

突袭HTML5之WebSocket入门2 - 高效服务器Node.js
Node采用C++语言编写而成;为什么采用C++语言呢?据Node创始人Ryan Dahl回忆,他最初希望采用Ruby来写Node,但是后来发现Ruby虚拟机的性能不能满足他的要求,后来他尝试采用Google的V8引擎,所以选择了C++语言。Node是一个服务器端的JavaScript运行环境(支持的系统包括*nux、Windows),这意味着你可以编写系统级或者服务器端的JavaScript脚本,交给Node来解释执行。
到主站http://nodejs.org/下载系统对应的最新版的装上即可,非常简单。安装程序会自动安装npm,这个就是Node的模块管理工具(就像Ruby的Gem一样),所有扩展的模块或框架都是通过这个安装的。
Node模块
模块是Node可用的类库;Node使用CommonJS模块系统作为核心模块,比如http, sys, process, fs, streams...来完成各种功能。用户可以自己编写模块,在程序中使用;此外,目前有大量稳定的外部模块可用,基本都可以在https://github.com/joyent/node/wiki/modules看到介绍;使用npm install可以安装模块相应的模块到当前目录中,比如经典的socket.io, express,是通过下面的命令行执行安装的:
在Node中,文件和模块是一一对应的。
卓越特性
Node的特性可以概括如下:Google V8,单线程,非阻塞IO,事件驱动。
先说V8,Google Chrome浏览器的JavaScript引擎Google V8是一个开源的独立引擎,可独立运行或内嵌于任何C++工程之中,性能很好,同时还提供了很多系统级的API如文件操作、网络编程等。速度是V8追求的主要设计目标之一,它把JavaScript脚本直接编译成机器码运行,比起传统的“中间代码+解释器”的引擎,优势不言而喻,这就是Node高效的一个重要原因。浏览器端的JavaScript脚本在运行时会受到各种安全性的限制,对客户系统的操作有限。相比之下,Node则是一个全面的后台运行时,为JavaScript提供了其他语言能够实现的许多功能。Node的目的是提供一种简单的途径来编写高性能的网络程序。
Node是单线程执行的,那么如何解决并行的问题呢?这个就是通过非阻塞IO与事件驱动实现的。 这种做法的的根据是IO的运行速度远远慢于CPU的运行速度,所以当请求来了以后,CPU处理一下,直接甩给相应的IO去处理,然后继续等待别的请求。最经典的一句解释就是“除了你的代码,其他全部是并行执行的”。下面这幅图清晰的说明了Node的并行处理机制:
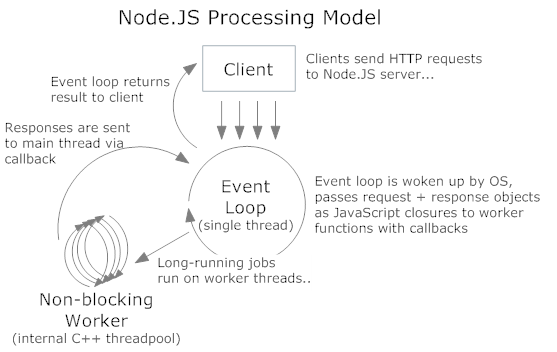
Node核心模块中的方法基本都有异步版本与同步版本(Sync结尾的方法),尽量不要使用同步的版本来阻塞主线程。
编程实践
Node大大简化了Web开发人员的工作量,只需要少少几步,就可以搭建起一个服务器,进行开发和调试。
- 服务端编程
服务器编程就是启动服务器,处理客户端请求。下面就是一个附带简单路由功能的服务器程序:

var http = require("http"), url = require("url"), path = require("path"), fs = require("fs");
//创建Server并处理请求
http.createServer(function (req, res)
{
var pathname=__dirname+url.parse(req.url).pathname;
if (path.extname(pathname)=="")
{
pathname+="/";
}
if (pathname.charAt(pathname.length-1)=="/")
{
pathname+="index.html";
}
path.exists(pathname,function(exists)
{
if(exists)
{
switch(path.extname(pathname))
{
case ".html":
res.writeHead(200, {"Content-Type": "text/html"});
break;
case ".js":
res.writeHead(200, {"Content-Type": "text/javascript"});
break;
case ".png":
res.writeHead(200, {"Content-Type": "image/png"});
break;
default:
res.writeHead(200, {"Content-Type": "application/octet-stream"});
}
fs.readFile(pathname,function (err,data)
{
res.end(data);
});
}
else
{
res.writeHead(404, {"Content-Type": "text/html"});
res.end("<h1>404 Not Found</h1>");
}
});
}).listen(8080, "127.0.0.1");
console.log("Server running at http://127.0.0.1:8080/");
运行这个服务程序很简单,把这个代码保存为server.js(名字随意),然后直接在cmd中执行"node server.js",这样一个服务端程序就就绪了,是不是很简单!
注意:
1. node后面的参数一定要带扩展名,不能省略那个".js",否则会报错。
2. 这是一个简单的服务器程序,所以没有考虑程序的结构;在典型的开发过程中,通常需要把启动代码,服务器代码,路由代码,请求处理代码分别放到不同的模块中并使用MVC来减弱每个功能之间的耦合性,易于扩展。例如下面的代码结构:
|-Solution文件夹
|--index.js:程序的入口,放置启动服务器等初始化方法(Node的惯用法,也可使用run.js等名字)。
|--server.js:程序服务器程序,通常放置启动服务器,调用路由程序(这个有时也放到index.js中)等。
|--route.js:程序路由程序,放置路由方法。
|--config.js:配置路由程序。
|--controllers:放置各种需求处理的业务逻辑。
|--hanlerRequest.js:请求处理程序模块,放置每种请求的处理方法。
|--models:放置各种需要的数据
|--model...业务数据
|--views:放置各种页面模板
|--index.html:页面模板
这里的组织方式只是我采用的一个组织方式,实际开发中还是以个人的实际需要来设计自己的组织方式。
3. 模块的成员使用exports或者this导出。例如服务器程序server.js:
exports.runServer = function(){
var server = http.createServer(function(req, res){
//...
}).listen(8080);
console.log('Server running at http://127.0.0.1:'+ port +'/');
};
this.server = '127.0.0.1';
server.js模块导出了runServer方法,server属性。
4. 导入模块用require方法,导入以后可以直接使用导入的成员。例如index.js模块的代码为:
server.runServer();
导入的规则如下:
(1)核心模块通过标示符直接导入,而且总是被优先加载。例如,require('http')将总是返回内建的HTTP模块,即便又一个同名文件存在。
(2)文件模块通过文件名导入(可以省略扩展名),如果没有找到确切的文件名,Node将尝试以追加扩展名.js后的文件名读取文件,如果还是没有找到则尝试追加扩展名.node。.js文件被解释为JavaScript格式的纯文本文件,.node文件被解释为编译后的addon(插件)模块,并使用dlopen来加载。
(3)以'/'为前缀的模块是一个指向文件的绝对路径,例如require('/home/publish/foo.js')将加载文件/home/publish/foo.js。
(4)以'./'为前缀的模块是指向文件的相对路径,相对于调用require()的文件。也就是说为了使require('./circle') 能找到正确的文件,circle.js必须位于与foo.js 相同的路径之下。
(5)如果标明一个文件时没有 '/' 或 './'前缀,该模块或是"核心模块",或者是位于安装目录的node_modules目录中。如果在其他的目录下运行npm安装模块,则这里指的就是其他目录的node_modules目录。
(6)在Node中,require.paths是一个保存模块搜索路径的字符串数组。当模块不以'/','./'或'../'为前缀时,将从此数组中的路径里进行搜索。可以在运行时改变require.paths数组的内容,以改变路径搜索行为。但在实践中发现,修改require.paths列表往往是造成混乱和麻烦的源头。
- 客户端编程
Node运行服务端程序,不影响客户端,客户端编程还是与以前一样,就是考验兄弟JavaScript/JQuery的功力了。
实用参考:
Node核心模块介绍:http://cnodejs.org/cman/



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?