
Hadoop系列之(一):Hadoop单机部署
1. Hadoop介绍
Hadoop是一个能够对海量数据进行分布式处理的系统架构。
Hadoop框架的核心是:HDFS和MapReduce。
HDFS分布式文件系统为海量的数据提供了存储,
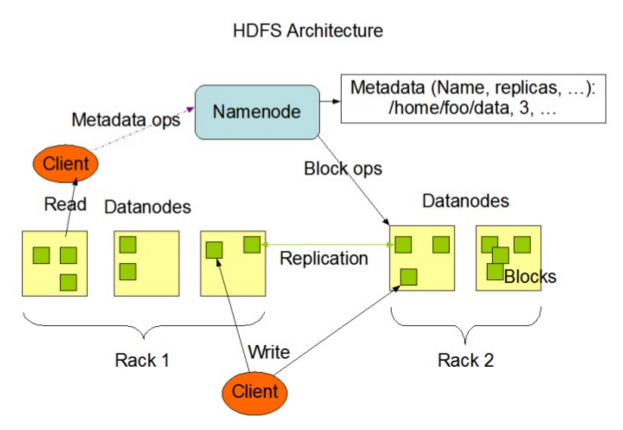
MapReduce分布式处理框架为海量的数据提供了计算。
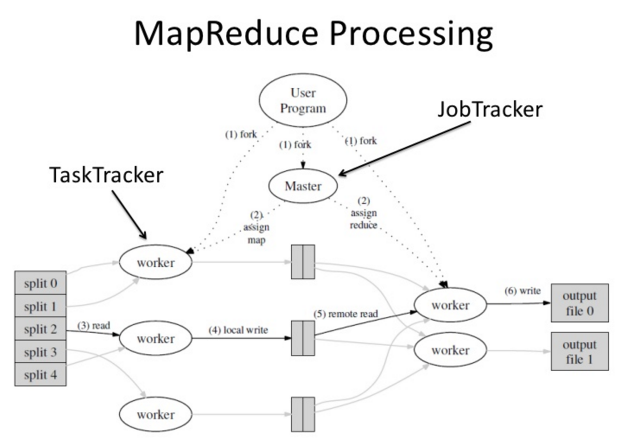
2. Hadoop安装
2.1 安装java
Hadoop是使用JAVA写的,所以需要先安装JAVA环境。
本次安装的是hadoop-2.7.0,需要JDK 7以上版本。
# yum install java-1.7.0-openjdk # yum install java-1.7.0-openjdk-devel
安装后确认
# java –version

2.2 需要ssh和rsync
Linux系统一般都已经默认安装了,如果没有,yum安装。
2.3 下载Hadoop
从官网下载Hadoop最新版2.7.0
# wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz
将hadoop解压到/usr/local/下
# cd /usr/local/ # tar zxvf /root/hadoop-2.7.0.tar.gz
2.4 设置环境变量
设置JAVA的环境变量,JAVA_HOME是JDK的位置
# vi /etc/profile export PATH=/usr/local/hadoop-2.7.0/bin:$PATH export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
让设置生效
# source /etc/profile
设置Hadoop的JAVA_HOME
# cd hadoop-2.7.0/ # vi etc/hadoop/hadoop-env.sh export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
到此,Hadoop的安装就算完成了,接下来进行部署和使用。
3. 单机部署
Hadoop部署方式分三种,Standalone mode、Pseudo-Distributed mode、Cluster mode,其中前两种都是在单机部署。
3.1 standalone mode(本地单独模式)
这种模式,仅1个节点运行1个java进程,主要用于调试。
3.1.1 在Hadoop的安装目录下,创建input目录
# mkdir input
3.1.2 拷贝input文件到input目录下
# cp etc/hadoop/*.xml input
3.1.3 执行Hadoop job
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+'
上面的job是使用hadoop自带的样例,在input中统计含有dfs的字符串。
3.1.4 确认执行结果
# cat output/*

3.1.5 问题点
WARN io.ReadaheadPool: Failed readahead on ifile EBADF: Bad file descriptor
如果出现上面的警告,是因为快速读取文件的时候,文件被关闭引起,也可能是其他bug导致,此处忽略。
3.2 pseudo-distributed mode(伪分布模式)
这种模式是,1个节点上运行,HDFS daemon的 NameNode 和 DataNode、YARN daemon的 ResourceManger 和 NodeManager,分别启动单独的java进程,主要用于调试。
3.2.1 修改设定文件
# vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
# vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3.2.2 设定本机的无密码ssh登陆
# ssh-keygen -t rsa # cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3.2.3 执行Hadoop job
MapReduce v2 叫做YARN,下面分别操作一下这两种job
3.2.4 执行MapReduce job
3.2.4.1 格式化文件系统
# hdfs namenode -format
3.2.4.2 启动名称节点和数据节点后台进程
# sbin/start-dfs.sh

在localhost启动一个1个NameNode和1个DataNode,在0.0.0.0启动第二个NameNode
3.2.4.3 确认
# jps

3.2.4.4 访问NameNode的web页面
http://localhost:50070/

3.2.4.5 创建HDFS
# hdfs dfs -mkdir /user # hdfs dfs -mkdir /user/test
3.2.4.6 拷贝input文件到HDFS目录下
# hdfs dfs -put etc/hadoop /user/test/input
确认,查看
# hadoop fs -ls /user/test/input
3.2.4.7 执行Hadoop job
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep /user/test/input output 'dfs[a-z.]+'
3.2.4.8 确认执行结果
# hdfs dfs -cat output/*

或者从HDFS拷贝到本地查看
# bin/hdfs dfs -get output output # cat output/*
3.2.4.9 停止daemon
# sbin/stop-dfs.sh
3.2.5 执行YARN job
MapReduce V2框架叫YARN
3.2.5.1 修改设定文件
# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
# vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
# vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3.2.5.2 启动ResourceManger和NodeManager后台进程
# sbin/start-yarn.sh

3.2.5.3 确认
# jps

3.2.5.4 访问ResourceManger的web页面
http://localhost:8088/
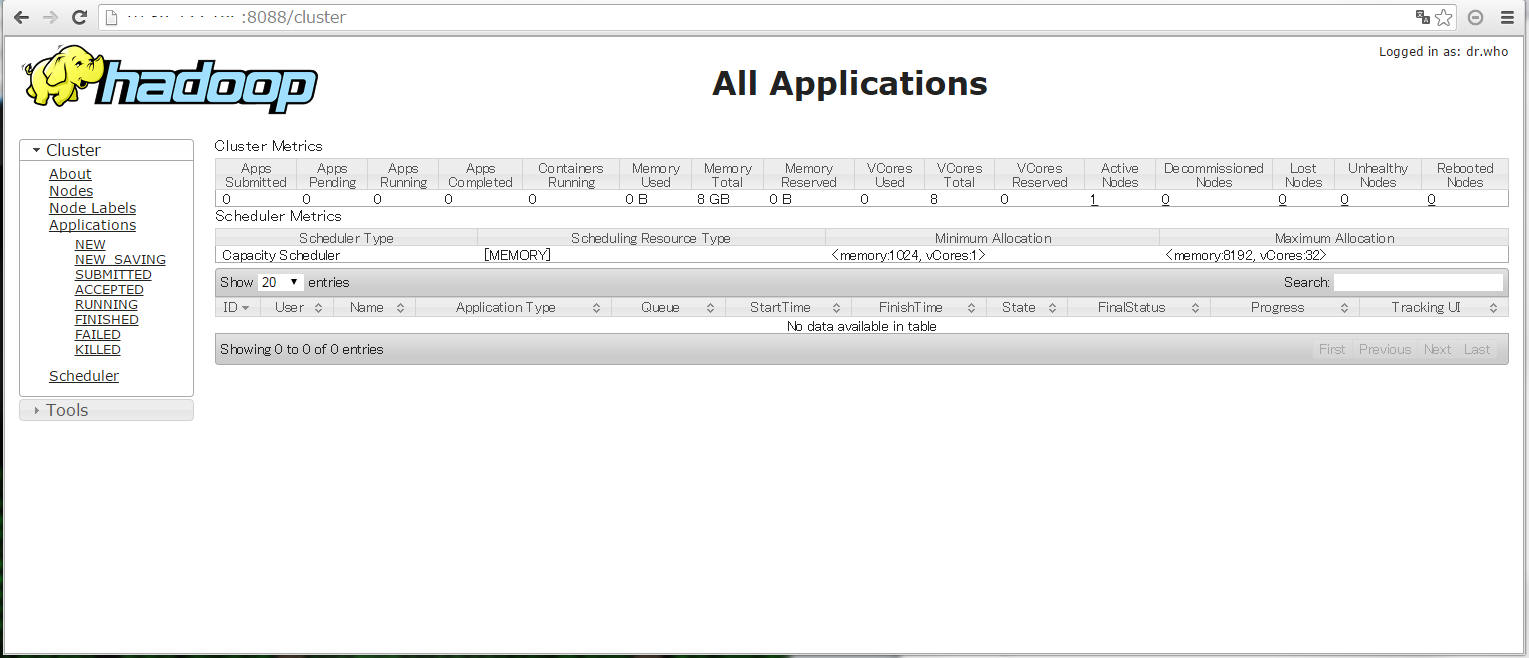
3.2.5.5 执行hadoop job
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep /user/test/input output 'dfs[a-z.]+'
3.2.5.6 确认执行结果
# hdfs dfs -cat output/*
执行结果和MapReduce job相同
3.2.5.7 停止daemon
# sbin/stop-yarn.sh
3.2.5.8 问题点
1. 单节点测试情况下,同样的input,时间上YARN比MapReduce好像慢很多,查看日志发现DataNode上GC发生频率较高,可能是测试用VM配置比较低有关。
2. 出现下面警告,是因为没有启动job history server
java.io.IOException: java.net.ConnectException: Call From test166/10.86.255.166 to 0.0.0.0:10020 failed on connection exception: java.net.ConnectException: Connection refused;
启动jobhistory daemon
# sbin/mr-jobhistory-daemon.sh start historyserver
确认
# jps

访问Job History Server的web页面
http://localhost:19888/

3. 出现下面警告,DataNode日志中有错误,重启服务后恢复
java.io.IOException: java.io.IOException: Unknown Job job_1451384977088_0005
3.3 启动/停止
也可以用下面的启动/停止命令,等同于start/stop-dfs.sh + start/stop-yarn.sh
# sbin/start-all.sh
# sbin/stop-all.sh
3.4 日志
日志在Hadoop安装路径下的logs目录下
4、后记
单机部署主要是为了调试用,生产环境上一般是集群部署,接下来会进行介绍。

