


DeepLearning: Contractive Autoencoder
一、雅克比矩阵
雅克比矩阵是一阶偏导,假设(x1,x2,....,xn)到(y1,y2,...,ym)的映射,相当于m个n元函数,它的Jacobian Matrix如下
该矩阵表示x的微小波动对y的影响。
雅克比矩阵与Hessian矩阵不同,hessian矩阵表示二阶偏导。
可以用雅克比矩阵表示函数的一阶泰勒展开
二、Contractive Autoencoder( CAE )
在特征学习中使用雅克比矩阵,CAE的损失函数:
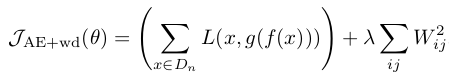
第一部分原始autoencoder的损失函数,第二部分是F范式下的雅克比矩阵的形式
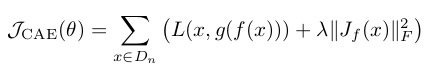

第一部分最小化重构误差,第二部分是让模型具有局部不变性,我们的目标是使偏导尽可能的小,假设极端情况下偏导为0,那么即表示模型对局部的抖动具有鲁棒性。
hogo的解释很有意思,第一部分最小化重构误差,即要在编码的时候将最具代表性的特征信息保留下来,而第二部分只与偏导不为0时的样本有关,即丢掉了所有有用的信息,而保留下抖动信息,我们要使模型对抖动具有不变性。
那么整个损失函数的作用即只保持具有代表性的好特征信息

从下图可以看出,CAE在编码时,对横坐标的变化要具有不变性,即三个手写体2要具有相同的编码,而对纵轴不需要具有不变性。
因为CAE只考虑样本中出现的情况,不考虑未出现的情况。而denoising autoencoder( DAE)是对输入加入噪声,然后重构未加噪声的样本,
也就是说它要对样本中未出现的测试样本具有鲁棒性。

三、DAE and CAE
- CAE主要挖掘训练样本内在的特征,它使用的是样本本身的梯度信息,而DAE使用的是加了噪声的样本的梯度信息,不能够完全体现原数据分布,因此CAE的泛化能力比DAE好
- DAE实现比较简单,只需要加几句代码就行,不需要计算隐含层的Jacobian矩阵
- CAE需要使用 使用二阶的优化方法(conjugate gradient, LBFGS等)
特征表示的两个衡量标准
- 重构误差小,很好的重构出原数据 (autoencoder , sparse autoencoder )
- 对抖动具有不变性 ( denoising autoencoder , contractive autoencoder )
参考文献 :
hogo youtube上的视频:https://www.youtube.com/watch?v=79sYlJ8Cvlc


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧