1. 样本和统计量
1.1 样本和统计量
数理统计讨论的问题不一定都是随机现象,比如人口信息的统计、具体数据的测量,它们的结果都是确定的。但实际问题的操作并不是数学所关心的,剥离问题的外壳,这些问题都可以用随机现象来描述,比如人口信息和测量误差都可以用一个正态分布来近似。建立统计的概率模型,正是数理统计区别于广义统计学的关键,为模型定义统一、明确的对象也是任何数学分支的起点。
既然这样,数理统计的研究对象其实还是随机变量,具体问题中所有可能的取值被称为全体,而每一个值称为个体。不同于概率论中研究分布的性质,统计中的分布信息往往是未知的,这样的随机变量习惯写作。为了得到的更多信息,需要采集它的观察值,它们称为样本。一般假定是与同分布的独立随机变量,具体样本值则记作。
统计问题中的主要信息就是样本值,能对它进行的处理只有函数计算,这些函数值被称为样本统计量。统计量不能任意选取,它需要根据实际需要并一般有直观意义。比如最常用的统计量是式(1)中的样本均值和样本方差,它们一般作为分布的均值和方差的估计值。
既然样本是随机变量,统计量自然也是随机变量。如果的期望和方差是,则易知是有期望和方差的随机变量。不难算得,的期望值正好是,所有系数取是合理的,的完整称谓是“修正的样本方差”。我们暂时可以这样“直觉”地解释这个现象:均值是由生成的,它会随着的变动而变动,这就导致真正自由、有效的变量减少了一个。下面马上会回来重新讨论这个问题。
更一般的,比较重要的统计量还有样本原点矩和样本中心距(式(2)),要注意时,样本中心距都需要修正,只不过在很大时可以近似地使用。其中一阶原点矩便是样本均值,二阶中心距便是未修正的样本方差,其它的统计量使用频率不高。
研究统计量是为了获取分布的信息,我们有一个很朴素的想法:当样本数足够多后,应当能绘制出分布函数的图形。根据分布函数的定义特点,可以定义这样一个统计量:它表示满足的样本数,并记,它称为经验分布函数。对于指定的,是随机变量,当把也看作变量时,我们只好叫“随机函数”。不过不用担心概念会变复杂,因为的最大值才是我们要关心的,而它是一个随机变量。数理统计中有著名的格里文科定理(式(3)),它说明以概率收敛于。
1.2 统计量的自由度
在概率论中我们熟知一个结论:如果互相不相关,则的期望、方差可以简单地展开。个对的影响互不相关,这样的统计量十分易于讨论,我们暂且称它的自由度是。下面就来研究一下样本方差的自由度为什么是而不是,不过在此之前,需要先讨论一下随机变量正交变换的性质。
对互不相关的随机变量,设对它们做正交线性变换后得到,则首先容易得到式(4)。然后分别展开和,根据正交性,以及独立同分布,容易有式(5)成立,所以互不相关。这个结论对任何随机变量都成立,且也符合正交变换的一贯性质。
特别地,式(6)左的可以扩展为一个正交变换,利用式(4)便可得到式(6)右的结论。这不仅说明了的自由度为,还可以知道和是不相关的,这个结论非常重要。
对于满足再生性的随机变量,和具有相同的分布类型,且可知满足式(6)的有期望和方差,而其它有期望和方差。特别地,当是正态分布时,可以有式(7)成立,且与相互独立。对的结论,一般写作式(8),右边是一个确定的分布(后面会用到)。
更一般地,对于自由度为的随机变量,其中互不相关。现在把看成的正定二次型,并记行向量。假设可以分解为个半正定二次型之和(式(9)左),且的秩满足。由的秩为且半正定可知,存在的矩阵,使得。
令方阵和,则有(式(9)右),从而,是一个正交矩阵。因为是由正交变换而来,故根据式(5)知互不相关,继而之间是互不相关的。值得提醒的是,当也是一般的半正定二次型时,结论仍然成立,这个条件使用起来会更方便,请自行论证。
现在利用这个结论再讨论的自由度,首先显然有式(10)成立,其中的每一项都是关于的半正定二次型。当半正定二次型具有形式,且还有个线性约束条件时,它本质上是关于个自由变量的正定二次型,从而秩为。这个小结论在判定二次型秩时很有用,比如中设,则有个限制条件,从而的秩为。另外显然式(10)左的秩为,的秩为,满足以上定理的条件,故有不相关。
2. 统计学三大分布
统计量也是随机变量,各种形式的统计量会产生许多新的随机变量,这些变量中的有些是经常出现的,有必要事先对它们做一些介绍。因为正态分布适用的场合最为广泛,这里的统计学三大分布都是基于正态分布的。
2.1 (卡方)分布
在介绍分布之前,先讨论一个更一般的分布。将埃尔朗分布中的扩展为任意正实数,得到的分布(11)称为分布,一般记作。式子中的确保了为密度函数,它被称为函数。函数在实数域是个形函数,它有式(12)的基本结论,由于,它也被看成是阶乘概念的扩展。
分布具有和埃尔朗分布同样的特征函数,并且也满足再生性。这里不打算讨论分布的更多性质,而是关注它的一类特例。假设,可以证明,这是个奇妙的巧合!如果是独立的标准状态分布,利用再生性有式(13)成立,它被称为自由度为的(卡方)分布,记作。

上图是分布的密度函数,时便是,它有两条渐近线,时是指数分布,时分布曲线类似但越来越扁平。容易算得有期望和方差,这就得到分布的期望和方差(式(14))。继续上面对的讨论,由于,可以得到满足式(15)。另外如果是指数函数,显然有。
分布的引入无非是为了讨论样本方差的性质,这个分布中不含有任何未知的参数,这种确定的分布非常便于概率的量化计算。但在量化分析的表达式中,不应该含有未知的参数(样本值、样本容量等属于已知量),这样的表达式一般称为枢轴变量。简单说,枢轴变量由已知量组成,且形成一个确定的分布,这个以后会深入讨论。
一般教材上自由度的概念定义在随机变量上,其中是独立的标准正交分布。如果可以分解为个半正定二次型,且秩的和为,则根据前面关于自由度的结论,变换矩阵为正交矩阵,从而也是互相独立的正交分布。进而是自由度为的卡方分布,且它们互相独立。这个结论称为柯赫伦(Cochran)分解定理,在数理统计中有着非常普遍的应用。
2.2 分布
公式(8)中参数往往是未知的,这会给分析带来困难,这时可以用可以做为的近似。令分别代表式(8)(15)中的变量,消除后就形成变量。这应当是我们要关心的数轴变量,它的分布是确定,为了便于讨论研究,需要为它作个定义。一般地,式(16)中的分布被称为自由度为的分布,记作。下图是其密度函数,有人已经证明,当时,分布收敛于正态分布,这也是符合直觉的。
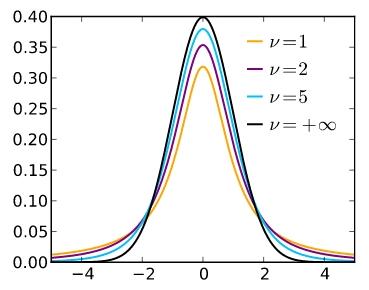
再回到对式(8)(15)的讨论,显然有式(17)成立,这个结论以后经常用到。关于(17)式我想强调一下,式中好像是用取代了,这只是巧合而已,不要忘了其背后原理还是(8)(15)的结合。是因为恰巧被消掉才出现了式(17),遇到更复杂的情况时,要重新仔细计算(下一篇将遇到)。
2.3 分布
还有一种常见的场景,就是比较两个分布的方差比。同样利用近似,并利用公式(15)可以进行类似的讨论。为此,将式(18)中的分布被称为自由度为的分布,记作,下图是它的密度函数。
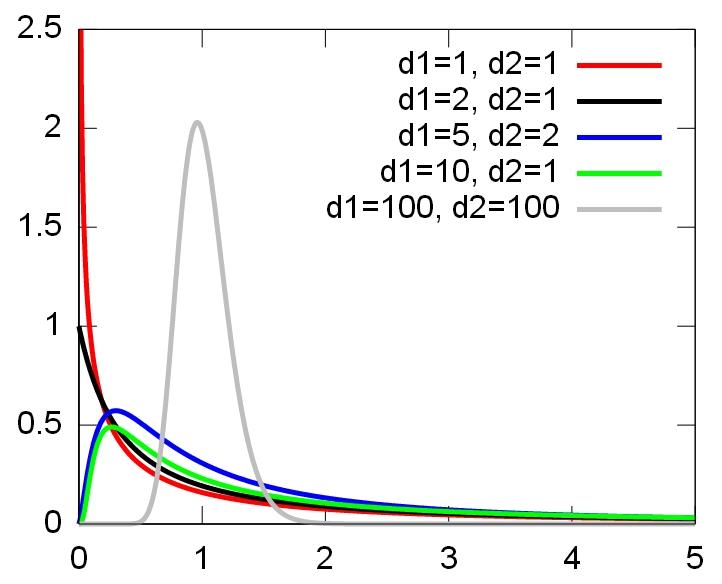
回到方差的比较,设的方差分别为,样本容量分别为,样本方差分别为,容易知道有式(19)成立。
数理统计中使用分布函数时,和概率论中是相反的,即根据概率值来确定随机变量的值。满足的被称为分布的上分位点,对于正态分布和上面的三大分布,上分位点分别记作。其中有式(20)的简单性质,它们在计算和制表中比较有用,证明比较简单,请自行验证。





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架