


kettle菜鸟学习笔记2----第一个kettle转换的建立及执行
相关概念:
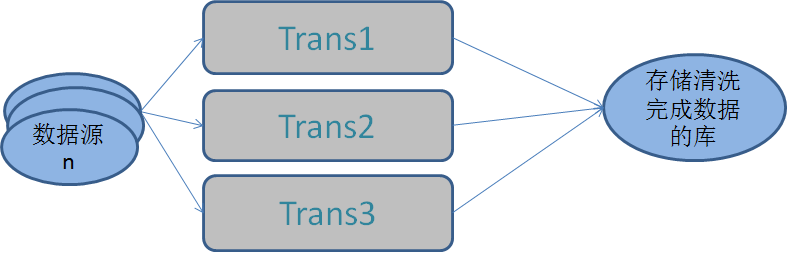
Kettle数据清洗是采用元数据(Meta-data)驱动,以数据流的方式进行的,数据从数据源(数据库/文件等)在一系列相连的step之间依次向后流动,各个step完成对流经该step的数据进行需要的处理工作。
Kettle中的数据转换组件按粒度从小到大分为Step、Trans、Job。
Step:是完成单一具体功能的组件,如从文件中读取数据、对流中的字段进行字符串拆分操作、对不能为空的字段设置相应默认值、将流中的数据写入到数据表等。
Trans:转换,一般最终清洗完成的数据库中有多少个标准表,就要有多少个Trans,通常与表是一一对应的。
Trans由多个Step组成,Step之间使用hop连接,实现数据在Step之间的流动,一系列Step的连接从而完成更复杂的转换。

Job:作业,由多个Trans组成,表示一次完整的数据清洗任务。
kettle的使用:
新建一个转换
1新建空白转换
文件—>新建—>转换 :新建一个空白的转换,ctrl+s保存该转换,命名为标准表的表名;
2添加数据库连接

在主对象树中,双击DB连接,或右击DB连接,选择新建数据库连接,打开数据库连接对话框:

其中Oracle数据库连接中的数据表空间,索引表空间两项不需要填。其余参数必填,填好之后点测试,检测是否能正确连接,连接成功后,点确认,便保存了当前连接。
其实,可以随时在需要的时候建立数据库连接,而不必刚开始就添加。
3添加需要的step
在核心对象的各个分组中,找到需要的step,双击,或者拖拽到右侧设计界面,即可添加step到当前转换中。
简单示例:新建一个转换,实现生成10000条测试数据,存放到mysql中的表t1中,t1只有两个字段,一个是整型,一个是varchar。
step1:新建一个空白转换,保存,文件名为data_gen.ktr
step2:在核心对象树中找到“输入”分组中的“生成记录”这个Step,并拖放到右边的工作区中
Step3:在“转换”分组中,找到“添加序列”,并拖放到工作区中

Step4:在“输出”分组中,找到“表输出”Step,并拖放到工作区中

Step5:单击选中“生成记录”,然后按住shift+鼠标左键,拖至“增加序列”,如此,便在这两个Step中建立了一个Hop,将这两个Step链接起来,注意hop是有向的。
同样的方法链接“增加序列”和“表输出”

Step6:双击“生成记录”配置该Step的元数据信息:

如图中的修改,步骤名称更改为“生成字符串”;限制改为“10000“,表示生成10000条记录;字段列表中,如图填写,名称随意,类型在下拉列表中选择String,值填写”aaaa”,其他留空,不要填写。然后,点击确定即可。
Step7:双击“增加序列”,配置其元数据信息:
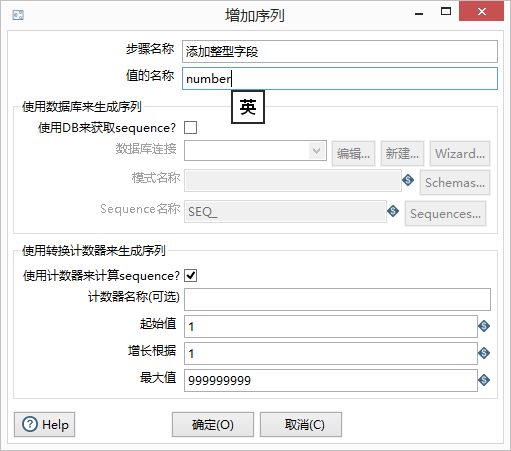
如图填写:值的名称即为当前添加字段的名称,使用计数器来生成序列,会生成从1递增的序列,可以修改起始值即步长。最大值可以修改为10000,不设置也行,因为它之前的Step结束后,它也跟着结束了。
Step8:双击表输出,配置其元数据信息:
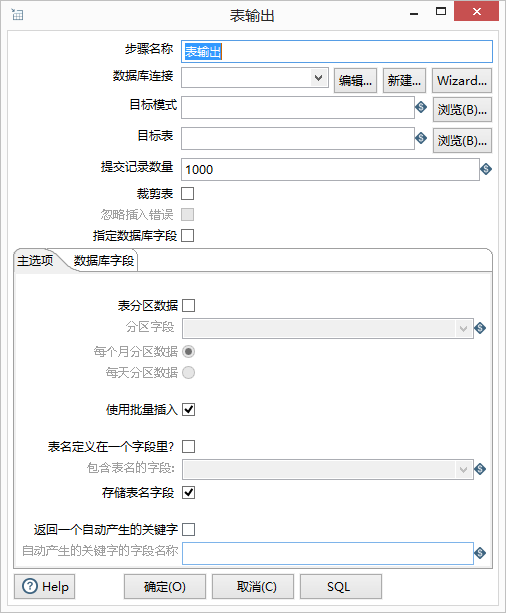
点数据库连接后面的“新建”按钮,即为创建一个数据库连接。
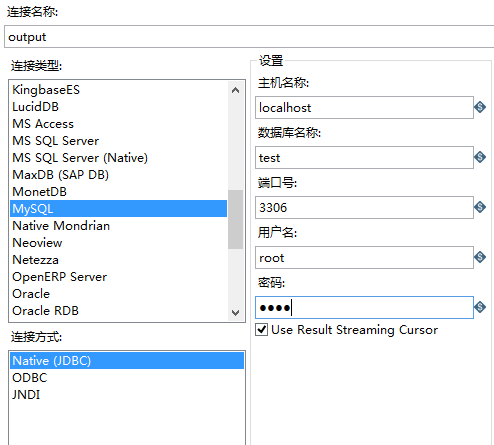
根据自己数据库的实际情况,设置上述信息,最好点击下连接测试,防止信息填写错误。
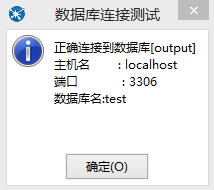
测试通过,后确认即可保存该数据库连接,此时表输出设置窗口的数据库连接自动填上了刚才建立的连接:

点击目标表后的“浏览”按钮,选择要存放数据的表:

如上图,我选择了t1表存放生成的数据。
提交记录数量,是每多少条数据提交一次,这里可以默认。
勾选指定数据库字段,否则下面没法设置:

然后切换到数据库字段选项卡,点击输入字段映射,会自动获取流入该Step中数据的各个字段名,以及该表中的字段名。
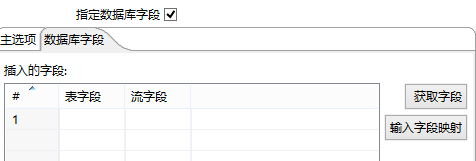

点击源字段中的某个字段,然后点击目标中的某个字段,然后点击add按钮,表示两者之间建立了一个映射,该源字段的值都存在对应的目标字段中。当源字段与目标字段的名字有相同字符串时,可以使用猜一猜,自动匹配,不过不保证准确性。
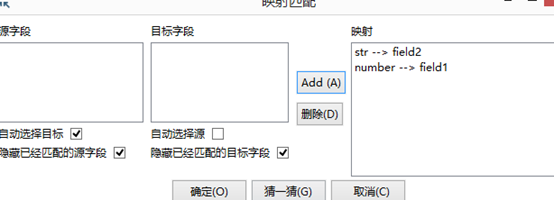
匹配完成,点击确定。
如上,这个转换就建立完成了,注意Ctrl+S保存。
Step9:运行该转换,查看结果:
点击:三角形按钮,表示执行
在弹出的窗口中,点“启动”即可。
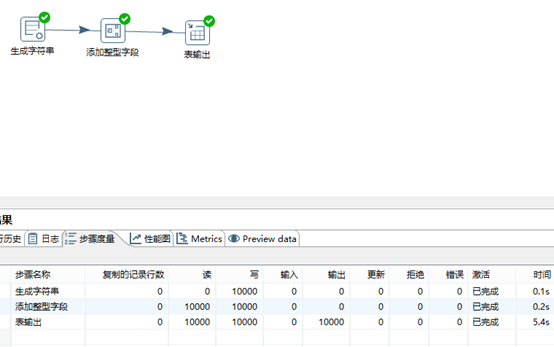
成功执行后,出现如下信息:若失败,会出现红色的“×”,并且会在下面日志中记录错误的Step及错误信息。
查看t1表中有无数据:
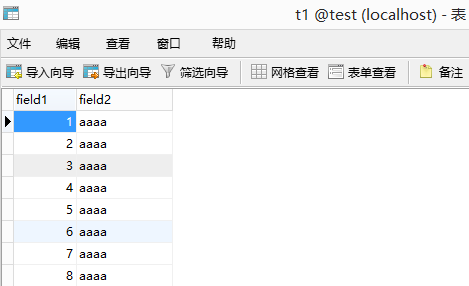

如上,便成功生成了10000条测试数据。

