
Hadoop学习笔记—2.不怕故障的海量存储:HDFS基础入门
 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—因此,迫切需要一种系统来管理多台机器上的文件,于是就产生了分布式文件管理系统,英文名成为DFS(Distributed File System)。那么,什么是分布式文件系统?简而言之,就是一种允许文件通过网络在多台主机上分享的文件系统,可以让多个机器上的多个用户分享文件和存储空间。
随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—因此,迫切需要一种系统来管理多台机器上的文件,于是就产生了分布式文件管理系统,英文名成为DFS(Distributed File System)。那么,什么是分布式文件系统?简而言之,就是一种允许文件通过网络在多台主机上分享的文件系统,可以让多个机器上的多个用户分享文件和存储空间。
一.HDFS出现的背景
随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多台机器上的文件,于是就产生了分布式文件管理系统,英文名成为DFS(Distributed File System)。
那么,什么是分布式文件系统?简而言之,就是一种允许文件通过网络在多台主机上分享的文件系统,可以让多个机器上的多个用户分享文件和存储空间。它最大的特点是“通透性”,DFS让实际上是通过网络来访问文件的动作,由用户和程序看来,就像是访问本地的磁盘一般(In other words,使用DFS访问数据,你感觉不到是访问远程不同机器上的数据)。
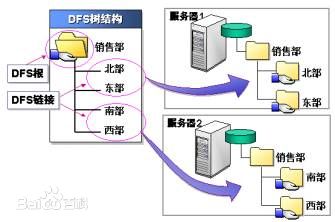
图1.一个典型的DFS示例
二.深入了解HDFS原理
作为Hadoop的核心技术之一,HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)是分布式计算中数据存储管理的基础。它所具有的高容错、高可靠、高可扩展性、高吞吐率等特性为海量数据提供了不怕故障的存储,也为超大规模数据集(Large Data Set)的应用处理带来了很多便利。

图2.Hadoop HDFS的LOGO
提到HDFS,不得不说Google的GFS。正是Google发表了关于GFS的论文,才有了HDFS这个关于GFS的开源实现。
2.1 设计前提与目标
(1)硬件错误是常态而不是异常;(最核心的设计目标—>HDFS被设计为运行在众多的普通硬件上,所以硬件故障是很正常的。因此,错误检测并快速恢复是HDFS最核心的设计目标)
(2)流式数据访问;(HDFS更关注数据访问的高吞吐量)
(3)大规模数据集;(HDFS的典型文件大小大多都在GB甚至TB级别)
(4)简单一致性模型;(一次写入,多次读取的访问模式)
(5)移动计算比移动数据更为划算;(对于大文件来说,移动计算比移动数据的代价要低)
2.2 HDFS的体系结构
HDFS是一个主/从(Master/Slave)式的结构,如下图所示。
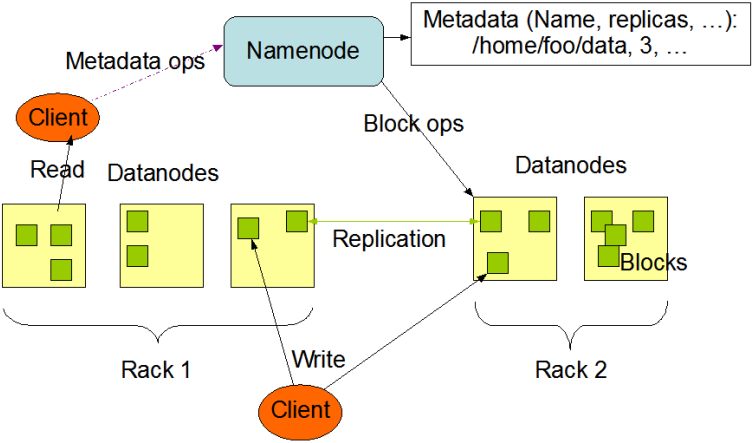
图3.HDFS的基本架构
从最终用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件执行CRUD(增删查改)操作。但由于分布式存储的性质,HDFS拥有一个NameNode和一些DataNodes。NameNode管理文件系统的元数据,DataNode存储实际的数据。客户端通过同NameNode和DataNode的交互访问文件系统→客户端联系NameNode以获取文件的元数据,而真正的I/O操作是直接和DataNode进行交互的。
下面我们再来看看HDFS的读操作和写操作的流程:
①读操作

图4.HDFS的读操作
客户端要访问一个文件,首先,客户端从NameNode中获得组成该文件数据块位置列表,即知道数据块被存储在哪几个DataNode上;然后,客户端直接从DataNode上读取文件数据。在此过程中,NameNode不参与文件的传输。
②写操作

图5.HDFS的写操作
客户端首先需要向NameNode发起写请求,NameNode会根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。最后,Client(开发库)将文件划分为多个文件块,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
下面我们看看NameNode和DataNode扮演什么角色,有什么具体的作用:
(1)NameNode
NameNode的作用是管理文件目录结构,是管理数据节点的。NameNode维护两套数据:一套是文件目录与数据块之间的关系,另一套是数据块与节点间的关系。前一套是静态的,是存放在磁盘上的,通过fsimage和edits文件来维护;后一套数据时动态的,不持久化到磁盘,每当集群启动的时候,会自动建立这些信息。
(2)DataNode
毫无疑问,DataNode是HDFS中真正存储数据的。这里要提到一点,就是Block(数据块)。假设文件大小是100GB,从字节位置0开始,每64MB字节划分为一个Block,以此类推,可以划分出很多的Block。每个Block就是64MB(也可以自定义设置Block大小)。
(3)典型部署
HDFS的一个典型部署是在一个专门的机器上运行NameNode,集群中的其他机器各运行一个DataNode。(当然,也可以在运行NameNode的机器上同时运行DataNode,或者一个机器上运行多个DataNode)一个集群中只有一个NameNode(但是单NameNode存在单点问题,在Hadoop 2.x版本之后解决了这个问题)的设计大大简化了系统架构。
2.3 保障HDFS的可靠性措施
HDFS具备了较为完善的冗余备份和故障恢复机制,可以实现在集群中可靠地存储海量文件。
(1)冗余备份:HDFS将每个文件存储成一系列的数据块(Block),默认块大小为64MB(可以自定义配置)。为了容错,文件的所有数据块都可以有副本(默认为3个,可以自定义配置)。当DataNode启动的时候,它会遍历本地文件系统,产生一份HDFS数据块和本地文件对应关系的列表,并把这个报告发送给NameNode,这就是报告块(BlockReport),报告块上包含了DataNode上所有块的列表。
(2)副本存放:HDFS集群一般运行在多个机架上,不同机架上机器的通信需要通过交换机。通常情况下,副本的存放策略很关键,机架内节点之间的带宽比跨机架节点之间的带宽要大,它能影响HDFS的可靠性和性能。HDFS采用一种称为机架感知(Rack-aware)的策略来改进数据的可靠性、可用性和网络带宽的利用率。在大多数情况下,HDFS副本系数是默认为3,HDFS的存放策略是将一个副本存放在本地机架节点上,一个副本存放在同一个机架的另一个节点上,最后一个副本放在不同机架的节点上。这种策略减少了机架间的数据传输,提高了写操作的效率。机架的错误远远比节点的错误少,所以这种策略不会影响到数据的可靠性和可用性。

图6.副本存放的策略
(3)心跳检测:NameNode周期性地从集群中的每个DataNode接受心跳包和块报告,NameNode可以根据这个报告验证映射和其他文件系统元数据。收到心跳包,说明该DataNode工作正常。如果DataNode不能发送心跳信息,NameNode会标记最近没有心跳的DataNode为宕机,并且不会给他们发送任何I/O请求。
(4)安全模式
(5)数据完整性检测
(6)空间回收
(7)元数据磁盘失效
(8)快照(HDFS目前还不支持)
三.HDFS常用Shell操作
(1)列出文件目录:hadoop fs -ls 目录路径
查看HDFS根目录下的目录:hadoop fs -ls / 
递归查看HDFS根目录下的目录:hadoop fs -lsr /

(2)在HDFS中创建文件夹:hadoop fs -mkdir 文件夹名称
在根目录下创建一个名称为di的文件夹:

(3)上传文件到HDFS中:hadoop fs -put 本地源路径 目标存放路径
将本地系统中的一个log文件上传到di文件夹中:hadoop fs -put test.log /di
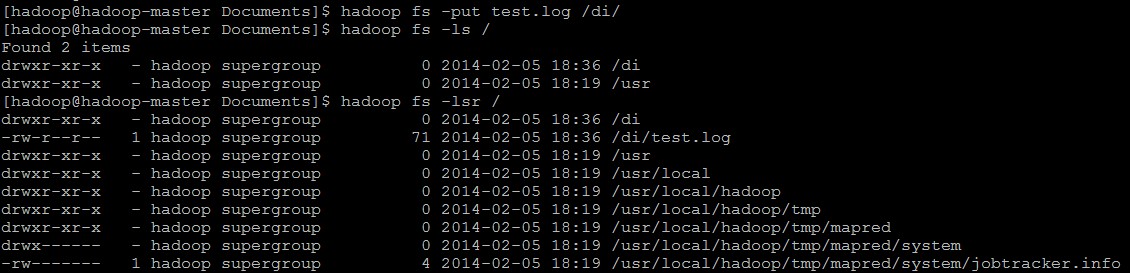
*PS:我们通过Hadoop Shell上传的文件是存放在DataNode的Block(数据块)中的,通过Linux Shell是看不到文件的,只能看到Block。因此,可以用一句话来描述HDFS:把客户端的大文件存放在很多节点的数据块中。
(4)从HDFS中下载文件:hadoop fs -get HDFS文件路径 本地存放路径
将刚刚上传的test.log下载到本地的Desktop文件夹中:hadoop fs -get /di/test.log /home/hadoop/Desktop

(5)直接在HDFS中查看某个文件:hadoop fs -text(-cat) 文件存放路径
在HDFS查看刚刚上传的test.log文件:hadoop fs -text /di/test.log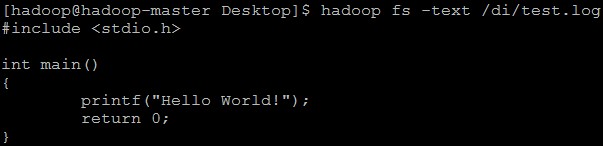
(6)删除在HDFS中的某个文件(夹):hadoop fs -rm(r) 文件存放路径
删除刚刚上传的test.log文件:hadoop fs -rm /di/test.log

删除HDFS中的di文件夹:hadoop fs -rmr /di

(7)善用help命令求帮助:hadoop fs -help 命令
查看ls命令的帮助:hadoop fs -help ls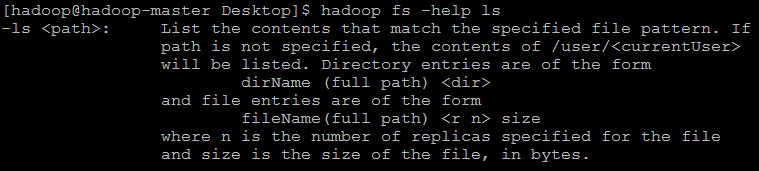
四.使用Java操作HDFS
我们在工作中写完的各种代码是在服务器中运行的,HDFS的操作代码也不例外。在开发阶段,我们使用Windows下的Eclipse作为开发环境,访问运行在虚拟机中的HDFS,也就是通过在本地的Eclipse中的Java代码访问远程Linux中的HDFS。
在本地的开发调试过程中,要使用宿主机中的Java代码访问客户机中的HDFS,需要确保以下几点:
宿主机和虚拟机的网络能否互通?确保宿主机和虚拟机中的防火墙都关闭!确保宿主机与虚拟机中的jdk版本一致!
4.1 准备工作:
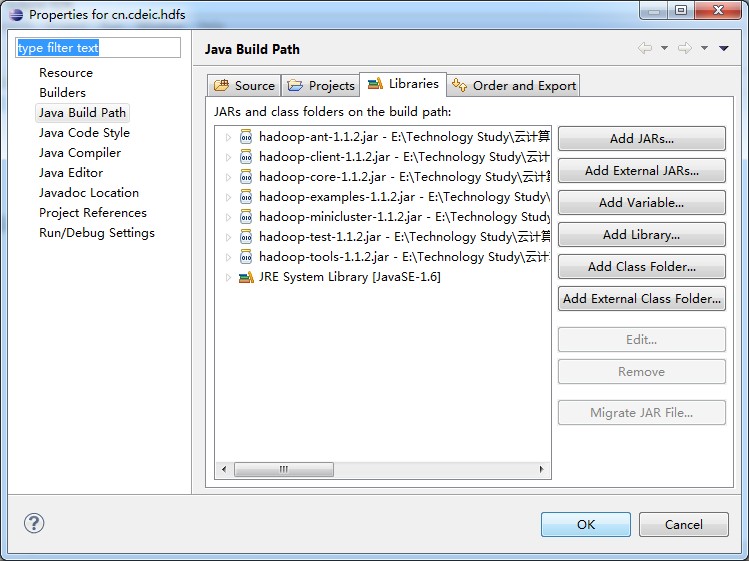
(1)导入依赖jar包,如下图所示
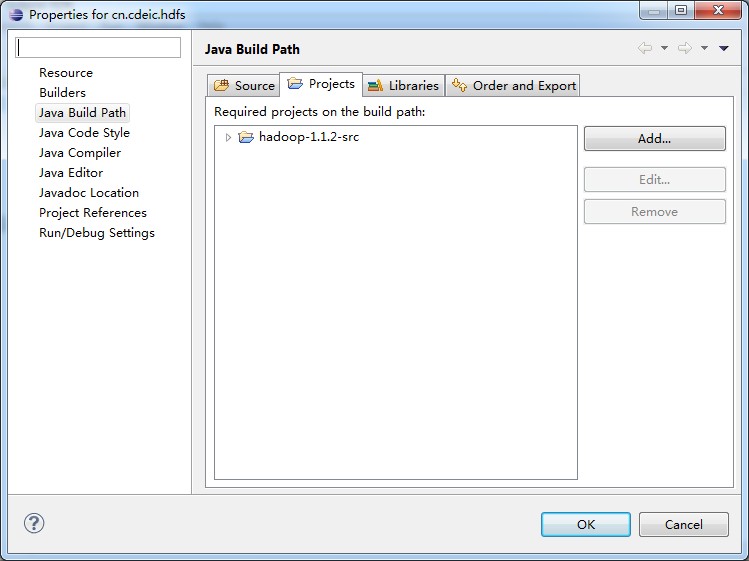
(2)关联hadoop源码项目,如下图所示
4.2 第一个Java-HDFS程序
(1)定义HDFS_PATH:public static final String HDFS_PATH = "hdfs://hadoop-master:9000/testdir/testfile.log";
(2)让URL类型识别hdfs://(URL类型默认只识别http://):URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
(3)具体详细代码如下:


1 package hdfs; 2 3 import java.io.InputStream; 4 import java.net.MalformedURLException; 5 import java.net.URL; 6 7 import org.apache.hadoop.fs.FsUrlStreamHandlerFactory; 8 import org.apache.hadoop.io.IOUtils; 9 10 public class firstApp { 11 12 public static final String HDFS_PATH = "hdfs://hadoop-master:9000/testdir/testfile.log"; 13 14 /** 15 * @param args 16 * @throws MalformedURLException 17 */ 18 public static void main(String[] args) throws Exception { 19 // TODO Auto-generated method stub 20 URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory()); 21 final URL url = new URL(HDFS_PATH); 22 final InputStream in = url.openStream(); 23 /** 24 * @params in 输入流 25 * @params out 输出流 26 * @params buffersize 缓冲区大小 27 * @params close 是否自动关闭流 28 */ 29 IOUtils.copyBytes(in, System.out, 1024, true); 30 } 31 32 }
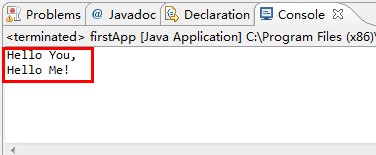
(4)运行结果(后面不再贴运行结果图):
4.3 对HDFS进行CRUD编程
(1)获得万能的大神对象:final FileSystem fileSystem = FileSystem.get(new URI(HDFS_PATH),new Configuration());
(2)调用HDFS API进行CRUD操作,详情见下代码
public class FileSystemApp { private static final String HDFS_PATH = "hdfs://hadoop-master:9000/testdir/"; private static final String HDFS_DIR = "/testdir/dir1"; public static void main(String[] args) throws Exception { FileSystem fs = getFileSystem(); // 01.创建文件夹 对应shell:mkdir createDirectory(fs); // 02.删除文件 对应shell:hadoop fs -rm(r) xxx deleteFile(fs); // 03.上传文件 对应shell:hadoop fs -input xxx uploadFile(fs); // 04.下载文件 对应shell:hadoop fs -get xxx xxx downloadFile(fs); // 05.浏览文件夹 对应shell:hadoop fs -lsr / listFiles(fs,"/"); } private static void listFiles(FileSystem fs,String para) throws IOException { final FileStatus[] listStatus = fs.listStatus(new Path(para)); for (FileStatus fileStatus : listStatus) { String isDir = fileStatus.isDir() ? "Directory" : "File"; String permission = fileStatus.getPermission().toString(); short replication = fileStatus.getReplication(); long length = fileStatus.getLen(); String path = fileStatus.getPath().toString(); System.out.println(isDir + "\t" + permission + "\t" + replication + "\t" + length + "\t" + path); if(isDir.equals("Directory")){ listFiles(fs, path); } } } private static void downloadFile(FileSystem fs) throws IOException { final FSDataInputStream in = fs.open(new Path(HDFS_PATH + "check.log")); final FileOutputStream out = new FileOutputStream("E:\\check.log"); IOUtils.copyBytes(in, out, 1024, true); System.out.println("Download File Success!"); } private static void uploadFile(FileSystem fs) throws IOException { final FSDataOutputStream out = fs.create(new Path(HDFS_PATH + "check.log")); final FileInputStream in = new FileInputStream("C:\\CheckMemory.log"); IOUtils.copyBytes(in, out, 1024, true); System.out.println("Upload File Success!"); } private static void deleteFile(FileSystem fs) throws IOException { fs.delete(new Path(HDFS_DIR), true); System.out.println("Delete File:" + HDFS_DIR + " Success!"); } private static void createDirectory(FileSystem fs) throws IOException { fs.mkdirs(new Path(HDFS_DIR)); System.out.println("Create Directory:" + HDFS_DIR + " Success!"); } private static FileSystem getFileSystem() throws IOException, URISyntaxException { return FileSystem.get(new URI(HDFS_PATH), new Configuration()); } }
参考文献与资料
(1)传智播客Hadoop从入门到工作视频教程第二季:http://bbs.itcast.cn/thread-21310-1-1.html
(2)刘鹏教授,《实战Hadoop:开启通向云计算的捷径》:http://item.jd.com/10830089.html
(3)吴超,《Hadoop的底层架构——RPC机制》:http://www.superwu.cn/2013/08/05/360
(4)zy19982004,《Hadoop学习十一:Hadoop-HDFS RPC总结》:http://zy19982004.iteye.com/blog/1875969


 浙公网安备 33010602011771号
浙公网安备 33010602011771号