AN EMPIRICAL STUDY OF EXAMPLE FORGETTING DURING DEEP NEURAL NETWORK LEARNING 论文笔记
- 摘要
受到灾难性遗忘现象的启发,我们研究了神经网络在单一分类任务训练时的学习动态。 我们的目标是了解当数据没有明显的分布式转变时是否会出现相关现象。 我们定义了一个“遗忘事件”
当个别训练示例在学习过程中从正确分类转换为错误时。 在几个基准数据集中,我们发现:(i)某些例子被高频率遗忘,有些则完全没有; (ii)数据集的(不)可遗忘的例子概括了神经架构;
(iii)基于遗忘动力学,可以从训练数据集中省略大部分示例,同时仍保持最先进的泛化性能。
- 简介
我们的实验结果表明:a)存在大量令人难忘的例子,即一旦学会就永远不会忘记的例子,这些例子在种子之间是稳定的,并且从一个神经架构到另一个神经架构强烈相关; b)带有嘈杂标签的例子是最被遗忘的例子,还有具有“不常见”特征的图像,视觉上很难分类; c)在数据集上训练神经网络,其中已经移除了大部分最少被遗忘的示例仍然导致测试集上的极具竞争性的性能。
- 程序描述和实验设置
根据先前的定义,监视遗忘事件需要在每次模型更新时计算数据集中所有示例的预测,这将非常昂贵。 在实践中,对于每个示例,我们通过仅在示例包含在当前小批量中时计算遗忘统计来对完整的遗忘事件序列进行子样本化; 也就是说,我们在随后的小批量中计算遗忘相同示例的演示文稿。 这给出了示例在训练期间经历的遗忘事件的数量的下限。
我们在给定数据集上训练分类器,并记录每个示例在当前小批量中采样时的遗忘事件。 为了进一步分析,我们基于它们经历的遗忘事件的数量对数据集的示例进行排序。 从有序数据中采样时,关系会随机中断。 从未学过的样本被认为是无数次被遗忘用于分类目的。 注意,这种遗忘示例的估计在计算上是昂贵的;
我们对三个复杂度日益增加的数据集进行了实验评估:MNIST(LeCun等,1999),置换MNIST - 一种版本的MNIST,其具有应用于所有示例像素的相同固定置换,以及CIFAR10(Krizhevsky,2009)。 我们使用各种模型架构和训练方案,产生与各个数据集上当前最新技术水平相当的测试误差。 特别是,基于MNIST的实验使用由两个卷积层组成的网络,然后是完全连接的层,使用具有动量和丢失的SGD进行训练。 该网络实现0.8%的测试错误。 对于CIFAR-10,我们使用带有切口的ResNet(DeVries&Taylor,2017),使用SGD和动力训练
特定的学习率表。 该网络实现了3.99%的竞争性测试错误。

- 特征样本遗忘
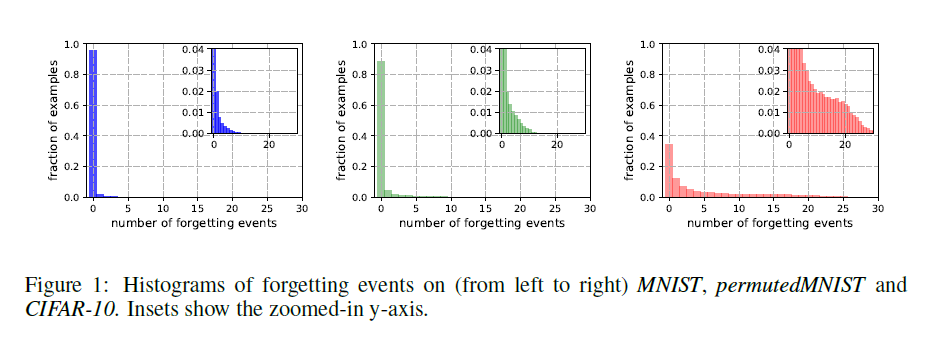
遗忘事件的数量。我们估计了5个随机种子中三个不同数据集(MNIST,permuted MNIST和CIFAR-10)的所有训练样例的遗忘事件数。 从一个种子计算的遗忘事件的直方图如图1所示。有55012个,45181个和15628个令人难忘的5个种子常见的例子,它们分别代表91.7%,75.3%和31.3%的相应训练集。 请注意,具有较少复杂性和多样性的数据集(例如MNIST)似乎包含更多令人难忘的示例。 permuted MNIST表现出MNIST(最简单)和CIFAR-10(最难)之间的复杂性。 这一发现似乎暗示了遗忘统计数据与学习问题的内在维度之间的相关性,正如李等人最近提出的那样(2018)。
种子间的稳定性。为了测试我们的度量相对于随机梯度下降产生的方差的稳定性,我们计算了10个不同随机种子的每个例子的遗忘事件的数量并测量它们的相关性。 从一粒种子到另一粒种子,平均Pearson相关系数为89.2%。 当将10个不同的种子随机分成两组5时,这两组中遗忘事件的累积数量显示出97.6%的高相关性。 我们还对100个种子进行了原始实验,以设计每个例子中遗忘事件平均数(超过5个种子)的95%置信区间。 最少被遗忘的例子的置信区间很紧,确认了具有少量遗忘事件的例子可以自信地提升准确率。
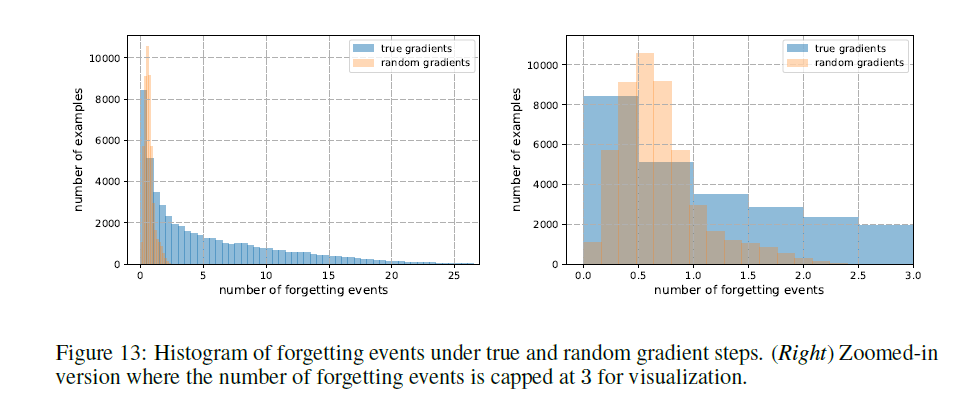
偶然遗忘。为了量化偶然发生遗忘的可能性,我们另外分析了在随机更新步骤而不是真正的SGD步骤下获得的遗忘事件的分布。 为了保持类似于在SGD期间遇到的随机更新的统计数据,通过在主网络上混合由标准SGD产生的梯度来获得随机更新。 我们在补充图13中报告机会遗忘事件的直方图:示例被偶然遗忘了一小部分时间,最多两次,大部分时间不到一次。 观察到的种子间的稳定性,机会遗忘事件的数量少以及紧密的置信区间表明,度量产生的排序不太可能是另一个不相关的随机原因的副产品。
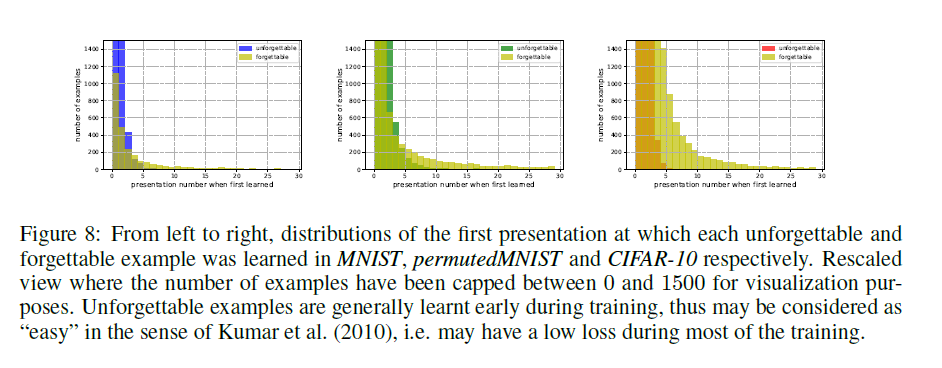
第一次学习事件。我们调查是否需要呈现非遗忘和遗忘的例子以便第一次学习(即第一次学习事件发生)。 在补充图8中可以看到第一次学习事件在所有数据集中出现的表示编号的分布。我们观察到,虽然难忘和遗忘集都包含许多在前3-4个演示中学习的例子,但是遗忘的例子包含大量先后在训练中学习的示例。 第一次学习事件演示与所有训练样例中遗忘事件数量之间的Spearman等级相关性为0.56,表明中等关系。
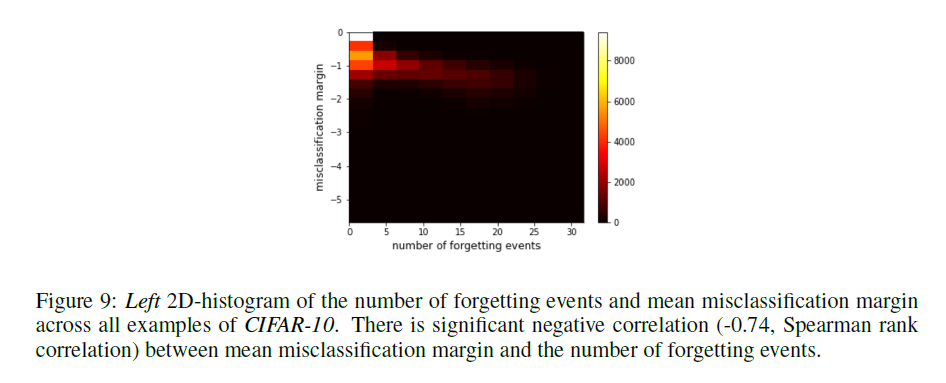
错误分类margin。遗忘事件的定义是二元的,因此与更复杂的示例相关性估计量相比较粗略(Zhao&Zhang,2015; Chang等,2017)。 为了确定其有效性,我们计算遗忘事件的误分类边界。 一个例子的错误分类界限被定义为所有遗忘事件的平均分类界限,按定义为负数量。 示例的遗忘事件数与其平均误分类余量之间的Spearman等级相关性为-0.74(在5个种子上计算,参见补充图9中的相应2D直方图)。 这些结果表明,经常被遗忘的例子具有较大的错误分类边际。
视觉检查。我们可视化图2中的一些令人难忘的示例以及CIFAR-10数据集中最遗忘的一些示例。 难忘的样本很容易识别并包含最明显的类属性或居中对象,例如晴空中的平面。 另一方面,最被遗忘的例子表现出更加模糊的特征(如在中心图像中,棕色背景上的卡车),其可能与来自同一类别的其他示例共有的学习信号不一致。

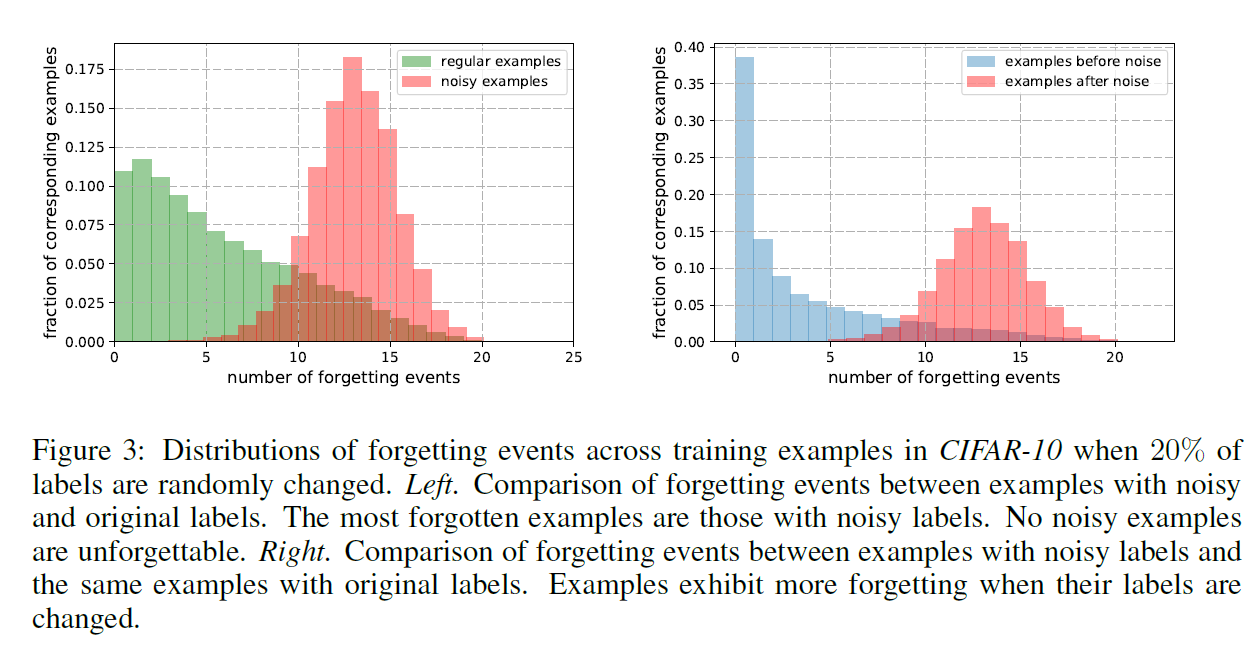
检测噪声样本。我们进一步研究了最容易忘记的例子似乎表现出非典型特征的观察结果。 我们希望,如果高度遗忘的例子具有非典型的阶级特征,那么噪声样本将会更多地遗忘5个事件。 我们随机更改了20%CIFAR-10的标签,并通过训练记录了噪声和常规示例的遗忘事件数。 图3显示了在噪声和常规示例中遗忘事件的分布。我们观察到最被遗忘的例子是那些带有噪声标签的例子,没有噪声的例子更难忘。 我们还将噪声示例的遗忘事件与具有原始标签的同一组示例的遗忘事件进行比较,并在噪声的情况下观察更高程度的遗忘。 这些合成实验的结果支持这样的假设:高度遗忘的例子表现出非典型的类特征。