概率空间是事先给定的,其中样本空间是定义的基础,事件及其概率是我们讨论的对象。那么面对一个给定的概率空间,我们要讨论一些什么问题呢?事件与概率是绑定在一起的,故应把注意力放在事件域上,本篇从两个角度考察事件概率:条件概率和随机变量,它们是概率论中非常基础的概念。
1. 条件概率
1. 1 定义和性质
对于整个事件域,我们不光要知道每个事件的概率,还要知道事件之间的关系。具体讲就是,如果事件发生了,事件会是什么情况呢?当然这里所说的情况还是指“概率”,不过这时的样本空间已经发生了变化,由变成了,自然原本的事件也都变成了与的交集,比如事件对应到事件。我们自然希望新事件域上的概率与之前的“兼容”,可以以作为基准,以作为“可能性”的度量,容易构造出新的概率为。这样的定义不光符合直觉,还容易证明是符合概率的三条要求的。数学上,把式(1)定义为事件关于事件的条件概率,条件概率生成的概率空间具有一般概率空间的所有性质。
先把目光放在概率空间的转移上,可以把上对应的称为先验概率空间,而把上对应的称为后验概率空间。前者表示在没有其它条件下的概率,而后者表示获得了信息后的概率,这也是条件概率名称的由来。条件概率不仅揭示了事件概率随条件的变化,本质上更是揭示了事件之间的关联。如果后验概率与先验概率不同,则表示事件与其它事件之间有一定关系,至于如何度量这个关联,以后会具体讨论。
在很多时候,后验概率反而更容易获取,这时把式(1)改写成式(2)会更有意义,它可以求得“局部”的先验概率。这个思想容易扩展成式(3)的乘法公式,它将复杂的概率分解成了多层简单的概率,在实际计算中非常有用。
式(2)得到的是事件在条件下的片段,如果样本空间可以被分割为可数个互斥条件,并且在每个条件下的概率都容易求得,则不难得到的完整先验概率。式(4)被称为全概率公式,它经常被用在事件可以按条件分类的场景,是也是一个常用的方法。
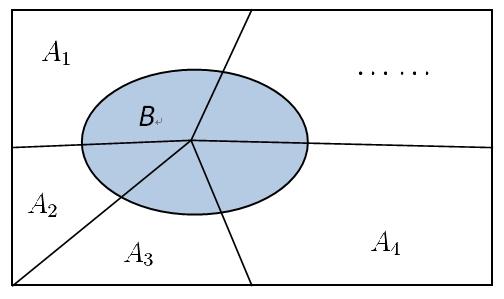
继续观察全概率模型,样本空间被条件划分,而在每个条件下事件发生概率也是清楚的。试想如果事件的确发生了,如何计算条件发生的概率?这是一个后验概率的计算,只不过把条件与结果的顺序颠倒了。利用式(5)不难得到式(6),它就是著名的贝叶斯公式。要想在观察值下估算实际的值,可事先统计实际值的分布、以及对每个实际值的可能观察值。贝叶斯公式为信息判断提供了一种便捷可靠的途径,在工业上被广泛应用。
1.2 统计独立性
前面说过,条件概率反应了事件之间的关系,当条件概率与先验概率不相同时,可以认为条件对事件造成了影响。这里先讨论简单的情景,即条件并没有对事件的概率造成影响,这时有。展开条件概率得到它的等价表达式(7),该式中的关系是对等的,它更适合用来表示“相互”的关系。
对于满足式(7)的事件,一般称之为统计独立的,或简称独立的。其实并不能说独立的两个事件是“无关”的,这里的独立仅适用于统计概率值的关系,这个认识非常重要,它也正是数学严谨性的体现,每个概念都有它明确的所指。“无关”是个很宽泛的概念,在这里是能包含统计独立性的。因此在现实使用中,如果不需要严格论证,就可以把那些明显“无关”的事件看成是独立的,比如两次互不干扰的随机试验。
统计独立性可以简化很多问题的计算,当事件独立时,联合事件的概率可以直接由各个事件概率相乘得到(式(8))。另外容易证明,如果事件独立,则、、也是独立的,这个结论使得独立性更方便使用。
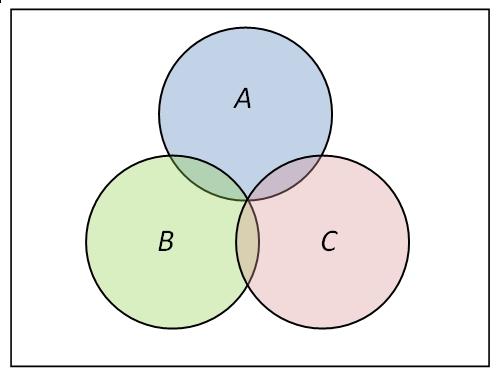
独立性作为事件间的一种“关系”,它有没有传递性呢?你画个文氏图,很容易找出反例,即独立性是与“两者”紧相连的,与第三者并无关联。更甚者,如果你要定义三个事件之间“相互独立”,光有两两独立也是不够的。所谓多个事件的相互独立,自然是想任何事件(或联合事件)都统计独立于其它事件(或联合事件),光有两两独立是不够的。举个三个事件下的反例就足够了,图中两两独立,但显然与不独立。个事件相互独立的条件是式(9)成立,其中是对任意任意选取的个不同事件。
2. 随机变量
2.1 分布函数
概率空间的模型好像很难进一步讨论下去,主要原因是样本空间是一般性的集合。如果把样本空间特殊化成数集,概率就能和函数联系起来,处理起来就能方便得多,而且可以直接利用实变函数的结论。另一方面,实际应用中的样本空间往往就是一个整数集或实数集,这就有了充分的理由来研究实数样本空间的概率问题。不过统一的论证需要测度论的知识,这里仅以离散模型和连续模型为例,阐明随机变量的概念。
先是将样本点对应成实数,也就是说存在上的映射。新的样本空间中,我们自然以一维博雷尔域为事件域。要使得原来的概率在新事件域上仍然是概率,还得要求任何博雷尔点集的原像是一个事件,即满足式,而的概率则应是。这个条件虽然重要,但在实际中往往都是成立的,故以后直接使用新的概率空间。
映射的值是实数,它随着变化,并且还带有概率的属性,一般也把它称为随机变量,简写为,仔细品味的含义对理解随机变量很重要。我们知道,一维博雷尔域可以由所有的开区间生成,因此如果能描述所有上的概率,也就完整描述了随机变量的概率分布。式(10)中的实函数便满足要求,它被称为随机变量的分布函数,也说成服从分布,简记为。
容易证明分布函数满足以下三个性质,它们与概率的三条性质一一对应。实变函数中还能证明:任何满足这三个条件的函数,都是某个随机变量的分布函数,并且随机变量和分布函数相互唯一确定。
(1)单调性:;
(2)规范性:,;
(3)左连续性:。
分布函数为概率空间提供了统一的描述,使得分析的工具更容易使用,但这里我们不进行分析讨论,故还是分成离散和连续两种情况直接讨论。离散随机变量的分布函数是一个跳跃函数,直接讨论它的分布函数会更方便直观。对于连续随机变量的分布函数,一般假定它是光滑的,即存在连续导函数。仔细思考导数的含义,你同样会明白,并不是处的概率,它表示附近的“平均概率”或者“概率密度”,因此也称为的密度函数,显然有式(11)成立。
2.2 随机变量的函数
现在我们已经进入变量和函数的世界,有个很自然的问题是,如果随机变量满足,则如何用的分布函数表示的分布函数?这个问题不难,直接用定义有式(12),但可惜它无法化简,因为非常依赖于的特性。
但在一些特殊情景下,式(12)还可以进一步化简。比如假设是单调递增的,则容易有。有趣的是,如果本身是单调的,则易知随机变量的分布函数是,它是上的均匀分布。这就启发我们,对任何单调的分布函数,我们都可以构造出它的随机变量,而需要的只是一个上的均匀分布。这个结论的条件还可以放宽,有兴趣的自行研究,它被称为随机变量的存在定理。
当有密度函数,而有连续导函数时,容易证明的密度函数满足式(13)。如果你理解密度函数的意义,其实式(13)有着很直观的解释,就是表示斜率对密度的影响。根据这个思想,如果的导函数分段连续,可以将公式(13)应用在每个分段中,然后每段的密度函数相加即可。
当然还可以讨论多元函数的随机变量,但一般情况下也很难得到简单的分布函数,只能针对特殊情况分别讨论。比如当相互独立时,你可以求得的分布函数(14)。它被称为卷积公式,卷积的概念在数学里非常常见。还可以求得的分布函数(15),该式在数理统计中比较有用。
• 设分别是独立随机变量中的最大值和最小值,试求的分布函数。
2.3 随机向量
有时候,随机事件的值是一个多维向量,它被称为随机向量或维随机变量。容易定义的(联合)分布函数如式(16),它在每一维都是递增的。但在每一维都递增的函数(同时满足分布函数其它特点),不一定是分布函数。拿二维空间为例,只有满足空间上的递增性(而不是单个维度),才能成为分布函数,因此还必须有式(17)成立。
随机向量也可以定义密度函数,而且在每一维都有式(18)的边际分布(分别是离散和连续)。但同样的边际分布却可能有不同的分布函数,主要是因为每一维的随机变量之间可能不是独立的。这就为我们提供了另一个视角看随机向量,它是讨论随机变量关系的一个很好的场所,就像条件概率要借助定义一样。
不管是离散还是连续场景,式(19)定义的关于的条件分布都是合理的。可以把条件分布的概率分布(或密度函数)简写为,容易推导出它有表达式(20)(离散和连续)。自然地,满足式(21)的随机变量被称为相互独立的,它们的分布函数和密度函数可以拆分为边际分布之积,且由边际分布唯一确定(式(22)。
最后再来看随机向量的变换,利用微积分中多元函数变换的结论,如果的维度相同且存在逆函数,则有式(23)成立,其中是向量变换的雅克比行列式。这个结论可以对随机向量进行变换,从而得到更便于处理的分布(比如各维度相互独立)。还有一个作用是计算随机变量的多元函数的分布,步骤是先添加个辅助的多元函数,求得联合密度函数(23)后再求的边际分布。





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架