

JDK实现的线程池之一:ThreadPoolExecutor、三种阻塞队列、四种拒绝策略、五种线程池、七个参数、线程池状态
一、concurrent包中的五种线程池的简单介绍
- 线程池按照线程数量可以分为:一是固定线程数量的线程池;二是可变数量的线程池。
- 线程池按照执行时间可以分为:一是立即执行线程池;二是延时线程池。
ThreadPoolExecutor是ExecutorService的一个实现类,它使用可能的几个池线程之一执行每个提交的任务。每个ThreadPoolExecutor 还维护着一些基本的统计数据,如完成的任务数。为了便于跨大量上下文使用,此类提供了很多可调整的参数和扩展钩子 (hook)。
JDK提供了一个Executors 工厂方法,用于创建五种线程池:
- Executors.newCachedThreadPool()(无界线程池,可以进行自动线程回收)--可变数量的线程池 ------SynchronousQueue
- Executors.newFixedThreadPool(int)(固定大小线程池) --固定数量的线程池
- 和 Executors.newSingleThreadExecutor()(单个后台线程), --固定数量的线程池
- Executors.newScheduledThreadPool(int corePoolSize) --延迟执行线程池
- 和Executors.newSingleScheduledExecutor() --延迟执行线程池[一个重要的方法就是:schedule(Runnable command, long delay, TimeUnit unit)该方法返回了一个 ScheduledFuture。]
1.1、newCachedThreadPool
构造方法:
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
- maximumPoolSize=Integer.MAX_VALUE,无限线程数量
- 队列采用的是SynchronousQueue--(同步移交)直接提交
1.2、newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
- maximumPoolSize=nThreads,创建重用固定数量线程的线程池
- 队列采用的是LinkedBlockingQueue(最大值是Integer.MAX_VALUE),相当于无界
1.3、newSingleThreadExecutor
构造方法:
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
- maximumPoolSize=1,创建重用1线程的线程池
- 队列采用的是LinkedBlockingQueue(最大值是Integer.MAX_VALUE),相当于无界
实际上就是对ExecutorService类进行了一个包装,相当于设计模式中的装饰者模式,防止暴露出一些不应该暴露的方法。
说到这里应该很明了了,实际上FinalizableDelegatedExecutorService这个类就是对ExecutorService进行了一个包装,防止暴露出不该被暴露的方法,然后加上了finalize方法保证线程池的关闭。
1.4、newScheduledThreadPool
构造方法:
public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); }
- maximumPoolSize=Integer.MAX_VALUE,无限线程数量
- 队列采用的是DelayedWorkQueue
1.5、newWorkStealingPool(stealing 翻译为抢断、窃取的意思)
构造方法:
public static ExecutorService newWorkStealingPool() { return new ForkJoinPool (Runtime.getRuntime().availableProcessors(), ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, true); }
底层调用的是ForkJoinPool线程池,看看ForkJoinPool源码:

public ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler, boolean asyncMode) { this(checkParallelism(parallelism), checkFactory(factory), handler, asyncMode ? FIFO_QUEUE : LIFO_QUEUE, "ForkJoinPool-" + nextPoolId() + "-worker-"); checkPermission(); }
使用一个WorkQueue无限队列来保存需要执行的任务,可以传入线程的数量,不传入,则默认使用当前计算机中可用的cpu数量,使用分治法来解决问题,使用fork()和join()来进行调用。
用意就是它是一个并行的线程池,参数中传入的是一个线程并发的数量,这里和之前就有很明显的区别,前面4种线程池都有核心线程数、最大线程数等等,而这就使用了一个并发线程数解决问题。从介绍中,还说明这个线程池不会保证任务的顺序执行,也就是 WorkStealing 的意思,抢占式的工作。
阿里规范中【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
二、ThreadPoolExecutor类七个参数
在ThreadPoolExecutor类中提供了四个构造方法:
public class ThreadPoolExecutor extends AbstractExecutorService { ..... public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue); public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory); public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler); public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler); ... }
如果想自己扩展实现的话,在手动配置和调整此类时,下面几个参数可以参考。
1、corePoolSize
核心线程数,核心线程会一直存活,即使没有任务需要处理。当线程数小于核心线程数时,即使现有的线程空闲,线程池也会优先创建新线程来处理任务,而不是直接交给现有的线程处理。
核心线程在allowCoreThreadTimeout被设置为true时会超时退出,默认情况下不会退出。
2、maxPoolSize
当线程数大于或等于核心线程,且任务队列已满时,线程池会创建新的线程,直到线程数量达到maxPoolSize。如果线程数已等于maxPoolSize,且任务队列已满,则已超出线程池的处理能力,线程池会拒绝处理任务而抛出异常。
ThreadPoolExecutor调节线程的原则是:先调整到最小线程,最小线程用完后,他会将优先将任务放入缓存队列(offer(task)),等缓冲队列用完了,才会向最大线程数调节。这似乎与我们所理解的线程池模型有点不同。我们一般采用增加到最大线程后,才会放入缓冲队列中,以达到最大性能。ThreadPoolExecutor代码段:
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } else if (!addWorker(command, false)) reject(command); }
线程池执行任务的规则:
- 当线程数小于核心线程数时,创建线程。
- 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
- 当线程数大于等于核心线程数,且任务队列已满: 3.1.若线程数小于最大线程数,创建线程
- 3.2.若线程数等于最大线程数,抛出异常,拒绝任务
3、keepAliveTime
当线程空闲时间达到keepAliveTime,该线程会退出,直到线程数量等于corePoolSize。如果allowCoreThreadTimeout设置为true,则所有线程均会退出直到线程数量为0。
4、allowCoreThreadTimeout
是否允许核心线程空闲退出,默认值为false。
5、unit
有7种取值,在TimeUnit类中有7种静态属性:
TimeUnit.DAYS; //天 TimeUnit.HOURS; //小时 TimeUnit.MINUTES; //分钟 TimeUnit.SECONDS; //秒 TimeUnit.MILLISECONDS; //毫秒 TimeUnit.MICROSECONDS; //微妙 TimeUnit.NANOSECONDS; //纳秒
6、workQueue
一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择:
ArrayBlockingQueue; LinkedBlockingQueue; SynchronousQueue;
所有 BlockingQueue 都可用于传输和保持提交的任务。可以使用此队列与池大小进行交互:
- 如果运行的线程少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队。(什么意思?如果当前运行的线程小于corePoolSize,则任务根本不会存放,添加到queue中,而是直接抄家伙(new thread)开始运行)
- 如果运行的线程等于或多于 corePoolSize,则 Executor 始终首选将请求加入队列,而不添加新的线程。
- 如果无法将请求加入队列,则创建新的线程,除非创建此线程超出 maximumPoolSize,在这种情况下,任务将被拒绝。
7、queueCapacity
任务队列容量。从maxPoolSize的描述上可以看出,任务队列的容量会影响到线程的变化,因此任务队列的长度也需要恰当的设置。
8、handler(回绝任务)
执行回绝的场景,当 Executor 已经关闭,并且 Executor 将有限边界用于最大线程和工作队列容量,且已经饱和时,在方法execute(java.lang.Runnable) 中提交的新任务将被拒绝。在以上两种情况下,execute 方法都将调用其RejectedExecutionHandler 的 RejectedExecutionHandler.rejectedExecution(java.lang.Runnable, java.util.concurrent.ThreadPoolExecutor) 方法。下面提供了四种预定义的处理程序策略:
A. 在默认的 ThreadPoolExecutor.AbortPolicy 中,(默认)回绝任务并抛出异常 RejectedExecutionException。
B. 在 ThreadPoolExecutor.CallerRunsPolicy 中,调用execute()的线程自己来处理该任务,绝大部分情况下是主线程。此策略提供简单的反馈控制机制,能够减缓新任务的提交速度。
注意:由于主线程执行这个任务,那么新到来的任务就不会被提交到线程池中执行(而是提交到TCP层的队列,TCP层队列满了,就开始拒绝,此时性能已经很低了),直到主线程执行完这个任务。
C. 在 ThreadPoolExecutor.DiscardPolicy 中,不能被执行的任务会直接被扔掉。
D. 在 ThreadPoolExecutor.DiscardOldestPolicy 中,如果执行程序尚未关闭,如果executor没有被关闭,队列头部的任务将会被丢弃,然后将该任务加到队尾,然后重试执行程序(如果再次失败,则重复此过程)。
定义和使用其他种类的 RejectedExecutionHandler 类也是可能的,但这样做需要非常小心,尤其是当策略仅用于特定容量或排队策略时。
注意1:AbortPolicy,CallerRunsPolicy,DiscardPolicy和DiscardOldestPolicy都是rejectedExecution的一种实现。
当然也可以自己定义个rejectedExecution实现。
详细见:《threadpool之五:拒绝策略示例及实现源码》
系统负载
参数的设置跟系统的负载有直接的关系,下面为系统负载的相关参数:
- tasks,每秒需要处理的最大任务数量
- tasktime,处理第个任务所需要的时间
- responsetime,系统允许任务最大的响应时间,比如每个任务的响应时间不得超过2秒。
三、三种阻塞队列
上面的workQueue参数,排队有三种通用策略:
- (同步移交)直接提交。工作队列的默认选项是
SynchronousQueue,它将任务直接提交给线程而不保持它们。在此,如果不存在可用于立即运行任务的线程,则试图把任务加入队列将失败,因此会构造一个新的线程。此策略可以避免在处理可能具有内部依赖性的请求集时出现锁。直接提交通常要求无界 maximumPoolSizes 以避免拒绝新提交的任务。当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。 - 无界队列。使用无界队列(例如,不具有预定义容量的
LinkedBlockingQueue)将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize。(因此,maximumPoolSize 的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web 页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。 - 有界队列。当使用有限的 maximumPoolSizes 时,有界队列(如
ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O 边界),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小,CPU 使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。
四、四种拒绝策略
详细见:《JDK线程池原理之四:拒绝策略示例及实现源码》
五、线程池executor执行逻辑
详细见:《threadpool之1--工作原理》
六、线程池的状态
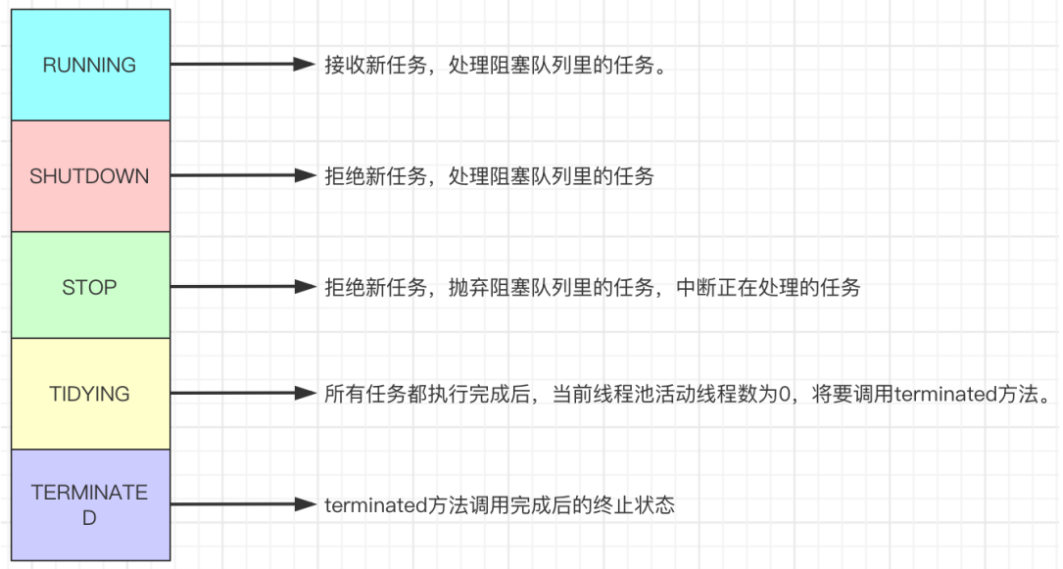
1、RUNNING
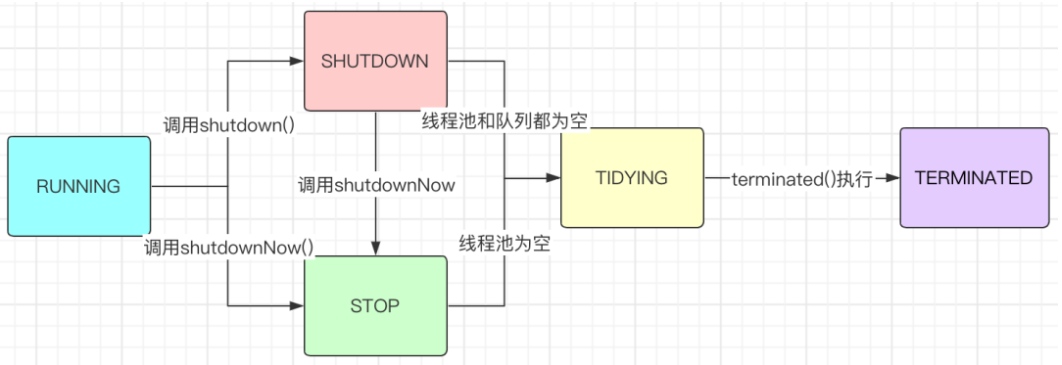
(1) 状态说明:线程池处在RUNNING状态时,能够接收新任务,以及对已添加的任务进行处理。
(02) 状态切换:线程池的初始化状态是RUNNING。换句话说,线程池被一旦被创建,就处于RUNNING状态,并且线程池中的任务数为0!
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));2、 SHUTDOWN
(1) 状态说明:线程池处在SHUTDOWN状态时,不接收新任务,但能处理已添加的任务。
(2) 状态切换:调用线程池的shutdown()接口时,线程池由RUNNING -> SHUTDOWN。
3、STOP
(1) 状态说明:线程池处在STOP状态时,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。
(2) 状态切换:调用线程池的shutdownNow()接口时,线程池由(RUNNING or SHUTDOWN ) -> STOP。
4、TIDYING
(1) 状态说明:当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现。
(2) 状态切换:当线程池在SHUTDOWN状态下,阻塞队列为空并且线程池中执行的任务也为空时,就会由 SHUTDOWN -> TIDYING。
当线程池在STOP状态下,线程池中执行的任务为空时,就会由STOP -> TIDYING。
5、 TERMINATED
(1) 状态说明:线程池彻底终止,就变成TERMINATED状态。
(2) 状态切换:线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING -> TERMINATED。
线程池不同状态之间的转换时机及转换关系如下图:
参考:
https://blog.csdn.net/yalear2012/article/details/100643010
https://blog.csdn.net/windrui/article/details/106346006?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161787948516780366581376%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=161787948516780366581376&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v2~rank_v29-1-106346006.nonecase&utm_term=%E7%BA%BF%E7%A8%8B%E6%B1%A0&spm=1018.2226.3001.4450

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步