

转载自 http://download.csdn.net/source/858994
源地址下是 Word 文档,这里转换成HTML 格式
Lucene源代码剖析
3.3.3 Term频率数据(.frq)
Term频率数据文件(.frq文件)存储容纳了每一个term的文档列表,以及该term出现在该文档中的频率(出现次数frequency,如果omitTf设置为fals时才存储)。
|
版本 |
包含的项 |
父类型 |
类型 |
描述 |
|
全部版本 |
TermFreqs |
TermCount |
TermFreq |
按照term顺序排序,term是隐含的(?implicit),来自.tis文件。TermFreq按文档编号递增的顺序排序。 |
|
SkipData |
TermCount |
SkipData |
|
|
|
TermFreq->DocDelta |
TermCount |
VInt |
如果omitTf设置为false,要同时检测文档编号和频率,特别指出,DocDelta/2时该文档编号与上一个文档编号的差值(如果是第一个文档值为0)。当DocDelta为单数时频率为1,当DocDelta为偶数时频率为读取下一个VInt的值。如果omitTf设置为true,DocDelta为文档编号之间的差值(gap,不用乘以2,multiplited),频率信息则不被存储。 |
|
|
TermFreq->[Freq?] |
TermCount |
VInt |
|
|
|
SkipData->SkipLevelLength |
NumSkipLevels-1 |
VInt |
|
|
|
SkipData->SkipLevel |
TermCount |
SkipDatums |
|
|
|
SkipLevel->SkipDatum |
DocFreq/(SkipInterval^(Level + 1)) |
SkipDatum |
|
|
|
SkipData->SkipDatum |
TermCount |
SkipDatum |
|
|
|
SkipDatum->DocSkip |
1 |
VInt |
|
|
|
SkipDatum->PayloadLength? |
1 |
VInt |
|
|
|
SkipDatum->FreqSkip |
1 |
VInt |
|
|
|
SkipDatum->ProxSkip |
1 |
VInt |
|
|
|
SkipDatum->SkipChildLevelPointer? |
1 |
VLong |
|
结构如下图所示:
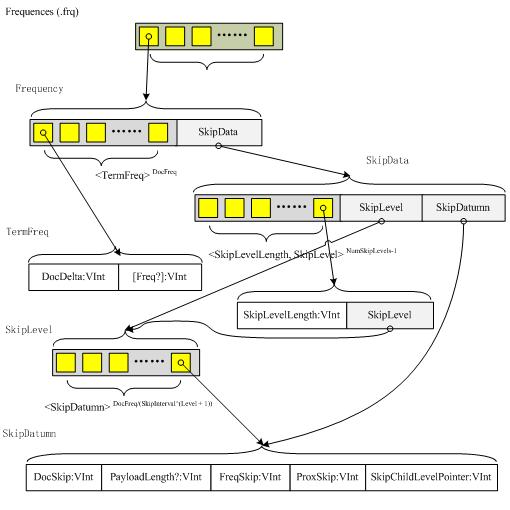
举例来说,当omitTf设置为false时,一个term的TermFreqs在文档7出现1次并且在文档11中出现3次,则为如下的VInt数字序列:
15, 8, 3
如果omitTf设置为true时,则为如下数字序列:
7, 4
DocSkip记录在TermFreqs中每隔SkipInterval个文档之前的文档编号。如果该term的域fields中被禁用payloads时,则DocSkip呈现在序列中(in the sequence)与上一个值之间的差值(difference)。如果payloads启用时,则DocSkip/2表示序列中与上一个值之间的差值。如果payloads启用并且DocSkip为奇数时,PayloadLength将被存储并表示(indicating)在TermPositions中第SkipInterval个文档之前的最后一个payload的长度。FreqSkip和ProxSkip分别(respectively)记录在FreqFile和ProxFile文件中每SkipInterval个记录(entry)的位置。文件的位置信息对序列中前一个SkipDatumn来说与TermFreqs和Positions的起始信息相关。
例如,如果DocFreq=35并且SkipInterval=16,则在TermFreqs中有两个SkipData记录,容纳第15和第31个文档编号。第一个FreqSkip代表第16个SkipDatumn起始的TermFreqs数据开始之后的字节数目,第二个FreqSkip表示第32个SkipDatumn开始之后的字节数目。第一个ProxSkip代表第16个SkipDatumn起始的Positions数据开始之后的字节数目,第二个ProxSkip表示第32个SkipDatumn开始之后的字节数目。
在Lucene 2.2版本中介绍了skip levels的想法(notion),每一个term可以有多个skip levels。一个term的skip levels的数目等于NumSkipLevels = Min(MaxSkipLevels, floor(log(DocFreq/log(SkipInterval))))。对一个skip level来说SkipData记录的数目等于DocFreq/(SkipInterval^(Level + 1))。然而(whereas)最低的(lowest)skip level等于Level = 0。
例如假设SkipInterval = 4, MaxSkipLevels = 2, DocFreq = 35,则skip level 0有8个SkipData记录,在TermFreqs序列中包含第3、7、11、15、19、23、27和31个文档的编号。Skip level 1则有2个SkipData记录,在TermFreqs中包含了第15和第31个文档的编号。
在所有level>0之上的SkipData记录中包含一个SkipChildLevelPointer,指向(referencing)level-1中相应)(corresponding)的SkipData记录。在这个例子中,level 1中的记录15有一个指针指向level 0中的记录15,level 1中的记录31有一个指针指向level 0中的记录31。
3.3.4 Positions位置信息数据(.prx)
Positions位置信息数据文件(.prx文件)容纳了每一个term出现在所有文档中的位置的列表。注意如果在fields中的omitTf设置为true时将不会在此文件中存储任何信息,并且如果索引中所有fields中的omitTf都设置为true,此.prx文件将不会存在。
|
版本 |
包含的项 |
数目 |
类型 |
描述 |
|
全部版本 |
TermPositions |
TermCount |
TermPositions |
按照term顺序排序,term是隐含的(?implicit),来自.tis文件。 |
|
TermPositions->Positions |
DocFreq |
Positions |
按文档编号递增的顺序排序。 |
|
|
Positions->PositionDelta |
Freq |
VInt |
如果term的fields中payloads被禁用,则取值为term出现在该文档中当前位置与前一个位置的差值(第一个位置取值0)。如果payloads被启用,则取值为当前位置与上一个位置之间差值的2倍。如果payloads启用并且PositionDelta为单数,则PayloadLength被存储,表示当前位置的payloads的长度。 |
|
|
Positions->Payload? |
Freq |
Payload |
|
|
|
Payload->PayloadLength? |
1 |
VInt |
|
|
|
Payload->PayloadData |
PayloadLength |
byte |
|
结构如下图所示:

例如,如果一个term的TermPositions为一个文档中出现的第4个term,并且为后来的文档(subsequent document)中出现的第5个和第9个term,则将被存储为下面的VInt数据序列(payloads禁用):
4, 5, 4
PayloadData是与term的当前位置相关联元数据(metadata),如果该位置的PayloadLength被存储,则它表示此payload的长度。如果PayloadLength没存储,则此payload与前一个位置的payload拥有相等的PayloadLength。
3.3.5 Norms调节因子文件(.nrm)
在Lucene 2.1版本之前,每一个索引都有一个norm文件给每一个文档都保存了一个字节。对每一个文档来说,那些.f[0-9]*包含了一个字节容纳一个被编码的分数,值为对hits结果集来说在那个field中被相乘得出的分数(multiplied into the score)。每一个分离的norm文件在适当的时候(when adequate)为复合的(compound)和非复合的segment片断创建,格式如下:
Norms (.f[0-9]*) –> <Byte> SegSize 在Lucene 2.1及以上版本,只有一个norm文件容纳了所有norms数据:
|
版本 |
包含的项 |
数目 |
类型 |
描述 |
|
2.1及之后版本 |
NormsHeader |
1 |
raw |
‘N’,'R’,'M’,Version:4个字节,最后字节表示该文件的格式版本,当前为-1 |
|
Norms |
NumFieldsWithNorms |
Norms |
|
|
|
Norms->Byte |
SegSize |
Byte |
每一个字节编码了一个float指针数值,bits 0-2 容纳 3-bit 尾数(mantissa),bits 3-8容纳 5-bit 指数(exponent),这些被转换成一个IEEE单独的float数值,如图所示 |
|
|
NormsHeader->Version |
1 |
Byte |
|
结构如下图所示:

一个分离的norm文件在一个存在的segment的norm数据被更改的时候被创建,当field N被修改时,一个分离的norm文件.sN被创建,用来维护该field的norm数据。

