

Linux内核创建新进程的过程
作者:xujianguo
原创作品转载请注明出处,《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
——————————————————————————————————————————————————————-————
实验目的:
- 使用gdb跟踪分析一个fork系统调用内核处理函数sys_clone ,验证您对Linux系统创建一个新进程的理解;
- 分析fork函数对应的内核处理过程sys_clone,理解创建一个新进程如何创建和修改task_struct数据结构;
实验环境:
实验楼:www.shiyanlou.com。
实验步骤:
1.配置环境,登录实验楼网站。
按照上次实验的基本步骤,结合老师视频所讲,完成相关实验。
cd LinuxKernel
删除menu
然后从github上克隆相应的mengning/menu.git

2.测试menuOS,测试fork直接执行结果。
.
3.配置调试系统:
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S

4.进入gdb调试,利用file linux-3.18.6/vmlinux和target remote:1234来配置加载初始调试环境.

5.在linux内核进程创建可能用到的点设置断点分别为sys_clone,do_fork,dup_task_struct,copy_thread,copy_process和ret_from_fork.
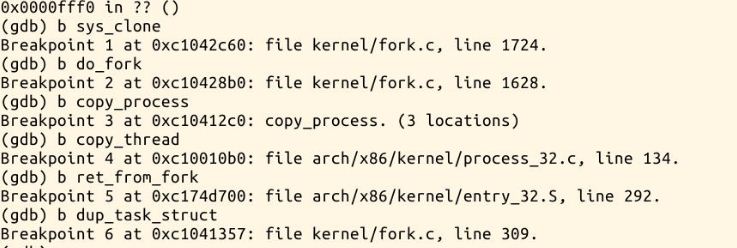
6.先在启动过程中调试,过程有点多,下面简述:

copy_thread:

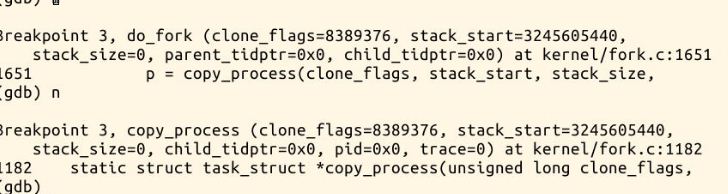
7.在启动完备后,利用fork来调试进程创建的过程。具体结果如下图:

copy_process:

进程调度和预初始化:

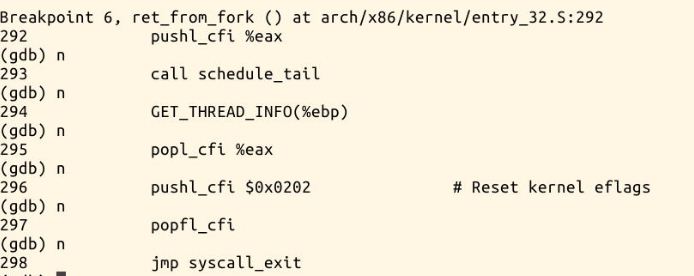
ret_from_fork:汇编执行:
实验分析:
实验参考资料:
http://codelab.shiyanlou.com/xref/linux-3.18.6/arch/x86/syscalls/syscall_32.tbl
http://codelab.shiyanlou.com/xref/linux-3.18.6/arch/x86/kernel/entry_32.S
task_struct数据结构http://codelab.shiyanlou.com/xref/linux-3.18.6/include/linux/sched.h#1235;
task_struct结构的分配使用的是alloc_task_struct宏,该宏就是简单地调用kmem_cache_alloc()从task_struct_cachep缓存中分配。接着会使用alloc_thread_info宏分配thread_info结构。thread_info结构保存了特定于体系结构的汇编语言代码需要访问的那部分进程数据,包括执行域、可抢占标志和当前的CPU等信息。在分配thread_info结构的时,实际调用的是__get_free_pages(),64位下分配的是2个物理页(返回的是虚拟地址)。但是很显然thread_info结构是用不了2页的,剩余的内存其实是用作子进程的内核栈(不是stack_start参数指定的用户栈),可以通过end_of_stack()来计算栈顶位置。在分配完必要的结构后,会调用arch_dup_task_struct()拷贝父进程的task_struct结构到子进程的task_struct结构,如果父进程使用FPU或其他的CPU扩展寄存器,则要将这些寄存器的信息(在prepare_to_copy()中保存的)拷贝到子进程的task_struct结构中。
fork函数对应的内核处理过程sys_clone:
fork()系统调用对应的内核实现为sys_fork(),sys_fork()是对do_fork()的简单封装,sys_fork()的任务是从处理器寄存器中提取由用户空间提供的信息,do_fork()负责进程的复制。fork()和clone()系统调用的入口点sys_vfork()和sys_clone()也是调用的do_fork()。
而其中关系着进程创建的主要是copy_process和copy_thread.copy_process()函数有7个参数,其中我们需要关心的有clone_flags、stack_start和regs。cone_flags是一个标志集合,分为两部分:最低的字节指定了在子进程终止时发送给父进程的信号,其余的高位字节保存了各种真正的复制标志,如CLONE_FS、CLONE_THREAD等。在用户层调用fork()时不能指定标志,所以默认的CLONE_FLAGS的值为SIGCHLD。
dup_task_struct:
tsk = alloc_task_struct_node(node);
ti = alloc_thread_info_node(tsk, node);
err = arch_dup_task_struct(tsk, orig);
int arch_dup_task_struct(struct task_struct *dst, struct task_struct *src)
{
*dst = *src;
if (src->thread.xstate) {
dst->thread.xstate = kmem_cache_alloc(task_xstate_cachep,
GFP_KERNEL);
if (!dst->thread.xstate)
return -ENOMEM;
memcpy(dst->thread.xstate, src->thread.xstate, xstate_size);
}
return 0;
}
子进程的初始化:
进程的用户栈的起始地址存储在task_struct结构的stack_start成员中,在初始化的时候使用的是父进程的用户栈地址,所以在子进程创建时会和父进程使用相同的用户栈,如果有任何一方修改栈的话,会重新拷贝一份,这是基于COW技术,以避免无用的复制。创建子进程为调度器类提供了调度进程的一个切入点,内核会调用sched_fork()函数,以便使调度器有机会对新进程进行设置。sched_fork()会初始化一些和调度相关的成员,并将进程设置为TASK_RUNNING状态。不过此时新的进程还没有放到CPU的执行队列中,所以新的进程不会被调度到。
新进程是从ret_from_fork处开始执行的。对于fork执行处理过程来说,父子进程共享同一段代码空间,”一次调用,两次返回“,其实对于调用fork的父进程来说,如果fork出来的子进程没有得到 调度,那么父进程从fork系统调用返回,同时分析sys_fork知道,fork返回的是子进程的id。再看fork出来的子进程,由 copy_process函数可以看出,子进程的返回地址为ret_from_fork(和父进程在同一个代码点上返回),返回值直接置为0。所以当子进 程得到调度的时候,也从fork返回,返回值为0。ret_from_fork()调用schedule_tail()函数,用存放在栈中的值再装入所有寄存器,并强迫CPU返回到用户态。这样,eax寄存器就装过两个值,一个是子进程的值0,一个是父进程的值——子进程的PID。然后在fork()、vfork()或clone()返回时,新进程将开始执行。在不同的进程中返回不同的值。
执行过程图:

总结:
本次实验对linux创建和修改新进程有进一步的了解。受益匪浅,对fork进程大体了解,对系统进程有了更深入的理解。
Linux中,fork、vfork和clone三个系统调用都是通过调用do_fork来实现进程的创建,而fork()系统调用产生的子进程在系统调用处理过程中从ret_from_fork处开始执行。fork会产生父子进程,在父进程中,返回值是子进程的进程号;在子进程中,返回值为0。因此可通过返回值来判断当前进程是父进程还是子进程。使用fork函数得到的子进程是父进程的一个复制品,它从父进程处复制了整个进程的地址空间,包括进程上下文,进程堆栈,内存信息,打开的文件描述符,信号控制设定,进程优先级,进程组号,当前工作目录,根目录,资源限制,控制终端等。而子进程所独有的只是它的进程号,资源使用和计时器等。可以看出,使用fork函数的代价是很大的,它复制了父进程中的代码段,数据段和堆栈段里的大部分内容,使得fork函数的执行速度并不快。
实际使用过程中,进程的创建和修改会更加复杂,期待下一部分的学习。
参考资料:
1、老师的视频讲解
2、http://www.uml.org.cn/embeded/201307101.asp
3.http://www.linuxidc.com/Linux/2011-02/32282.htm

