Spark1.5堆内存分配
这是spark1.5及以前堆内存分配图

下边对上图进行更近一步的标注,红线开始到结尾就是这部分的开始到结尾
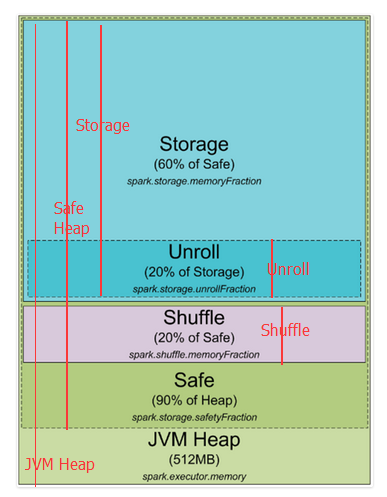
spark 默认分配512MB JVM堆内存。出于安全考虑和避免内存溢出,Spark只允许我们使用堆内存的90%,这在spark的spark.storage.safetyFraction 参数中配置着。也许你听说的spark是一个内存工具,Spark允许你存储数据在内存。其实,Spark不是真正的内存工具,它只是允许你使用内存的LRU(最近最少使用)缓存 。所以,一部分内存要被用来缓存你要处理的数据,这部分内存占可用安全堆内存的60%,这个值在spark.storage.memoryFraction参数中配置。所以如果你想知道你可以存多少数据在spark中,spark.storage.safetyFraction 默认值为0.9,spark.storage.memoryFraction的默认值为0.6,
Storage=总堆内存*0.9*0.6,所以你有54%的堆内存用来存储数据。
shuffle内存:
spark.shuffle.safetyFraction * spark.shuffle.memoryFraction
spark.shuffle.safetyFraction默认为0.8或80%,spark.shuffle.memoryFraction默认为0.2或20%,则你最终可以使用0.8*0.2=0.16或16%的JVM 堆内存用于shuffle。
Unroll内存:
spark允许数据以序列化或非序列化的形式存储,序列化的数据不能拿过来直接使用,所以就需要先反序列化,即unroll。
Heap Size*spark.storage.safetyFraction*spark.storage.memoryFraction*spark.storage.unrollFraction=Heap Size *0.9*0.6*0.2=Heap Size * 0.108或10.8%的JVM 堆内存。
到此为止,你应该就知道Spark是如何使用jvm内存的了,下边是集群模式,以yarn为例,其它类似。

在Yarn集群中,Yarn Resource Manager管理集群的资源(实际就是内存)和一系列运行在集群Node上yarn resource manager及集群Nodes资源的使用。从YARN的角度,每一个 Node都代表了一个可控制的内存资源,当你向Yarn Resource Manager申请资源时,它会反馈给你哪个yarn node manager 可以连接并启动一个execution container给你。每一个execution container都是一个可以提供堆内存的JVM,JVM的位置是由Yarn Resource manager选择的。
当你在Yarn上启动Spark时,你可以指定executor的数量(–num-executors flag or spark.executor.instances parameter)、每个executor的内存大小(–executor-memory flag or spark.executor.memory parameter)、每个executor的内核数量(–executor-cores flag of spark.executor.coresparameter)、每个task执行的内核数量(spark.task.cpusparameter),你也可以指定driver的内存大小(–driver-memory flag or spark.driver.memory parameter)。
当你在集群中执行某项任务时,一个job会被切分成stages,每个stage会被分成多个task,每个task会被单独分配,你可以把这些executor看成一个个执行task的槽池(a pool of tasks execution slots)。如下看一个例子:一个集群有12个节点(yarn node manager),每个节点有64G内存、32核的CPU(16个物理内核,一个物理内核可以虚拟成两个)。每个节点你可以启动两个executors、每个executor分配26G内存(留一部分用于system process、yarn NM、DataNode).所以集群一共可以处理 12 machines * 2 executors per machine * 12 cores per executor / 1 core for each task = 288 task slots。这意味着该集群可以并行运行288个task,充分利用集群的所有资源。你可以用来存储数据的内存为= 0.9 spark.storage.safetyFraction * 0.6 spark.storage.memoryFraction * 12 machines * 2 executors per machine * 26 GB per executor = 336.96 GB。没有那么多,但是也足够了。
到此,你已经知道spark如何分配 jvm内存,在集群中可以有多少个execution slots。那么什么是task,你可以把他想像成executor的某个线程,executor是一个进程 ,它可以多线程的执行task.
下边来解释一下另一个抽象概念"Partition",你用来分析的所有数据都将被切分成partitions,那么何为一个partition,它又是由什么决定的?partition的大小是由你使用的数据源决定的,在spark中你可以使用的所有读取数据的方式,大多你可以指定你的RDD中有多少个partitions。当你从HDFS中读取一个文件时,hadoop的InputFormat决定partition。通常由InputFormat输入的每一个 split对应于RDD中的一个partition,而每一个split通常相当于hdfs中的一个block(还有一些其它情况,暂不解释,如text file压缩后传过一整个partition不能直接使用)。
一个partition产生一个task,并在数据所在的节点task slot执行(数据本地性)
语言组织不是特别好,请见谅,如有失误之处,还请多提宝贵意见。
Snow nothing, reap nothing.

