffer。这次也是CPU参与进行的复制,所以会消耗CPU。同样也会进行上下文切换。
- 非本机数据最终还是会通过网卡传输出去的,所以再使用send()函数就可以将send buffer中的数据交给网卡并通过网卡传输出去。由于这次是内存和设备之间的数据传输,没有CPU的参与,所以这次也是DMA操作。
- 当浏览器所在主机的网卡收到响应数据后(当然,数据是源源不断传输的),将它传输到TCP的recv buffer。这次是DMA操作。
- 数据源源不断地填充到recv buffer中,但是浏览器却不一定会去读取,而是需要通知浏览器进程使用recv()函数将数据从read buffer中取走。这次是CPU操作(图中忘记标注了)。
需要注意,对于httpd端来说,如果网速很慢,而httpd子进程/线程需要响应出去的数据又足够大(比send buffer还大),很可能会导致socket buffer填满的情况,这时write()函数会返回EWOULDBLOCK或EAGAIN,子进程/线程会进入等待状态。
对于浏览器一端来说,如果浏览器进程迟迟不将数据从socket buffer(recv buffer)中取走,很可能会导致socket buffer被填满。
再来说httpd端网络数据的"经历"。如下图:

每次进程/线程需要一段数据时,总是先拷贝到kernel buffer,再拷贝到app buffer,再拷贝到socket buffer,最后再拷贝到网卡上。也就是说,总是会经过4段拷贝经历。
但想想,正常情况下,数据从存储设备到kernel buffer是必须的,从socket buffer到NIC也是必须的,但是从kernel buffer到app buffer是必须的吗?进程一定需要访问、修改这些数据吗?不一定,甚至对于web服务来说,如果不是要修改http响应报文,数据完全可以不用经过用户空间。也就是不用再从kernel buffer拷贝到app buffer,这就是零复制的概念。
零复制的概念是避免将数据在内核空间和用户空间进行拷贝。主要目的是减少不必要的拷贝,避免让CPU做大量的数据拷贝任务。
注:上面只是说正常情况下,例如某些硬件可以完成TCP/IP协议栈的工作,数据可以不经过socket buffer,直接在app buffer和硬件之间传输数据,RDMA技术就是在此基础上实现的。
1.2 zero-copy:mmap()
mmap()函数将文件直接映射到用户程序的内存中,映射成功时返回指向目标区域的指针。这段内存空间可以用作进程间的共享内存空间,内核也可以直接操作这段空间。
在映射文件之后,暂时不会拷贝任何数据到内存中,只有当访问这段内存时,发现没有数据,于是产生缺页访问,使用DMA操作将数据拷贝到这段空间中。可以直接将这段空间的数据拷贝到socket buffer中。所以也算是零复制技术。如图:
代码如下:
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);1.3 zero-copy:sendfile()
man文档对此函数的描述:
sendfile() copies data between one file descriptor and another. Because this copying is done within the kernel, sendfile() is more efficient than the combination of read(2) and write(2), which would require transferring data to and from user space.
sendfile()函数借助文件描述符来实现数据拷贝:直接将文件描述in_fd的数据拷贝给文件描述符out_fd,其中in_fd是数据提供方,out_fd是数据接收方。文件描述符的操作都是在内核进行的,不会经过用户空间,所以数据不用拷贝到app buffer,实现了零复制。如下图

sendfile()的代码如下:
#include<sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
但是sendfile的in_fd必须指向支持mmap的文件,也就是真实存在的文件,而不能是socket、管道等文件。在Linux 2.6.33之前,还限制out_fd必须是指向socket文件的描述符,所以人们总认为它专门用于进行网络数据拷贝。但从Linux 2.6.33开始,out_fd可以是任何文件,且如果是一个普通文件,则sendfile()会合理地修改文件的offset。
以nginx开启了tcp_nopush的sendfile为例,当开启了tcp_nopush功能后,nginx先在用户空间构建响应首部,并放进socket send buffer中,然后再向sender buffer中写入一个待加载文件的标识(例如,声明我稍后要读取a.txt文件中的数据发给你),这两部分先发送给客户端,然后再加载磁盘文件(sendfile模式加载),每挤满一次send buffer就发送一次,直到所有数据都发送完。
1.4 zero-copy:splice()
man文档对此函数的描述:
splice() moves data between two file descriptors without copying between kernel address space and user address space.
It transfers up to len bytes of data from the file descriptor fd_in to the file descriptor fd_out, where one of
thedescriptors must refer to a pipe.
splice()函数可以在两个文件描述符之间移动数据,且其中一个描述符必须是管道描述符。由于不需要在kernel buffer和app buffer之间拷贝数据,所以实现了零复制。如图:

注:由于必须有一方是管道描述符,所以上图中,如果是发送给socket文件描述符,那么是没有storage-->kernel buffer的DMA操作的。
代码如下:
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <fcntl.h>
ssize_t splice(int fd_in, loff_t *off_in, int fd_out,
loff_t *off_out, size_t len, unsigned int flags);
1.5 zero-copy: tee()
man文档对此函数的描述:
tee() duplicates up to len bytes of data from the pipe referred to by the file descriptor fd_in to the pipe
referred to by the file descriptor fd_out. It does not consume the data that is duplicated from fd_in;
therefore, that data can be copied by a subsequent splice(2).
tee()函数在两个管道描述符之间复制数据。由于从in_fd复制给另一个管道out_fd时,不认为数据是来自于in_fd的,所以复制数据后,in_fd仍可使用splice()函数进行数据移动。由于没有经过用户空间,所以实现了零复制。如图:
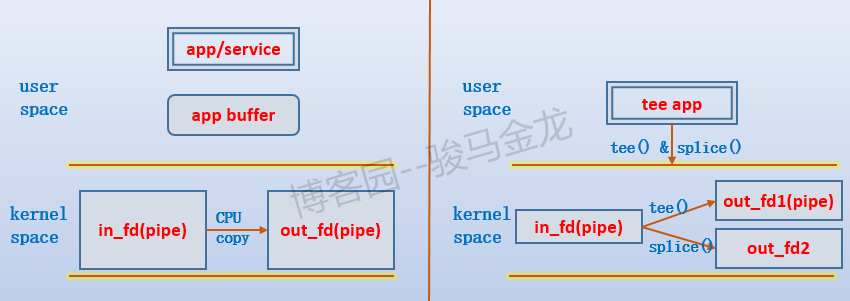
Linux下的tee程序就是使用tee函数结合splice函数实现的,先将数据通过tee()函数拷贝给管道,再使用splice()函数将数据移动给另一个文件描述符。
代码如下:
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <fcntl.h>
ssize_t tee(int fd_in, int fd_out, size_t len, unsigned int flags);
1.6 写时复制技术(copy-on-write,COW)
当父进程fork生成子进程时,会复制它的所有内存页。这至少会导致两个问题:消耗大量内存;复制操作消耗时间。特别是fork后使用exec加载新程序时,由于会初始化内存空间,所以复制操作几乎是多余的。
使用copy-on-write技术,使得在fork子进程时不复制内存页,而是共享内存页(也就是说,子进程也指向父进程的物理空间),只有在该子进程需要修改某一块数据,才会将这一块数据拷贝到自己的app buffer中并进行修改,那么这一块数据就属于该子进程的私有数据,可随意访问、修改、复制。这在一定程度上实现了零复制,即使复制了一些数据块,也是在逐渐需要的过程进行复制的。
写时复制内容太多,简单概述的话大概就是上面所述内容。
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

