第7章 Linux上配置RAID
7.1 RAID概念
RAID独立磁盘冗余阵列(Redundant Array of Independent Disks),RAID技术是将许多块硬盘设备组合成一个容量更大、更安全的硬盘组,可以将数据切割成多个区段后分别存放在各个不同物理硬盘设备上,然后利用分散读写需求来提升硬盘组整体的性能,同时将重要数据同步保存多份到不同的物理硬盘设备上,可以有非常好的数据备份效果。
由于对成本和技术两方面的考虑,因此需要针对不同的需求在数据可靠性及读写性能上做权衡,制定出各自不同的合适方案,目前已有的RAID硬盘组的方案至少有十几种,RAID0、RAID1、RAID5、RAID10和RAID01是五种最常见的方案。
不得不说的是,raid了解越深入,越能体会到选择和平衡的思想。
关于详细的raid技术和原理实现方面,查看man md,该文档中给出了非常详细的实现方式,包括数据是如何组织的。
7.1.1 RAID 0
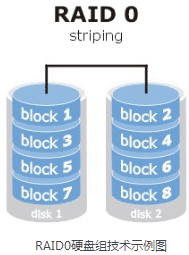
首先是RAID0硬盘组,这项技术是将多块物理硬盘设备通过硬件或软件的方式串联在一起,成为一个大的卷组,有时它称为条带卷(striping)。它将数据依次分别写入到各个物理硬盘中,这样最理想的状态会使得读写性能提升数倍,但若任意一块硬盘故障则会让整个系统的数据都受到破坏。
通俗来说RAID0硬盘组技术至少需要两块物理硬盘设备,能够有效的提高硬盘的性能和吞吐量,但没有数据的冗余和错误修复能力。如图中所示,数据被分别写入到不同的硬盘设备中。
7.1.2 RAID 1
RAID0技术虽然提高了存储设备的IO读写速度,但RAID0中数据是被分开存放的,也就是说其中任何一块硬盘出现问题都会破坏数据完整性。因此追求数据安全性的时候就不应该使用RAID0,而是使用RAID1。
如图所示,RAID1硬盘组技术是将两块以上的存储设备进行绑定,目的是让数据被多块硬盘同时写入,类似于把数据再制作出多份镜像,当有某一块硬盘损坏后,一般可以立即通过热交换方式来恢复数据的正常使用。
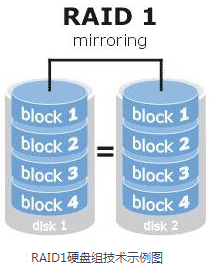
RAID1注重了数据的安全性,但因为是将多块硬盘中写入相同的数据,也就是说硬盘空间的真实可用率在理论上只有50%(利用率是1/n,n是阵列中的磁盘数量,不分奇偶),因此会明显的提高硬盘组成本。另外,因为需要将数据同时写入到两块以上的硬盘设备中,这无疑也会增加一定系统负载。
但要注意,raid1因为同一份数据保存了多份,所以读性能和RAID0是一样的(粗略的说是一样。更细致的要分随机读、顺序读,这时不一定和raid0一样)。
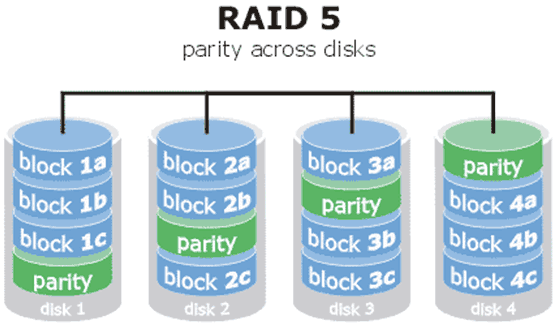
7.1.3 RAID 5
实际上单从数据安全和成本问题上来讲,就不可能在保持存储可用率的同时还不增加新设备的情况下大幅提升数据的安全性,RAID5硬盘组技术虽然理论上是兼顾三者的,但实际上是对各个方面的互相妥协和平衡。
7.1.4 RAID 10
RAID5在成本问题和读写速度以及安全性能上进行了妥协,但绝大部分情况下,相比硬盘的价格,数据的价值才是更重要的.因此更多的是使用RAID10,就是对RAID1+RAID0的一个"组合体"。
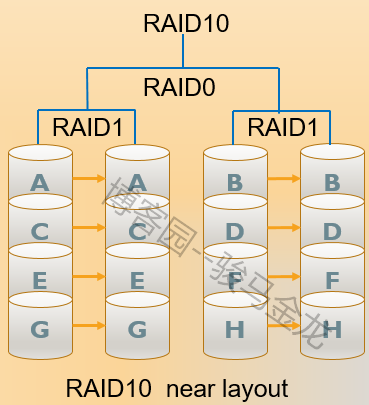
如图所示,RAID10需要至少4块硬盘,先分别两两制作成RAID1,保证数据的安全性,然后再对两个RAID1实施RAID0技术,进一步的提高存储设备的读写速度,这样理论上只要坏的不是同一组中的所有硬盘,那么最多可以损坏50%的硬盘设备而不丢失数据,因此RAID10硬盘组技术继承了RAID0更高的读写速度和RAID1更安全的数据保障,在不考虑成本的情况下RAID10在读写速度和数据保障性方面都超过了RAID5,是较为广泛使用的存储技术。
注意,上图中一个数据块是相邻存储在相同偏移的,即A和A在相邻设备的同一高度,这只是RAID10的一种复制方法,称为near复制方法,也是默认复制方法。此外,还有far、offset两种复制方法。
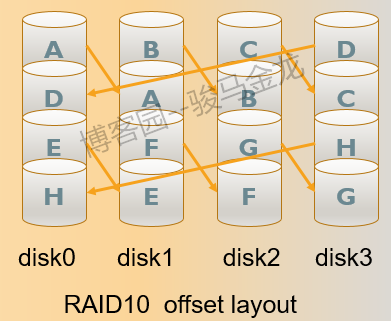
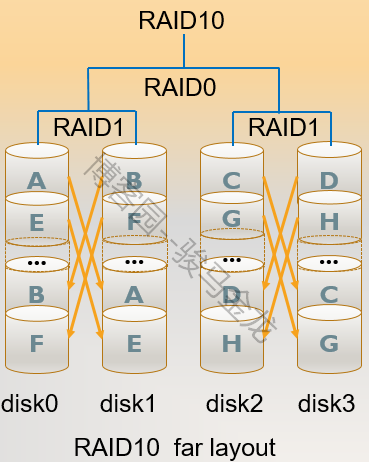
7.1.5 RAID 01
RAID 10是RAID1+RAID0,而RAID01则是RAID0+RAID1。看起来它们是相同的,但实际上它们的差别在安全性上差很大。
如下图。从图中可以看出,在RAID01正常工作的时候,它的性能和RAID10是一样的,都是条带一份,镜像一份。但是区别就在于安全性上。
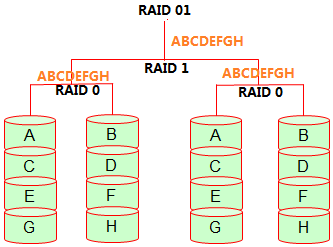
如果RAID0组中的一块磁盘坏了,对于这一个RAID0组来说,它已经失效了,并不是还可以从该组中的另一块磁盘中读取一半数据。
也就是说,RAID01只要坏了一块盘后,该RAID0组就失效,IO的压力就只在另一个RAID0组上,这很容易导致这一个raid0组也损坏磁盘,只要这时再坏一块盘,所有数据就丢失了。
所以RAID01基本无人使用,太不安全。
7.1.6 RAID的冗余和性能计算
以下图片截自wiki:https://en.wikipedia.org/wiki/Standard_RAID_levels
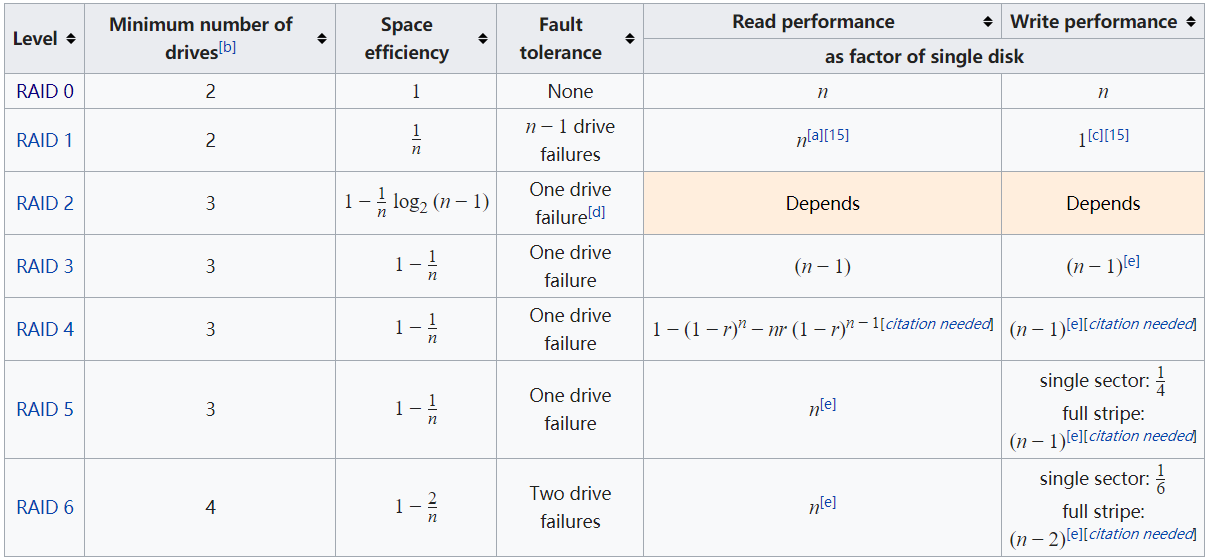
7.1.7 关于raid的理想值和实际应用值
上面介绍的,已经很多书上、老师讲解的都是raid的理论情况,比如raid10的持续写速度是"单盘速度*盘数量除2",raid5能实现盘数量-1的最大理论速度。但是这些都是"去他妈"的理论值,RAID的实际使用情况和理论之间有巨大的差别。所以,很有必要了解一下实际应用中那些理论之外的内容。
以下是我找到的一篇很不错的介绍raid的理论外文章:https://zhuanlan.zhihu.com/p/31944934
7.2 Linux上软raid管理
7.2.1 实现RAID10
首先需要为虚拟机中添加4块硬盘设备(若以分区加入,则分区标识符为raid)来制作一个RAID10。然后使用mdadm工具用于在Linux系统中创建和管理软RAID。
mdadm命令的格式为:
mdadm [模式] <RAID设备名称> [选项] [成员设备名称] 选项说明: 【创建模式】 -C:创建(create a new array) -l:指定raid级别(Set RAID level,0,1,5,10) -c:指定chunk大小(Specify chunk size of kibibytes,default 512KB) -a:检测设备名称(--auto=yes),yes表示自动创建设备文件/dev/mdN -n:指定设备数量(--raid-devices:Specify the number of active devices in the array) -x:指定备用设备数量(--spare-devices:Specify the number of spare (eXtra) devices in the initial array) -v:显示过程 -f:强制行为 -r:移除设备(remove listed devices) -S:停止阵列(--stop:deactivate array, releasing all resources) -A:装配阵列,将停止状态的阵列重新启动起来 【监控模式】 -Q:查看摘要信息(query) -D:查看详细信息(Print details of one or more md devices) mdadm -D --scan >/etc/mdadm.conf,以后可以直接mdadm -A进行装配这些阵列 【管理模式】 mdadm --manage /dev/md[0-9] [--add 设备名] [--remove 设备名] [--fail 设备名] --manage :mdadm使用manage模式,此模式下可以做--add/--remove/--fail/--replace动作 -add :将后面列出的设备加入到这个md --remove :将后面列出的设备从md中移除,相当于硬件raid的拔出动作 --fail :将后面列出的设备设定为错误状态,即人为损坏,损坏后该设备放在raid中已经是无意义状态的
(1).准备磁盘或分区,以分区为例。
/dev/sd{b,c,d,e}1这四个分区都是200M大小。
(2).使用mdadm命令创建RAID10,名称为"/dev/md0"。
用-C参数代表创建一个RAID阵列卡,-v参数来显示出创建的过程,同时在后面追加一个设备名称,-a yes参数代表自动创建设备文件,-n 4参数代表使用4块硬盘(分区)来制作这个RAID组,而-l 10参数则代表RAID10,最后再加上4块设备的名称就可以了。
[root@xuexi ~]# mdadm -C /dev/md0 -n 4 -l 10 -a yes /dev/sd{b,c,d,e}1
mdadm: /dev/sdb1 appears to contain an ext2fs file system
size=10485760K mtime=Thu Jan 1 08:00:00 1970
Continue creating array? y
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
查看RAID设备信息。
[root@xuexi ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Fri Jun 9 21:44:59 2017 Raid Level : raid10 Array Size : 387072 (378.06 MiB 396.36 MB) # 总共能使用的空间,因为是raid10,所以总可用空间为400M左右,除去元数据,大于370M左右 Used Dev Size : 193536 (189.03 MiB 198.18 MB) # 每颗raid组或设备上的可用空间,也即每个RAID1组可用大小为190M左右 Raid Devices : 4 # raid中设备的个数 Total Devices : 4 # 总设备个数,包括raid中设备个数,备用设备个数等 Persistence : Superblock is persistent Update Time : Fri Jun 9 21:45:02 2017 State : clean # 当前raid状态,有clean/degraded(降级)/recovering/resyncing Active Devices : 4 Working Devices : 4 Failed Devices : 0 Spare Devices : 0 Layout : near=2 # RAID10数据分布方式,有near/far/offset,默认为near,即数据的副本存储在相邻设备的相同偏移上。near=2表示要备份2份数据 Chunk Size : 512K Name : xuexi.longshuai.com:0 (local to host xuexi.longshuai.com) UUID : ff2b7d7c:381a4c47:c31e7edd:7cdef01e Events : 17 Number Major Minor RaidDevice State 0 8 17 0 active sync set-A /dev/sdb1 # 第一个raid1组A成员 1 8 33 1 active sync set-B /dev/sdc1 # 第一个raid1组B成员 2 8 49 2 active sync set-A /dev/sdd1 # 第二个raid1组A成员 3 8 65 3 active sync set-B /dev/sde1 # 第二个raid1组B成员
raid创建好后,它的运行状态信息放在/proc/mdstat中。
[root@xuexi ~]# cat /proc/mdstat Personalities : [raid10] md0 : active raid10 sde1[3] sdd1[2] sdc1[1] sdb1[0] 387072 blocks super 1.2 512K chunks 2 near-copies [4/4] [UUUU] unused devices: <none>
其中"md0 : active raid10 sde1[3] sdd1[2] sdc1[1] sdb1[0]"表示md0是raid10级别的raid,且是激活状态,sdX[N]表示该设备在raid组中的位置是N,如果有备用设备,则表示方式为sdX[N][S],S就表示spare的意思。
其中"387072 blocks super 1.2 512K chunks 2 near-copies [4/4] [UUUU]"表示该raid可用总空间为387072个block,每个block为1K,所以为378M,chunks的大小512K,[m/n]表示此raid10阵列需要m个设备,且n个设备正在正常运行,[UUUU]表示分别表示m个的每一个运行状态,这里表示这4个设备都是正常工作的,如果是不正常的,则以"_"显示。
再看看lsblk的结果。
[root@xuexi ~]# lsblk -f NAME FSTYPE LABEL UUID MOUNTPOINT loop0 iso9660 CentOS_6.6_Final /mnt sda ├─sda1 ext4 77b5f0da-b0f9-4054-9902-c6cdacf29f5e /boot ├─sda2 ext4 f199fcb4-fb06-4bf5-a1b7-a15af0f7cb47 / └─sda3 swap 6ae3975c-1a2a-46e3-87f3-d5bd3f1eff48 [SWAP] sr0 sdb └─sdb1 linux_raid_member xuexi.longshuai.com:0 ff2b7d7c-381a-4c47-c31e-7edd7cdef01e └─md0 sdc └─sdc1 linux_raid_member xuexi.longshuai.com:0 ff2b7d7c-381a-4c47-c31e-7edd7cdef01e └─md0 sdd └─sdd1 linux_raid_member xuexi.longshuai.com:0 ff2b7d7c-381a-4c47-c31e-7edd7cdef01e └─md0 sde └─sde1 linux_raid_member xuexi.longshuai.com:0 ff2b7d7c-381a-4c47-c31e-7edd7cdef01e └─md0
(3).将制作好的RAID组格式化创建文件系统。
以创建ext4文件系统为例。
[root@xuexi ~]# mke2fs -t ext4 /dev/md0
(4).挂载raid设备,挂载成功后可看到可用空间为359M,因为RAID在创建文件系统时也消耗了一部分空间存储文件系统的元数据。
[root@xuexi ~]# mount /dev/md0 /mydata [root@xuexi ~]# df -hT Filesystem Type Size Used Avail Use% Mounted on /dev/sda2 ext4 18G 2.7G 14G 16% / tmpfs tmpfs 491M 0 491M 0% /dev/shm /dev/sda1 ext4 239M 28M 199M 13% /boot /dev/md0 ext4 359M 2.1M 338M 1% /mydata
7.2.2 损坏磁盘阵列及修复
通过manage模式可以模拟阵列中的设备损坏。
mdadm --manage /dev/md[0-9] [--add 设备名] [--remove 设备名] [--fail 设备名] 选项说明: manage :mdadm使用manage模式,此模式下可以做--add/--remove/--fail/--replace动作 --add :将后面列出的设备加入到这个md --remove :将后面列出的设备从md中移除 --fail :将后面列出的设备设定为错误状态,即人为损坏
模拟/dev/sdc1损坏。
[root@xuexi mydata]# mdadm --manage /dev/md0 --fail /dev/sdc1 mdadm: set /dev/sdc1 faulty in /dev/md0
再查看raid状态。
[root@xuexi mydata]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Fri Jun 9 21:44:59 2017 Raid Level : raid10 Array Size : 387072 (378.06 MiB 396.36 MB) Used Dev Size : 193536 (189.03 MiB 198.18 MB) Raid Devices : 4 Total Devices : 4 Persistence : Superblock is persistent Update Time : Fri Jun 9 22:22:29 2017 State : clean, degraded Active Devices : 3 Working Devices : 3 Failed Devices : 1 Spare Devices : 0 Layout : near=2 Chunk Size : 512K Name : xuexi.longshuai.com:0 (local to host xuexi.longshuai.com) UUID : ff2b7d7c:381a4c47:c31e7edd:7cdef01e Events : 19 Number Major Minor RaidDevice State 0 8 17 0 active sync set-A /dev/sdb1 2 0 0 2 removed 2 8 49 2 active sync set-A /dev/sdd1 3 8 65 3 active sync set-B /dev/sde1 1 8 33 - faulty /dev/sdc1
由于4块磁盘组成的raid10允许损坏一块盘,且还允许坏第二块非对称盘。所以这里损坏了一块盘后raid10是可以正常工作的。
现在可以将损坏的磁盘拔出,然后向raid中加入新的磁盘即可。
mdadm --manage /dev/md0 --remove /dev/sdc1
再修复时,可以将新磁盘加入到raid中。
mdadm --manage /dev/mn0 --add /dev/sdc1
7.2.3 raid备份盘
使用mdadm的"-x"选项可以指定备份盘的数量,备份盘的作用是自动顶替raid组中坏掉的盘。
7.2.4 停止和装配raid
shell> umount /dev/md0 shell> mdadm --stop /dev/md0
关闭raid阵列后,该raid组/dev/md0就停止工作了。
如果下次想继续启动它,直接使用-A来装配/dev/md0是不可以的,需要再次指定该raid中的设备成员,且和关闭前的成员一样,不能有任何不同。
mdadm -A /dev/md0 /dev/sd{b,c,d,e}1
这样做不太保险,其实可以在停止raid前,扫描raid,将扫描的结果保存到配置文件中,下次启动的时候直接读取配置文件即可。
mdadm -D --scan >> /etc/mdadm.conf # 这是默认配置文件
下次直接使用-A就可以装置配置文件中的raid组。
mdadm -A /dev/md0
如果不放在默认配置文件中,则装配的时候使用"-c"或"--config"选项指定配置文件即可。
shell> mdadm -D --scan >> /tmp/mdadm.conf
shell> mdadm -A /dev/md0 -c /tmp/mdadm.conf
7.2.5 彻底移除raid设备
当已经确定一个磁盘不需要再做为raid的一部分,可以将它移除掉。彻底移除一个raid设备并非那么简单,因为raid控制器已经标记了一个设备,即使将它"mdadm --remove"也无法彻底消除raid的信息。
以移除/dev/md127中的/dev/sdb1为例。
首先,卸载、停止、移除:
umount /dev/sdb1 mdadm --stop /dev/md127 mdadm --manage /dev/md127 --remove /dev/sdb1
虽然从raid中移除了,但是江湖上还有它的传说:删除分区、创建分区、格式化,格式化的时候将被保护
$ parted /dev/sdb rm 1 $ parted /dev/sdb mkpart p 1 20G $ mke2fs -t ext4 /dev/sdb1 /dev/sdb1 is apparently in use by the system; will not make a filesystem here!
然后再去扫描raid设备,发现它又出现在raid组中:
$ mdadm -D -s ARRAY /dev/md/xuexi.longshuai.com:0 metadata=1.2 ............
$ lsblk -f NAME FSTYPE LABEL UUID MOUNTPOINT sda ├─sda1 xfs 367d6a77-033b-4037-bbcb-416705ead095 /boot ├─sda2 xfs b2a70faf-aea4-4d8e-8be8-c7109ac9c8b8 / └─sda3 swap d505113c-daa6-4c17-8b03-b3551ced2305 [SWAP] sdb └─sdb1 linux_raid_member xue........ └─md127 ext4 2fed1dcc-b9a2-477f-8c8f-7131bbd4e919
换句话说,只要这个设备曾经是raid的一份子,你就没法再直接使用它。就算你分区了,也不让你格式化。
所以,要彻底移除一个raid设备,需要清空控制器可以读取的raid签名,只需将这个raid设备(可能是一个分区)的raid superblock用0去覆盖掉就行了:
$ umount /dev/sdb1 $ mdadm --stop /dev/md127 $ mdadm --manage /dev/md127 --remove /dev/sdb1 $ mdadm --zero-superblock --force /dev/sdb1 # 这条命令是关键
然后,这个设备就和raid控制器完全say goodbye了:
$ lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sda
...........
sdb
└─sdb1
现在格式化也可以正常进行了:
mke2fs -t ext4 /dev/sdb1
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号