

浅析正则表达式——柳暗花明又一村篇
本文章主要针对上篇文章进行补充,接上一篇文章http://www.cnblogs.com/dwlsxj/p/3532458.html,首先为什么开篇叫柳暗花明又一村,大家都知道这个词的解释:一个人在想某个问题或做某件事的时候,遇到了一定阻碍,但是后来某个时刻突然来了灵感,使问题得到解决!就是那种“顿悟”的意思!由于前面一篇文章中有人说看到零宽度和占有符的时候就看不下去了,看着就有点模糊,那么下面我就针对零宽度进行讲解下。零宽度其实就是匹配一个位置,前面我们讲了字符串的组成,比如”123”这个字符串有三个字符,四个位置。那么零宽度仅仅是匹配这四个位置,而不占有字符,它不会将内容保存到最后的结果,零宽度的子表达式之间是不互斥的,所以一个位置可以由多个零宽度进行匹配。通篇以例子的形式进行分析讲解!
下面我们借助例子来讲述下为什么说零宽度是仅仅匹配一个位置?
首先我们看一下这个例子:
我们要写一个正则表达式,我们要匹配的内容是匹配当前位置后面是SmallDing的,也就是开始位置为SmallDing的正则表达式。我们很容易就联想到我所说的第二个例子,看看你们中枪没有?
例子一:正则表达式为:(?=SmallDing)SmallDing\d+
源文本:SmallDing520
首先先看一下结果:

正则表达式所匹配内容:这个正则表达式的意思是匹配当前匹配的位置后面跟的是SmallDing,后面再进行匹配SmallDing加一串数字。有人会问什么是当前匹配的位置,接下来我们就进行深一层的分析。分析图详见下图:
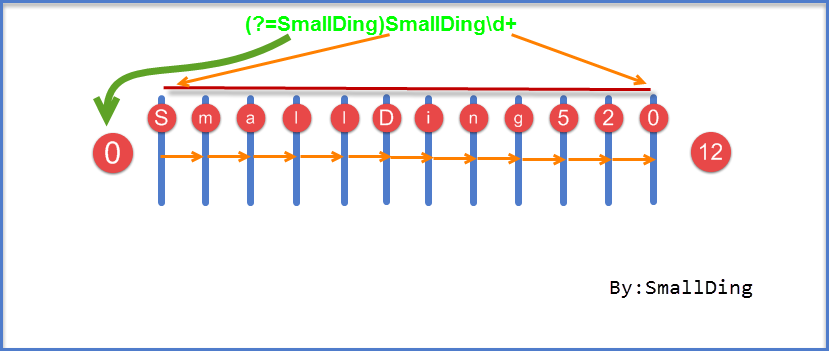
我们来分析一下匹配的过程,首先得到控制权的是(?=SmallDing),从位置0处进行匹配,由于该表达式是零宽度,仅仅是匹配一个位置,并不将内容保存到最后结果,环视位置0处后面跟的是不是SmallDing(位置0处就相当于是当前匹配的位置),可以理解为从位置0处向右环视是不是SmallDing,如果是匹配成功,如果不是就匹配失败,这里我们匹配成功,接下来我们将控制权传动给正则表达式中的“S”,前面我们已经说过了零宽度仅仅是匹配一个位置,它的从位置0开始也是从位置0结束,那么正则表达式中的S就会还是从位置0处进行匹配,匹配源文本中的S,匹配成功,控制权向右传动,以此类推,直到匹配结束。
例子二:
正则表达式:(?=SmallDing)\d+
源文本:SmallDing520
匹配结果:空
详情请见下图所示:
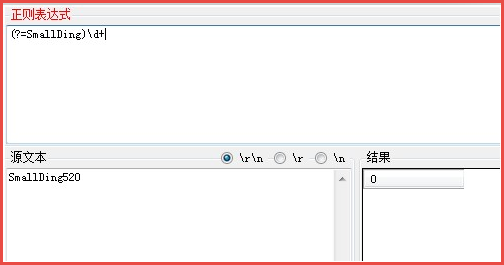
我们现在就来进行对其进行分析,整个正则表达式的含义是匹配当前位置后面跟的是SmallDing,但是不匹配SmallDing,后面还有数字重复1次以上。
接下来我们就进行分析这正则表达式匹配的情况,首先源文本的结构图见下图所示:
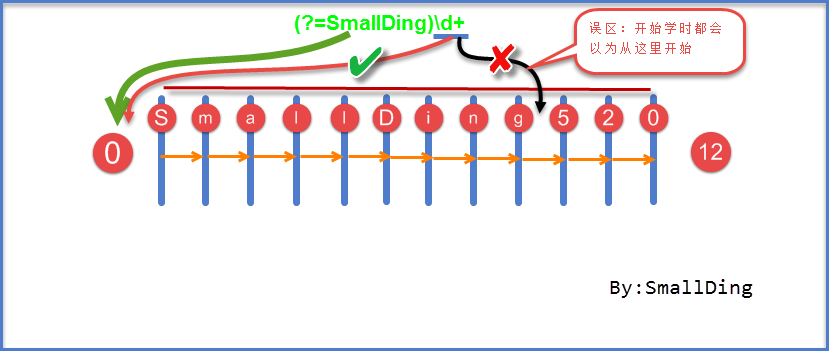
首先这里就有一个误区,我们大家初学的时候都以为零宽度断言是虽然不匹配文本,但是感觉位置是进行改变的,也就是匹配零宽度子表达式匹配的位置会移动到位置9处,其实不是这样接下来我们就来分析下。
正则表达式从左往右依次匹配,首先得到控制权的是正则表达式中的(?=SmallDing),它会从位置0处进行匹配,仅仅匹配一个位置,不会将内容保存到最后的结果中,从位置0处向右环视该零宽度子表达式SmallDing与源文本的SmallDing进行匹配,符合要求,匹配成功。控制权传动给正则表达式的”\d+”,由于零宽度我们讲过只匹配一个位置,它从位置0开始也是从位置0结束,所以”\d+”从位置0处进行匹配,匹配源文本的S,匹配失败,由于正则表达式是向前推动的,所有又从位置1处开始匹配,控制权交给(?=SmallDing),向右进行环视,不符合要求,匹配失败,正则表达式又向前推动,以此类推直到整个推动结束匹配失败!
总结:看似两个正则表达式没有什么联系,而且两个正则的含义也不一样,却能表现出我们刚学正则表达式时的状况,我们刚开始学正则表达式的时候一直都以为第二个例子是我们想要得到的效果,对呀匹配当前位置后面跟的是SmallDing,不匹配该内容,那么匹配完了后面就应该匹配”\d+”,也就是匹配520,但是通过这篇文章的理解,这种想法是错的,我们以为是零宽度是占有字符的,它匹配的位置会随之改变,而不是原地不动。事实上,零宽度断言是只匹配了位置,而没有将内容保存到最后的结果当中,因此它开始匹配的位置和结束的位置是不变的。
看了上面的例子,也许我们会有些联想,我上篇文章中所说的,(?=exp)另一层理解含义是匹配exp表达式前面的内容。没错,是这样的,(?=exp)在本文所说的是换一个角度讲的,换做是匹配位置讲的,举个例子进行说明:看下面的例子
例子三:
正则表达式:\b\w+(?=ing\b)
源文本:doing
匹配结果:do
详情请见下图:
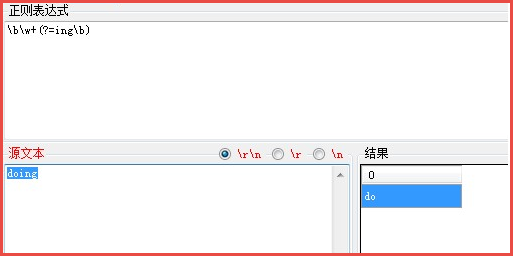
解析:正则表达式表示匹配一个单词开始位置,”\b”它只匹配一个位置,所以它是零宽度的,匹配一个单词,匹配ing前面的内容。
下面对匹配过程进行分析,首先先看下面这张图:
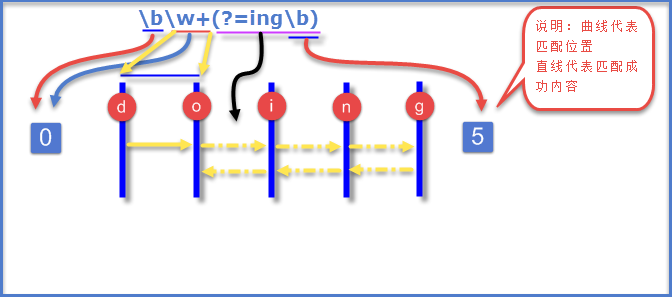
匹配过程分析:首先得到控制权的是”\b”,它从位置0处进行匹配,匹配一个位置匹配成功,将控制权转交给”\w+”,”+”是优先词量,在可匹配与不匹配的情况下优先尝试匹配,它从位置0处开始匹配,匹配”D”,符合要求,匹配成功,将其保持到最后结果(也叫吞入一个字符),接下来匹配”o”,符合要求,匹配成功,吞入一个字符,重复上面,匹配到”g”,符合要求,匹配成功,再向后匹配时发现已经到了结尾了,”\w+”这时匹配完成,将控制权 传动给(?=ing\b),由它来匹配最后位置5处,发现已经到了正则的结束位置,看有没有可供回溯的状态,它将控制权转交给”\w+”,”\w+”让出三个字符,又将控制权转交给最后的(?=ing\b),从位置2处开始匹配后面跟的是ing还有一个结束位置,匹配成功,整个表达式匹配完成。
(?<=exp):
例子一:
正则表达式:(?<=SmallDing)\d+
源文本:SmallDing520
匹配结果:520
详细情况如下图所示:
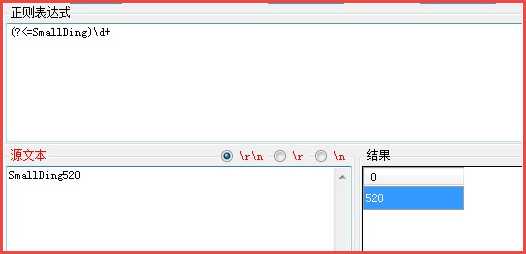
匹配过程:正则表达式从最右侧开始进行匹配,首先得到控制权的是(?<=SmallDing),由它从位置0处进行匹配,从位置0处进行环视左边是不是SmallDing,环视左面不是SmallDing,是开始位置,匹配失败,由于正则是向前推动的,所以控制权在手的(?<=SmallDing)又开始在位置1处进行匹配,环视左侧是S,和零宽度子表达式不相符,匹配失败,再向前推动,以此类推,一直到位置9处,环视左侧是SmallDing与零宽度子表达式相符,匹配成功,由于是零宽度,只匹配位置,并不将内容保存到最后结果中。将控制权传动给正则表达式的”\d+”,由于“+”是有限词量,在可匹配的情况下优先尝试匹配,从位置9处尝试匹配源文本的5,符合要求,匹配成功,将内容保存到最后结果中,依次匹配直到匹配结束。
至于还有两个负零宽度断言(?!exp)和(?<!exp)基本原理是一样的,这里就不做详细讲解了,只是跟我们分析的是环视内容相符的,负零宽度断言是环视内容不相符的。这里补充说明零宽度不仅仅只有这四个,还有^$表示字符串的开始与结束也是匹配一个位置,还有\b匹配单词的开始与结束的位置,都不占有字符。通过这篇文章我们可以深入理解零宽度和占有符的区别。
通过这篇文章分析可以使我们理解零宽度和占有符的区别,也希望大家能够从中找到缺点,小丁将其改正,如果有分析不正确的望指正。
这里要感谢@宵的天使在上一篇文章提供详细的正则表达式,让我有了更好的理解。
参考文章:http://blog.csdn.net/lxcnn/
方便大家阅读,已将文档传到网盘网盘地址如下:
百度网盘链接:http://pan.baidu.com/s/1kTKB3Zx 提取密码:l6q4
接下来就是对着正则表达式应用的练习:

