
MongoDB学习 (四):创建、读取、更新、删除(CRUD)快速入门
2013-05-01 21:27 Hejin.Wong 阅读(8083) 评论(2) 收藏 举报 1、MongoDB 4个基本操作:创建、读取、更新和删除 。2、Objectld的简介。3、安装python驱动.
1、MongoDB 4个基本操作:创建、读取、更新和删除 。2、Objectld的简介。3、安装python驱动.
本文地址:http://www.cnblogs.com/egger/archive/2013/05/01/3053239.html 欢迎转载 ,请保留此链接๑•́ ₃•̀๑!
本文介绍数据库的4个基本操作:创建、读取、更新和删除(CRUD)。
接下来的数据库操作演示,我们使用MongoDB自带简洁但功能强大的JavaScript shell,MongoDB shell是一个独立的DB客户端(它也是功能完备的JavaScript解释器 可以运行任何JavaScript程序),MongoDB shell的使用介绍请阅读博文《NoSQL学习之路(三):MongoDB Shell的使用》。
CRUD
1.C 创建
insert函数添加一个文档到集合里面。
直接将文档作为参数:
>db.post.insert({"title":"Ex.1"})
或者将文档赋值给变量,变量作为方法的参数。
下面我们添加一篇文章。首先,创建一个局部变量post,JavaScript对象作为文档的内容的赋值给post。里面会有"title","author","content"和"date"等键值。
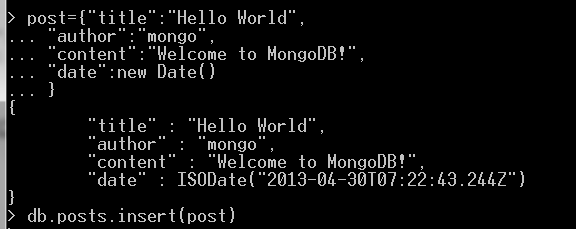
使用count()查询集合中文档条数:
当我们成功的插入一条文档到集合中后,我们会发现多了一个键"_id"和自动生成的ObjectId类型值。[详情:MongoDB的ObjectID]
当插入多个文档到一个集合的时候,请使用批量插入会快一些。批量插入能传递一个由文档构成的数组给数据库。这样避免了许多零碎的请求所带来的开销。
要是只是导入原始数据(例如,从MySQL中导入 ),可以使用命令行工具,如mongoimport,而不是使用批量插入。另一方面,可以用它在存入MongoDB之前对数据做一些小的修整(转换日期成为日期类型,或添加自定义的"_id"所以批量插入对导入数据来说也是有用的。
当执行插入的时候,使用的驱动程序会将数据转换成BSON的形式,然后将其送入数据库。数据库解析BSON,检验是否包含"_id"键并且文档不超过4MB。要查看doc文档转为BSON的大小(以字节为单位),在shell中运行 Object.bsonsize(doc)即可。
MongoDB在插入时并不执行代码,不做别的数据验证,就只是简单地将文档原样存入数据库中.虽然会导致插入无效的数据,但是它能让数据库更加安全,远离注入式攻击。
2.R读取
find会返回集合里面所有的文档。findOne(注意大小写 findone 是无效的)查看一个文档。
find和findOne可以接受査询文档形式的限定条件。这将通过査询限制匹配的文档。使用find时,shell自动显示最多20个匹配的文档,但可以获取更多文档。

3.U更新
更新操作是原子的:若是两个更新同时发生,先到达服务器的先执行,接着执行另外的。
update接受(至少)两个参数:第一个是要更新文档的限定条件,第二个是新的文档。
注意:若是集合中有多个文档匹配查询条件,更新时会查询条件匹配了,然后更新的时候由于第二个参数的存在就产生重复的"_id"值,数据库会报错。限定条件尽量只能筛选出一条文档记录来。
假设决定给我们先前写的文章增加标签,则需要增加一个新的键,对应的值是存放标签的数组。
第一步修改变量post,增加"tags"键:
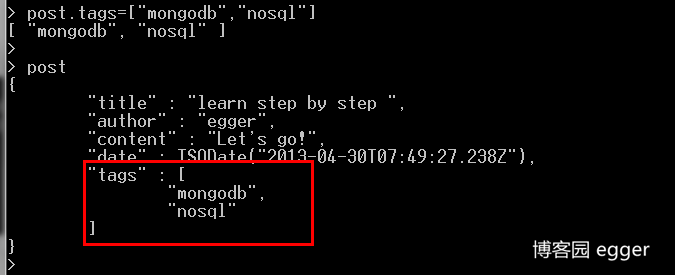
shell输入post回车,post变量中文档值已经包含了tags数组了。

使用update方法更新文档后,文档中便有了"tags"键的内容。
4.D删除
remove用来从数据库中永久性地删除文档,不能回复和撤销。
在不使用参数进行调用的情况下,它会删除一个集合内的所有文档,不会删除集合本身,原有的索引也会保留。。
>db.posts.remove()
它也可以接受一个文档以指定限定条件作为参数。现在集合中只有一条文档记录,我们指定限定条件进行删除操作::

集合现在又是空的了。
如果要清除整个集合,直接删除集合(然后重建索引)会更快,使用drop_collection函数。
>>db.drop_collection(collection_name)
Objectld
官方wiki:http://docs.mongodb.org/manual/reference/object-id/
当我们成功的插入一条文档到集合中后,我们会发现多了一个键"_id"和自动生成的ObjectId类型值。通常会在客户端由驱动程序完成。原因如下:
- MongoDB的设计理念:能从服务器端转移到驱动程序来做的事,就尽量转移。扩展应用层也要比扩展数据库层容易得多。将事务交由客户端来处理,就减轻了数据库扩展的负担。
- 在客户端生成Objectld,驱动程序能够提供更加丰富的API。
集合中每个文档都有唯一的"_id"值,来确保集合里面每个文档都能被唯一标识。Objectld是"_id"的默认类型,它是一种轻量型的,不同的机器都能用全局唯一的同种方法轻量的生成它。mongodb从开始设计就被定义为分布式数据库,处理多个节点是一个核心要求。若采用传统的自增主键策略,在多台服务器上同步自动增加主键既费力又费时。
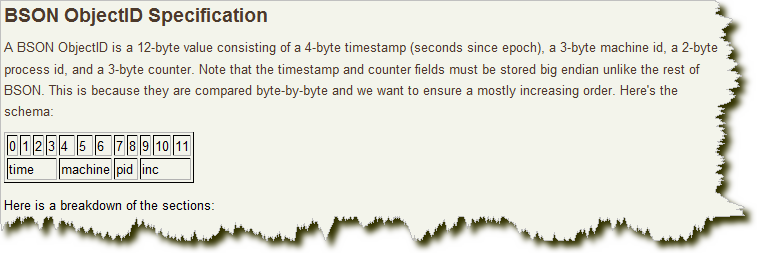
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 时间戳 | 机器名 | PID | 计数器 | ||||||||
ObjectId占用12字节的存储空间,每个字节两位十六进制数字,是一个24位的字符串。由“时间戳” 、“机器名”、“PID号”和“计数器”组成。使用机器名的好处是在分布式环境中能够避免单点计数的性能瓶颈。使用PID号的好处是支持同一机器内运行多个mongod实例。最终采用时间戳和计数器的组合来保证唯一性。
1.时间戳 4个字节。从标准纪元开始,单位为秒。
- 时间戳,与随后的5个字节(机器名+PID)组合起来,提供了秒级别的唯一性。
- 由于时间戳在前,这意味着Objectld大致会按照插入的顺序排列,这对于某些方面很有用,如将其作为索引提高效率,但是这个是没有保证的。
- 这4个字节也隐含了文档创建的时间。绝大多数驱动都会公开一个方法从Objectld获取这个信息。
2.机器名 3个字节。所在主机的唯一标识符。通常是机器主机名的散列值,机器名通过Md5加密后取前三个字节。
3.PID 2个字节。为了确保在同一台机器上并发的多个进程产生的Objectld是唯一的,所以加上进程标识符(PID).注意到每次重启mongod进程后PID号通常会发生变化就可以了。
前9字节保证了同一秒钟不同机器不同进程产生的Objectld是唯一的。
4.计数器 3个字节,表示的取值范围就是256*256*256=16777216。一个自动增加的计数器,确保相同进程同一秒产生的Obj ectld也是不一样的同一秒钟最多允许每个进程拥有2563 (16 777 216)不同的Objectld。
MongoDB的Python驱动
python环境下载: http://www.python.org/download/
pymongo驱动下载: https://pypi.python.org/pypi/pymongo/
window环境下,pymongo选择类型为MS Windows installer。同时注意对应的python版本和系统(32or 64bit).需事先安装好python环境,pymongo检测到python安装路径,只需下一步到完成即可。

然后打开python命令行控制台程序。
下面是官方提供的基本示例:
创建连接
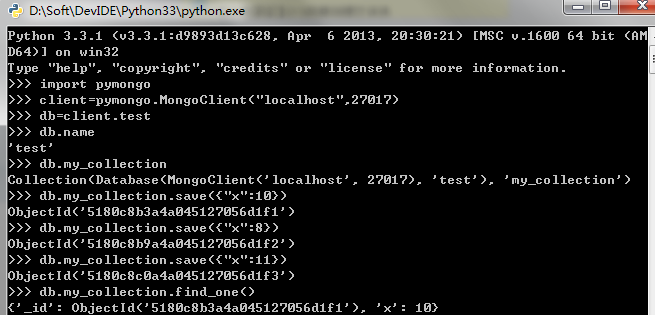
>>> import pymongo >>> client = pymongo.MongoClient("localhost", 27017)
切换数据库 >>> db = client.test
打印数据库名称
>>> db.name u'test' 获取集合
>>> db.my_collection Collection(Database(MongoClient('localhost', 27017), u'test'), u'my_collection')
插入文档 >>> db.my_collection.save({"x": 10}) ObjectId('4aba15ebe23f6b53b0000000') >>> db.my_collection.save({"x": 8}) ObjectId('4aba160ee23f6b543e000000') >>> db.my_collection.save({"x": 11}) ObjectId('4aba160ee23f6b543e000002')
查看集合中的一条文档记录 >>> db.my_collection.find_one() {u'x': 10, u'_id': ObjectId('4aba15ebe23f6b53b0000000')}
下面我们使用python语言往集合中插入1000000条文档记录,然后再清空该集合,并显示清空操作花费时间。
下面演示将使用Python shell.


新建.py文件。
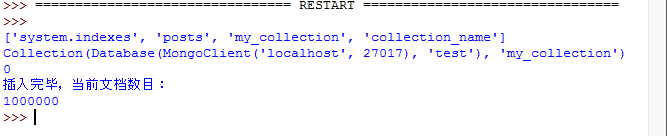
import pymongo client = pymongo.MongoClient("localhost", 27017) db = client.test #查看test数据库中集合信息 print (db.collection_names()) #连接到my_collection集合 print (db.my_collection) #清空my_collection集合文档信息 db.my_collection.remove() #显示my_collection集合中文档数目 print (db.my_collection.find().count()) #插入1000000条文档信息 for i in range(1000000): db.my_collection.insert({"test":"tnt","index":i}) #显示my_collection集合中文档数目 print ('插入完毕,当前文档数目:') print (db.my_collection.find().count())
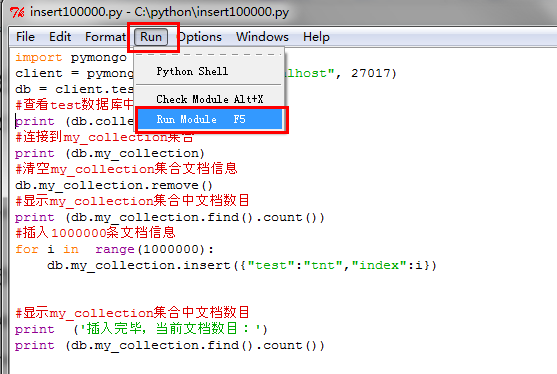
通过Python shell打开该文件,然后按“F5”或者点击“run”->"run module",运行该文件,执行操作。
运行后,python shell 光标闪烁,因为数量较多,等待片刻。

文档成功插入后:
运行下面的代码,执行清空集合操作。
import time from pymongo import Connection db=Connection().test collection = db.my_collection start = time.time() collection.remove() collection.find_one() total = time.time()-start print ("删除1000000条文档共计耗时:%d seconds" % total)
结果如下:
参考:
4. pymongo 使用小结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号