
Hadoop学习笔记—17.Hive框架学习
 Hive 是建立在 Hadoop 基础上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 QL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。Hive 是 SQL解析引擎,它将SQL语句转译成Map/Reduce Job然后在Hadoop执行。Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在Map/Reduce Job里使用这
Hive 是建立在 Hadoop 基础上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 QL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。Hive 是 SQL解析引擎,它将SQL语句转译成Map/Reduce Job然后在Hadoop执行。Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在Map/Reduce Job里使用这
一、Hive:一个牛逼的数据仓库
1.1 神马是Hive?

Hive 是建立在 Hadoop 基础上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 QL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。

Hive 是 SQL解析引擎,它将SQL语句转译成Map/Reduce Job然后在Hadoop执行。Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在Map/Reduce Job里使用这些数据。
1.2 Hive的系统结构

由上图可知,HDFS和Mapreduce是Hive架构的根基。Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor),这些组件可以分为两大类:服务端组件和客户端组件。
(1)客户端组件:
①CLI:command line interface,命令行接口。
②Thrift客户端:上面的架构图里没有写上Thrift客户端,但是Hive架构的许多客户端接口是建立在Thrift客户端之上,包括JDBC和ODBC接口。
③WEBGUI:Hive客户端提供了一种通过网页的方式访问Hive所提供的服务。这个接口对应Hive的hwi组件(hive web interface),使用前要启动hwi服务。
(2)服务端组件:
①Driver组件:该组件包括Complier、Optimizer和Executor,它的作用是将我们写的HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架。
②Metastore组件:元数据服务组件,这个组件存储hive的元数据,hive的元数据存储在关系数据库里,hive支持的关系数据库有derby、mysql。元数据对于hive十分重要,因此hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性。
③Thrift服务:Thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
(3)底层根基:
—>Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)
二、Hive的基本安装
2.1 准备工作
(1)下载hive安装包,这里使用的是0.9.0版本,已经上传到了网盘(http://pan.baidu.com/s/1sj0qnpV);
(2)通过FTP工具上传到虚拟机hadoop-master中,可以是XShell、CuteFTP等工具;
2.2 开始安装
(1)解压: tar -zvxf hive-0.9.0.tar.gz ,重命名:mv hive-0.9.0 hive
(2)加入环境变量配置文件中:vim /etc/profile
export HIVE_HOME=/usr/local/hive
export PATH=.:$HADOOP_HOME/bin:$HIVE_HOME/bin:$PIG_HOME/bin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATH
最后当然别忘了使环境变量生效:source /etc/profile
(3)简单配置Hive:进入$HIVE_HOME/conf目录下,修改默认模板
Step 2.3.1:
在目录$HIVE_HOME/conf/下,执行命令mv hive-default.xml.template hive-site.xml进行重命名
在目录$HIVE_HOME/conf/下,执行命令mv hive-env.sh.template hive-env.sh进行重命名Step 2.3.2:
修改hadoop的配置文件hadoop-env.sh,修改内容如下:
export HADOOP_CLASSPATH=.:$CLASSPATH:$HADOOP_CLASSPATH:$HADOOP_HOME/bin在目录$HIVE_HOME/bin下面,修改文件hive-config.sh,增加以下内容:
export JAVA_HOME=/usr/local/jdk
export HIVE_HOME=/usr/local/hive
export HADOOP_HOME=/usr/local/hadoop
(4)简单安装MySQL:这里使用的版本是5.5.31,已经上传至了网盘(http://pan.baidu.com/s/1gdJ78aB)
Step 2.4.1:
删除Linux上已经安装的mysql相关库信息: rpm -e xxxxxxx --nodeps
执行命令 rpm -qa |grep mysql 检查是否删除干净
Step 2.4.2:
执行命令 rpm -i MySQL-server-5.5.31-2.el6.i686.rpm 安装mysql服务端
启动 mysql 服务端,执行命令 mysqld_safe &
Step 2.4.3:
执行命令 rpm -i MySQL-client-5.5.31-2.el6.i686.rpm 安装mysql客户端
执行命令 mysql_secure_installation 设置root用户密码
(5)使用 MySQL 作为 Hive 的 metastore:
Step 2.5.1:
把mysql的jdbc驱动放置到hive的lib目录下:cp mysql-connector-java-5.1.10.jar /usr/local/hive/lib
Step 2.5.2:
修改hive-site.xml文件,修改内容如下:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop-master:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>admin</value>
</property>
三、Hive的基本使用
3.1 启动Hadoop
由1.2的图可知,HDFS和Mapreduce是Hive架构的根基。因此,我们得先启动Hadoop,才能正确使用Hive。
3.2 Hive的CLI命令行接口
(1)内部表:与数据库中的 Table 在概念上是类似,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 test,它在 HDFS 中的路径为:/ warehouse/test。 warehouse是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录;
创建表
hive>CREATE TABLE t1(id int); // 创建内部表t1,只有一个int类型的id字段
hive>CREATE TABLE t2(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; // 创建内部表t2,有两个字段,它们之间通过tab分隔
加载数据
hive>LOAD DATA LOCAL INPATH '/root/id' INTO TABLE t1; // 从本地文件加载
hive>LOAD DATA INPATH '/root/id' INTO TABLE t1; // 从HDFS中加载查看数据
hive>select * from t1; // 跟SQL语法类似
hive>select count(*) from t1; // hive也提供了聚合函数供使用
删除表
hive>drop table t1;
(2)分区表:所谓分区(Partition) 对应于数据库的 Partition 列的密集索引。在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。例如:test表中包含 date 和 city 两个 Partition,则对应于date=20130201, city = bj 的 HDFS 子目录为:/warehouse/test/date=20130201/city=bj。而对应于date=20130202, city=sh 的HDFS 子目录为:/warehouse/test/date=20130202/city=sh。
创建表
hive>CREATE TABLE t3(id int) PARTITIONED BY (day int);
加载表
hive>LOAD DATA LOCAL INPATH '/root/id' INTO TABLE t1 PARTITION (day=22);

(3)桶表(Hash 表):桶表是对数据进行哈希取值,然后放到不同文件中存储。数据加载到桶表时,会对字段取hash值,然后与桶的数量取模。把数据放到对应的文件中。
创建表
hive>create table t4(id int) clustered by(id) into 4 buckets; // 创建一个桶表t4,根据id进行哈希取值,并设置4个桶来存储
设置允许进行分桶
hive>set hive.enforce.bucketing = true;
插入数据
hive>insert into table t4 select id from t3;
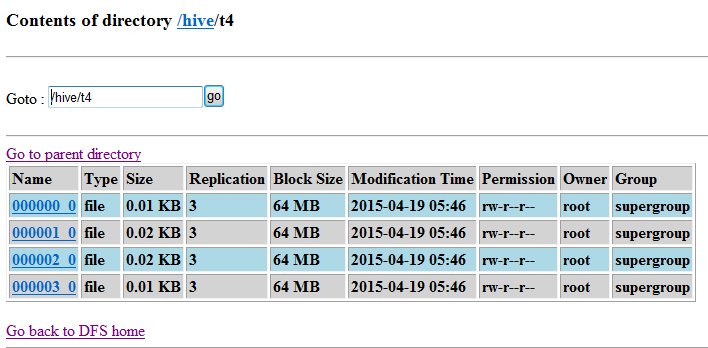
(4)外部表:它和 内部表 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。外部表主要指向已经在 HDFS 中存在的数据,可以创建 Partition。
在HDFS中的external目录下创建一个数据文件:vim ids.txt
创建一个外部表:hive>create external table t5(id int) location '/external';
外部表与内部表的差异:
①内部表 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除;②外部表 只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个 外部表 时,仅删除该链接;
(5)视图操作:和关系数据库中的视图一个概念,可以向用户集中展现一些数据,屏蔽一些数据,提高数据库的安全性。
创建视图
hive> create view v1 as select * from t1;
查询视图
hive> select * from v1;
(6)查询操作:在Hive中,查询分为三种:基于Partition的查询、LIMIT Clause查询、Top N查询。
①基于Partition的查询:一般 SELECT 查询是全表扫描。但如果是分区表,查询就可以利用分区剪枝(input pruning)的特性,类似“分区索引“”,只扫描一个表中它关心的那一部分。Hive 当前的实现是,只有分区断言(Partitioned by)出现在离 FROM 子句最近的那个WHERE 子句中,才会启用分区剪枝。例如,如果 page_views 表(按天分区)使用 date 列分区,以下语句只会读取分区为‘2008-03-01’的数据。
SELECT page_views.* FROM page_views WHERE page_views.date >= '2013-03-01' AND page_views.date <= '2013-03-01'
②LIMIT Clause查询:Limit 可以限制查询的记录数。查询的结果是随机选择的。下面的查询语句从 t1 表中随机查询5条记录:
SELECT * FROM t1 LIMIT 5
③Top N查询:和关系型数据中的Top N一样,排序后取前N个显示。下面的查询语句查询销售记录最大的 5 个销售代表:
SET mapred.reduce.tasks = 1
SELECT * FROM sales SORT BY amount DESC LIMIT 5
(7)连接操作:和关系型数据库中的各种表连接操作一样,在Hive中也可以进行表的内连接、外连接一类的操作:
导入ac信息表hive> create table acinfo (name string,acip string) row format delimited fields terminated by '\t' stored as TEXTFILE;
hive> load data local inpath '/home/acinfo/ac.dat' into table acinfo;
内连接select b.name,a.* from dim_ac a join acinfo b on (a.ac=b.acip) limit 10;
左外连接select b.name,a.* from dim_ac a left outer join acinfo b on a.ac=b.acip limit 10;
3.3 Hive的Java API接口
(1)准备工作
①在服务器端启动Hive外部访问服务(不是在hive命令行模式下,而是普通模式下):hive --service hiveserver >/dev/null 2>/dev/null &

②导入Hive的相关jar包集合:
(2)第一个Hive程序:读取我们刚刚创建的内部表t1


package hive; import java.sql.Statement; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; public class HiveApp { /** * 第一个hive java api程序 * @throws Exception */ public static void main(String[] args) throws Exception { Class.forName("org.apache.hadoop.hive.jdbc.HiveDriver"); Connection con = DriverManager.getConnection( "jdbc:hive://hadoop-master/default", "", ""); Statement stmt = con.createStatement(); String querySQL = "SELECT * FROM default.t1"; ResultSet res = stmt.executeQuery(querySQL); while (res.next()) { System.out.println(res.getString(1)); } } }
调试结果:
四、Hive的执行流程

参考资料
(1)吴超,《深入浅出Hadoop》:http://www.superwu.cn/
(2)夏天的森林,《大数据时代的技术Hive:Hive介绍》:http://www.cnblogs.com/sharpxiajun/archive/2013/06/02/3114180.html
(3)哥不是小萝莉,《那些年使用Hive踩过的坑》:http://www.cnblogs.com/smartloli/p/4288493.html


