


Deep Learning 13_深度学习UFLDL教程:Independent Component Analysis_Exercise(斯坦福大学深度学习教程)
前言
理论知识:UFLDL教程、Deep learning:三十三(ICA模型)、Deep learning:三十九(ICA模型练习)
实验环境:win7, matlab2015b,16G内存,2T机械硬盘
难点:本实验难点在于运行时间比较长,跑一次都快一天了,并且我还要验证各种代价函数的对错,所以跑了很多次。
实验内容:Exercise:Independent Component Analysis。从数据库Sampled 8x8 patches from the STL-10 dataset (stl10_patches_100k.zip)(它是从数据库the STL-10 dataset中抽取10万个大小为8*8的3通道彩色小图像块,也是Deep Learning 9_深度学习UFLDL教程:linear decoder_exercise(斯坦福大学深度学习教程)中的训练集)中随机选择2万个小图像块作为本节实验训练集,利用ICA算法学习它的线性独立标准正交基,并显示出来。
实验基础说明:
1.本节实验中要学习的标准正交基与Deep Learning 12_深度学习UFLDL教程:Sparse Coding_exercise(斯坦福大学深度学习教程)中学习到的“超完备”基的异同,即本节实验的意义?
①不同点:本节实验中的基是标准正交的,也是线性独立的,而Deep Learning 12_深度学习UFLDL教程:Sparse Coding_exercise(斯坦福大学深度学习教程)中的基的个数比原始数据还多,所以它的基不一定是线性独立的,尽管稀疏编码学习到的基在某些情况下这已经满足需要,但有时我们仍然希望得到的是一组线性独立基。在稀疏编码中,权值矩阵 A 用于将特征 s 映射到原始数据x,而在ICA算法中,权值矩阵 W 工作的方向相反,是将原始数据 x 映射到特征,即ICA算法学习到的特征是Wx
②相同点:稀疏编码和ICA算法学习到的特征都要求是稀疏的。
2.Ng为什么说投影步骤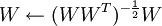 实际上可以看成就是ZCA白化?下面是我的个人理解
实际上可以看成就是ZCA白化?下面是我的个人理解
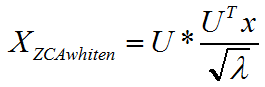
而投影步骤的整个过程是:

通过对比以上两者公式可知,投影步骤可以看成是ε为0的ZCA白化(即:无正则ZCA白化),其中,ZCA白化中的数据旋转方向U相当于投影步骤中的W,ZCA白化中的特征值λ相当于投影步骤中的(WWT)3。
3.数据必须经过无正则 ZCA白化(也即,ε设为0),但是为什么?下面是我的个人理解
因为前面已经说了,标准正交基W的投影步骤实际上就是无正则ZCA白化,而特征为Wx,用特征和基表示的原始数据为WTWx(原因见下面的解释),为了统一,使特征Wx和WTWx也是白化的,就需要也对原始数据x做无正则ZCA白化
4.代价函数及其梯度
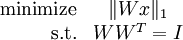
标准约束项WWT = I通过投影步骤实现,所以实现时代价函数为:
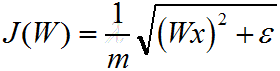
其代价函数对W的梯度或偏导为:

该矩阵求导公式的推导,可参考Deep learning:二十七(Sparse coding中关于矩阵的范数求导)、http://www.mathchina.net/dvbbs/dispbbs.asp?boardid=4&Id=3673和The Matrix Cookbook。
5.代价函数的推导
通过以前本人对Ng的代价函数推导的理解(即:Deep Learning 12_深度学习UFLDL教程:Sparse Coding_exercise(斯坦福大学深度学习教程)),推导本实验的代价函数,而Deep learning:三十九(ICA模型练习)中并没有推导这些,而且从我的推导结果可知他的代价函数形式是错误的(准确地说,可能也不叫错误,因为它只是增加了一项非常复杂的多余的项,这一项的值永远不会变,并且使运行时间加大了1倍多,但还是可以提取出标准正交基),我觉得这是因为他并没有理解代价函数是怎么来的,实际这一点完全可从他整篇文章中看出来。
本节实验中,我们希望学习得到一组基向量――以列向量形式构成的矩阵 W,其满足以下特点:首先,与稀疏编码一样,特征是稀疏的;其次,基是标准正交的。
①稀疏惩罚项:因为要求学习到的特征是稀疏的,且学习到的特征表示为Wx,所以代价函数必须要有如下稀疏惩罚项:
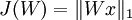 , 其中,
, 其中,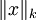 是x的Lk范数,等价于
是x的Lk范数,等价于 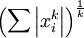 。L1 范数是向量元素的绝对值之和
。L1 范数是向量元素的绝对值之和
又因为以后我们为求代价函数的最小值,会对代价函数求导,而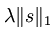 对s在0点处不可导的(理解:y=|x|在x=0处不可导),所以为了方便以后求代价函数最小值,可把替换为
对s在0点处不可导的(理解:y=|x|在x=0处不可导),所以为了方便以后求代价函数最小值,可把替换为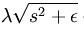 ,其中ε 是“平滑参数”("smoothing parameter")或者“稀疏参数”("sparsity parameter") 。所以把以上代价函数改为:
,其中ε 是“平滑参数”("smoothing parameter")或者“稀疏参数”("sparsity parameter") 。所以把以上代价函数改为:
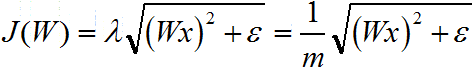
其中,m为样本个数,λ为1/m,是稀疏惩罚项的权重。
②标准正交项:因为要求学习到的基W是标准正交的,所以代价函数必须有以下约束:
WWT = I
在实际实现这一约束过程中,并没有把代价函数中应包含的这一标准正交约束加入到代价函数中,而是把它放到利用梯度下降法优化代价函数阶段。也就是,用梯度下降法优化代价函数时,在梯度下降的每一步中增加投影步骤,以满足标准正交约束。所以,在编程写代价函数并求它梯度(即:orthonormalICACost.m)时,实际上并没有包含这一标准正交项。
③重构项:因为本节实验的目的是寻找数据X的标准正交基W,并把它显示出来。而学习到的特征表示为Wx,所以联系上节实验(即:Deep Learning 12_深度学习UFLDL教程:Sparse Coding_exercise(斯坦福大学深度学习教程))可知把数据x用标准正交基W表示出来的形式为:WTWx,即:x=基*特征集 。
为了使数据x和WTWx之间的误差最小,那么代价函数必须要包括这两者的均方差,并且要使这个均方差最小,即最小化如下项:
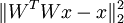 ,其中,L2范数就是平方和的开方。
,其中,L2范数就是平方和的开方。
上面的形式只是Adrew Ng在用反向传导思想求导中的表达,实际上需要再除以样本数m才是真正的均方差。
所以代价函数也应该包含上面这个重构项。但是因为代价函数有标准正交约束WWT = I,所以可推知只要W满足标准正交约束,那么这个重构项就永远为0。这一点并不仅是我猜测,我还通过编程实践证明这个重构项恒等于0.003550。证明很简单,只需要把Deep learning:三十九(ICA模型练习)中orthonormalICACost.m改为如下即可:
function [cost, grad] = orthonormalICACost(theta, visibleSize, numFeatures, patches, epsilon) %orthonormalICACost - compute the cost and gradients for orthonormal ICA % (i.e. compute the cost ||Wx||_1 and its gradient) weightMatrix = reshape(theta, numFeatures, visibleSize); cost = 0; grad = zeros(numFeatures, visibleSize); % -------------------- YOUR CODE HERE -------------------- % Instructions: % Write code to compute the cost and gradient with respect to the % weights given in weightMatrix. % -------------------- YOUR CODE HERE -------------------- %% 方法 lambda = 8e-6;% 0.5e-4 num_samples = size(patches,2); cost_part1 = sum(sum((weightMatrix'*weightMatrix*patches-patches).^2))./num_samples; cost_part2 = sum(sum(sqrt((weightMatrix*patches).^2+epsilon)))*lambda; cost = cost_part1 + cost_part2; grad = (2*weightMatrix*(weightMatrix'*weightMatrix*patches-patches)*patches'+... 2*weightMatrix*patches*(weightMatrix'*weightMatrix*patches-patches)')./num_samples+... (weightMatrix*patches./sqrt((weightMatrix*patches).^2+epsilon))*patches'*lambda; grad = grad(:); fprintf('%11s%16s\n','cost_part1','cost_part2'); fprintf(' %14.6f %14.6f\n', cost_part1, cost_part2); end
然后运行ICAExercise.m,运行结果中cost_part1就是重构项的值,它恒等于0.003550,不会随着迭代次数的增加而减少。
因此在orthonormalICACost.m中实现的代价函数,实际上只包含了稀疏惩罚项。
综上,orthonormalICACost.m中代价函数为:
实验步骤
1.初始化参数,加载数据库。
2.把数据进行无正则ZCA白化。注意把ε设为0。
3.实现ICA算法的代价函数及梯度计算(见orthonormalICACost.m),并检查梯度计算是否正确。注意,这一步中并没有把代价函数中应包含的标准正交约束加入到代价函数中,而是把它放下一步,即利用梯度下降法优化代价函数阶段。具体做法就是:在梯度下降的每一步中增加投影步骤,以满足标准正交约束。
4.利用梯度下降法优化代价函数,同时在梯度下降的每一步中增加投影步骤,以满足标准正交约束,并且用线搜索算法(见Convex Optimization by Boyd and Vandenbergh)来加速梯度。
5.得到优化结果,并把权值矩阵weightMatrix(它就是我们要求的线性独立标准正交基)显示出来。
结果
部分原始数据:

迭代1万次的结果:

迭代2万次的结果:

迭代5万次的结果:

对比可知,5万次的运行结果比Ng的结果更好一点。
我也运行了Deep learning:三十九(ICA模型练习)中的代码,实现了作者的意图,但是他的代码实在运行时间太长。整个实验实际上不算难,主要是代码运行时间长,以及代价函数的理解。
代码
ICAExercise.m
%% CS294A/CS294W Independent Component Analysis (ICA) Exercise % Instructions % ------------ % % This file contains code that helps you get started on the % ICA exercise. In this exercise, you will need to modify % orthonormalICACost.m and a small part of this file, ICAExercise.m. %%====================================================================== %% STEP 0: Initialization % Here we initialize some parameters used for the exercise. numPatches = 20000; numFeatures = 121; imageChannels = 3; patchDim = 8; visibleSize = patchDim * patchDim * imageChannels; outputDir = '.'; epsilon = 1e-6; % L1-regularisation epsilon |Wx| ~ sqrt((Wx).^2 + epsilon) %%====================================================================== %% STEP 1: Sample patches patches = load('stlSampledPatches.mat'); patches = patches.patches(:, 1:numPatches); displayColorNetwork(patches(:, 1:100)); %%====================================================================== %% STEP 2: ZCA whiten patches % In this step, we ZCA whiten the sampled patches. This is necessary for % orthonormal ICA to work. patches = patches / 255; meanPatch = mean(patches, 2); patches = bsxfun(@minus, patches, meanPatch); sigma = patches * patches'; [u, s, v] = svd(sigma); ZCAWhite = u * diag(1 ./ sqrt(diag(s))) * u'; patches = ZCAWhite * patches; %%====================================================================== %% STEP 3: ICA cost functions % Implement the cost function for orthornomal ICA (you don't have to % enforce the orthonormality constraint in the cost function) % in the function orthonormalICACost in orthonormalICACost.m. % Once you have implemented the function, check the gradient. % Use less features and smaller patches for speed debug = false; if debug numFeatures = 5; patches = patches(1:3, 1:5); visibleSize = 3; numPatches = 5; weightMatrix = rand(numFeatures, visibleSize); [cost, grad] = orthonormalICACost(weightMatrix, visibleSize, numFeatures, patches, epsilon); numGrad = computeNumericalGradient( @(x) orthonormalICACost(x, visibleSize, numFeatures, patches, epsilon), weightMatrix(:) ); % Uncomment to display the numeric and analytic gradients side-by-side % disp([numGrad grad]); diff = norm(numGrad-grad)/norm(numGrad+grad); fprintf('Orthonormal ICA difference: %g\n', diff); assert(diff < 1e-7, 'Difference too large. Check your analytic gradients.'); fprintf('Congratulations! Your gradients seem okay.\n'); end %%====================================================================== %% STEP 4: Optimization for orthonormal ICA % Optimize for the orthonormal ICA objective, enforcing the orthonormality % constraint. Code has been provided to do the gradient descent with a % backtracking line search using the orthonormalICACost function % (for more information about backtracking line search, you can read the % appendix of the exercise). % % However, you will need to write code to enforce the orthonormality % constraint by projecting weightMatrix back into the space of matrices % satisfying WW^T = I. % % Once you are done, you can run the code. 10000 iterations of gradient % descent will take around 2 hours, and only a few bases will be % completely learned within 10000 iterations. This highlights one of the % weaknesses of orthonormal ICA - it is difficult to optimize for the % objective function while enforcing the orthonormality constraint - % convergence using gradient descent and projection is very slow. weightMatrix = rand(numFeatures, visibleSize); [cost, grad] = orthonormalICACost(weightMatrix(:), visibleSize, numFeatures, patches, epsilon); fprintf('%11s%16s%10s\n','Iteration','Cost','t'); startTime = tic(); % Initialize some parameters for the backtracking line search alpha = 0.5; t = 0.02; lastCost = 1e40; % Do 10000 iterations of gradient descent for iteration = 1:50000 grad = reshape(grad, size(weightMatrix)); newCost = Inf; linearDelta = sum(sum(grad .* grad)); % Perform the backtracking line search while 1 considerWeightMatrix = weightMatrix - alpha * grad; % -------------------- YOUR CODE HERE -------------------- % Instructions: % Write code to project considerWeightMatrix back into the space % of matrices satisfying WW^T = I. % % Once that is done, verify that your projection is correct by % using the checking code below. After you have verified your % code, comment out the checking code before running the % optimization. % % Project considerWeightMatrix such that it satisfies WW^T = I % error('Fill in the code for the projection here'); considerWeightMatrix = (considerWeightMatrix*considerWeightMatrix')^(-0.5)*considerWeightMatrix; % Verify that the projection is correct temp = considerWeightMatrix * considerWeightMatrix'; temp = temp - eye(numFeatures); assert(sum(temp(:).^2) < 1e-23, 'considerWeightMatrix does not satisfy WW^T = I. Check your projection again'); error('Projection seems okay. Comment out verification code before running optimization.'); % -------------------- YOUR CODE HERE -------------------- [newCost, newGrad] = orthonormalICACost(considerWeightMatrix(:), visibleSize, numFeatures, patches, epsilon); if newCost > lastCost - alpha * t * linearDelta % fprintf(' %14.6f %14.6f\n', newCost, lastCost - alpha * t * linearDelta); t = 0.9 * t; else break; end end lastCost = newCost; weightMatrix = considerWeightMatrix; fprintf(' %9d %14.6f %8.7g\n', iteration, newCost, t); t = 1.1 * t; cost = newCost; grad = newGrad; % Visualize the learned bases as we go along if mod(iteration, 1000) == 0 duration = toc(startTime); % Visualize the learned bases over time in different figures so % we can get a feel for the slow rate of convergence figure(floor(iteration / 1000)); displayColorNetwork(weightMatrix'); end end % Visualize the learned bases displayColorNetwork(weightMatrix');
orthonormalICACost.m
function [cost, grad] = orthonormalICACost(theta, visibleSize, numFeatures, patches, epsilon) %orthonormalICACost - compute the cost and gradients for orthonormal ICA % (i.e. compute the cost ||Wx||_1 and its gradient) weightMatrix = reshape(theta, numFeatures, visibleSize); cost = 0; grad = zeros(numFeatures, visibleSize); % -------------------- YOUR CODE HERE -------------------- % Instructions: % Write code to compute the cost and gradient with respect to the % weights given in weightMatrix. % -------------------- YOUR CODE HERE -------------------- %% num_samples = size(patches,2); %样本个数 aux1 = sqrt(((weightMatrix*patches).^2) + epsilon); cost = sum(aux1(:))/num_samples; grad = ((weightMatrix*patches)./aux1)*patches'./num_samples; grad = grad(:); end
参考资料

