【SQLServer】记一次数据迁移-标识重复的简单处理
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql
今天在数据迁移的时候因为手贱遇到一个坑爹问题,发来大家乐乐,也传授新手点经验
迁移惯用就是临时表或者新库,经常用的语法有很多,这次主要说的是这个:select * into 数据库名..表名 from xxx
先不扯了,先看错误:

赶紧看看是不是数据重复~事实证明,木有重复数据。。。
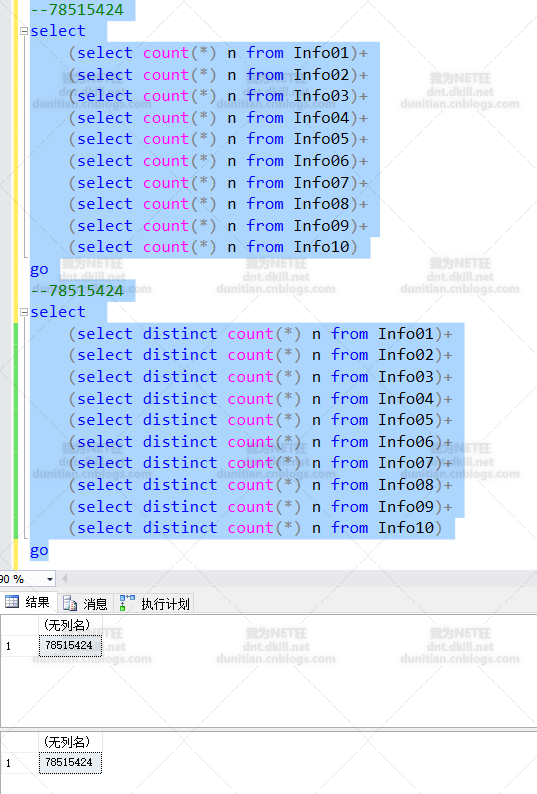
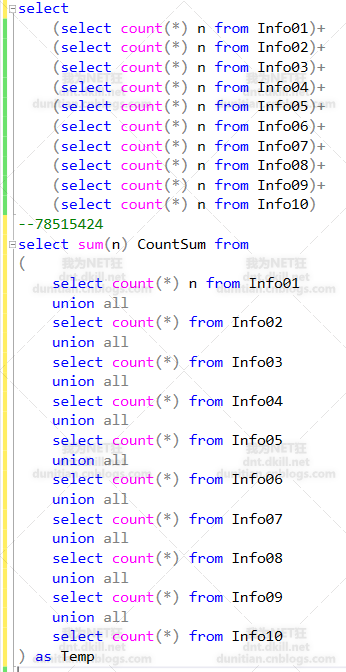
有人会问,你怎么这样求count?。。。额,我会的是最基本的方法,常见的两种其实性能一样的,对比图:(有更好写法可以提点一下小弟^_^)
得了,查下改ID下的数据:到底是不是重复~~~不是。。。
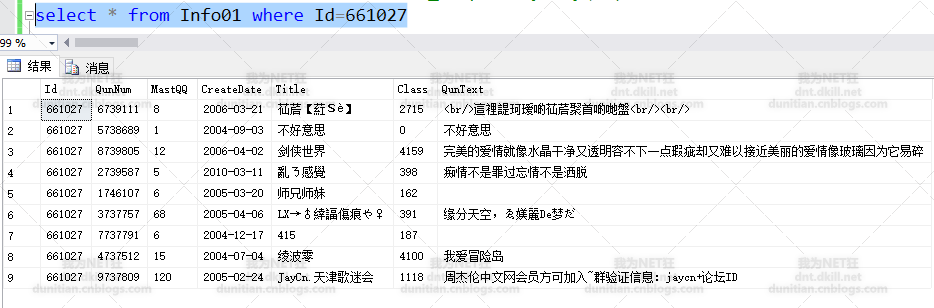
行吧,那咱们就看看同一个ID重复次数

仔细想了下,整个迁移过程,貌似木有什么错误,难道是这个手贱的原因??(命令没执行完,点了好几次加速,也不知道是不是这个原因导致的,好吧就当是他了===》( ̄— ̄))
解决方法:两种,一种就是重新来一次数据迁移整理
第二种就是Id先删了,再建(因为数据没问题,要是数据出问题了,那不管怎么说都得重来一遍)
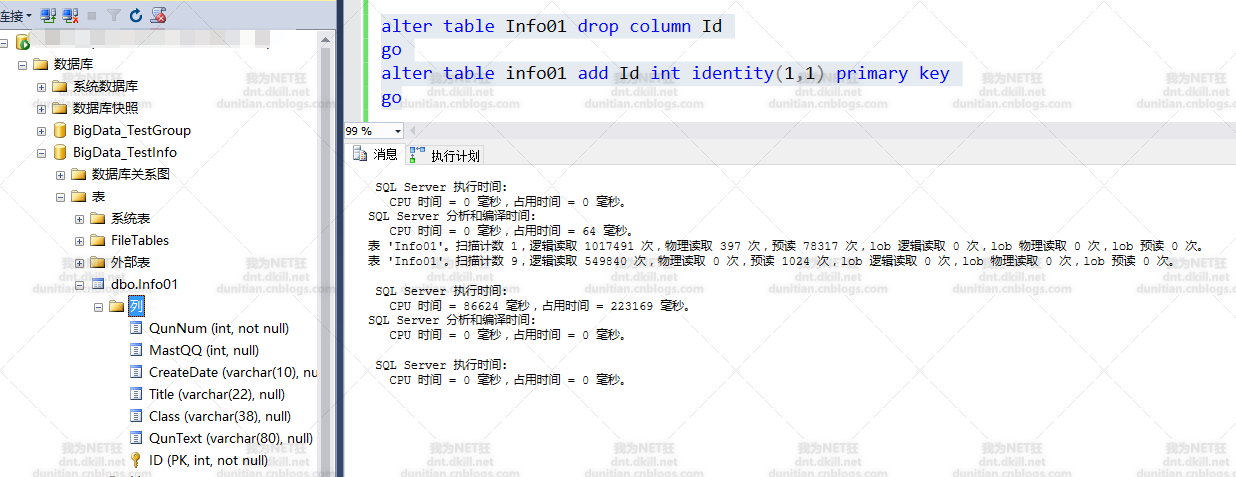
脚本:
alter table Info01 drop column Id
go
alter table info01 add Id int identity(1,1) primary key
go
现在终于知道,为啥很多数据库的主键都是在最后一列了
最后说建议的话,对于这种多表的最好还是用程序来控制和处理数据(你得保证标识唯一),如果不管标识就随便搞了~

