
mongodb相关
2011-06-22 14:47 熬夜的虫子 阅读(685) 评论(0) 收藏 举报一. 简介。
Mongo是一个高性能,开源,无模式的文档型数据库。其名字来自humongous这个单词的中间部分,从名字可见其野心所在就是海量数据的处理。
和mysql一样,一个mongod服务可以建立多个数据库。每个数据库可以有多张表,这里的表成为collection,每个collection可以存放多个文档(document),每个文档都以bson(binary json)的形式存放于硬盘中。跟关系型数据库不一样的地方时,他是以单文档为单位存储的,你可以任意的给一个或一批文档新增或删除字段,而不对其他文档造成影响,这就是所谓的schema-free,也是文档型书苦苦最主要的优点。跟一般的key-value数据库不一样的是,它的value中存储了结构信息,所以你也可以像关系型数据库那样对某些域进行读写、统计等操作。可以说是兼备了key-value数据库的方便高效与关系型数据库的强大功能。
和关系型数据库类似,mongodb可以对某个字段建立索引,可以建立组合索引、唯一索引,当然建立索引就以为着增加空间开销。所以个人建议就是将一个文档作为一个对象来考虑,在线上应用中通常只对对象id建立一个索引就可以了、根据id取出对象数据放在memcache中。默认情况下每个collection队会有一个唯一索引:_id,如果插入数据时没有指定_id,服务会自动生成一个_id,为了充分利用已有索引,减少空间开销,最好是自己指定一个unique的key为_id,通常用对象的id比较合适。
Mongodb允许在建表之初就指定一定的空间大小,接下来的插入操作会不断的按照顺序append数据再这个预分配好的空间中,如果超出这个大小,则回到文件头覆盖原来的数据继续插入。这种结构保证了插入和查询的高效性,它不允许删除单个记录,更新的也有限制:不能超过原有记录的大小。
Monogodb的复制架构和mysql很类似,除了包括master-slave构型和master-master构型之外,还有一个replica pairs构型,这种构型在平常可以像master-slave那样工作,一旦master出现问题,应用会自动连接slave。
千万级的数据mongodb的性能插入效率是mysql的20倍,查询效率也是好几倍。缺点是磁盘空间占用率。
GridFS是mongodb一个很有趣的类似文件系统的东西,它可以用一大块文件空间来存放大量的小文件,不过性能以及其他方面还没有作深入的尝试。
Monogodb不支持事务操作。支持分片不过还未研究。
总结:面向集合的存储、动态查询、完整的索引支持、查询监视、复制及自动故障转移、搞笑的传统存储方式、自动分片以及支持云级别的伸缩性。
二. 场景。
适合于
1. 网站数据,mongo非常适合实时的插入.
2. 缓存,由于性能很高,Monogo也适合作为信息基础设施持久化的缓存层。
3. 大尺寸、低价值的数据。这类数据用传统的关系型数据库代价比较大。
4. 高伸缩的场景,Monogo非常适合由数十台或数百台服务器组成的数据库。
5. 用于对象及json数据的存储。
不适于
高度事务性的系统。
三. 性能分析
1. 先从单线程的角度来测试
模式:单master。非嵌入式。目标地址192.168.140.2,端口27017
空间初始大小:

插入速度:
初始状态
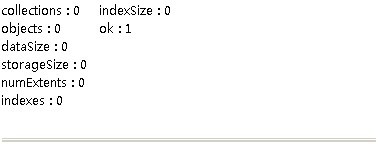
插入动作执行10秒后:

平均每秒插入1w6条数据,每条数据的大小在4k以内。

插入后占用空间:

读取速度:

大概在3500-4000间浮动
50w数据的场合
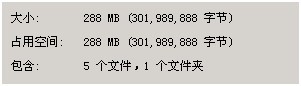
模式:主从master-slave。非嵌入式。目标地址192.168.140.2,端口主27017,从27018
空间初始大小:
主:
从:
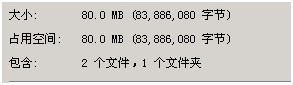
插入速度:
初始状态
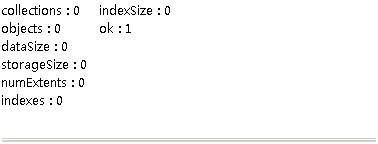
插入动作执行10秒后:(只插入主库)
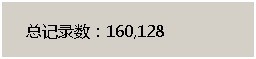
影响不大
30w数据占用的空间 160*2
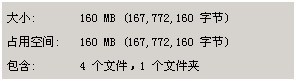
读取速度:
![]()
Ms模式对性能上的影响不大。
下面再看看mm模式,双向同步
模式:主从master-master。非嵌入式。目标地址192.168.140.2,端口主27017,主27018
初始空间:
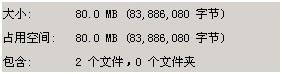
插入速度:
初始状态
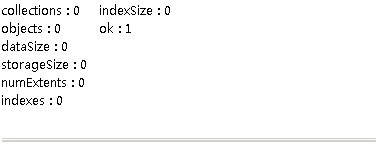
插入动作执行10秒后:

性能大概降低了一半
32w数据占用的空间 160*2

读取速度:

大体不变。
下面拿ms模式来试下多线程的情况
开了3个线程10秒插入数据量
![]()
开了2个进程10秒插入数据量

读取数据不变。
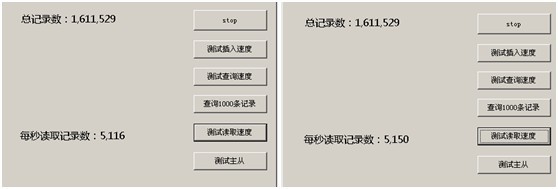
在服务器端直接安装程序读写本地库

读取速度相当可观相当赞。
10秒写入速度不变
![]()
测试中发现的不稳定问题点:
开启2个进程测试读取速度时程序堵塞过一次。
删除操作时,ms模式同步不及时
主:
从
 |
原创作品允许转载,转载时请务必以超链接形式标明文章原始出处以及作者信息。 作者:熬夜的虫子 点击查看:博文索引 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号