



WordCountPro
github项目地址:https://github.com/Hoyifei/SQ-T-Homework-WordCount-Advanced
PSP表格
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
15 | 10 |
|
· Estimate |
· 估计这个任务需要多少时间 |
10 | 10 |
|
Development |
开发 |
400 | 380 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
30 | 40 |
|
· Design Spec |
· 生成设计文档 |
20 | 30 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
50 | 40 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
30 | 30 |
|
· Design |
· 具体设计 |
40 | 50 |
|
· Coding |
· 具体编码 |
400 | 420 |
|
· Code Review |
· 代码复审 |
20 | 30 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
60 | 70 |
|
Reporting |
报告 |
30 | 20 |
|
· Test Report |
· 测试报告 |
20 | 20 |
|
· Size Measurement |
· 计算工作量 |
10 | 20 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 | 30 |
|
合计 |
1150 | 1200 |
本次项目我负责的代码为src/test/com/wordcount/BasicMainTestGenerator.java,MainTestGenerator.java PressureTest.java,WordCountPar.java,PairComparator.java
以及src/test/com/wordcount/trie/testcasegenerator/和src/test/com/wordcount/wordsplitter/testcasegenerator
我主要负责做出测试数据生成器:
从黑盒的角度编写代码生成了各个单元测试和整体测试中数据量较大的测试用例及其答案,以及压力测试用的超大数据(最大的数据大约有数百MB)
设计思路:
(1)词频统计模块测试数据生成:
词频统计模块的测试方法是:输入文件每行包含一个单词,输出全部的词频统计结果
生成方法:
1、随机生成一定数量的单词
首先生成一个开头的字母
然后确定随机步数
在之后的数步中,每步向单词中随机添加一个字母或者连字符+随机字母
最后将新生成的单词与之前已有的单词比对。如果与其中任何一个均不重复则将其加入列表,否则重新生成。
(此步骤中所有字母均为小写)
2、从所有生成的单词中随机挑选并输出
每次从所有的单词中挑选一个,随机改变字母的大小写,然后输出,同时记录该单词的词频
3、对随机的单词进行词频排序并输出答案
使用Java自带的排序函数对单词进行排序并输出所有词频非0的结果作为答案
(2)分词模块测试数据生成;
分词模块的测试方法是:输入文件的要求同题目要求,输出每行一个单词作为分词结果
生成方法:
以一定概率生成:字母,连字符和分隔符
记录当前是否位于单词内
如果生成字母,则当前位于单词内,输出该字母
如果生成连字符,判定当前是否位于单词内,如果不位于单词内,则首先生成一个开头的字母。无论是否位于单词内,连字符后紧接着生成一个字母
如果生成分隔符,首先判定是否位于单词内,如果位于单词内则将当前单词输出到答案。之后随机挑选一个符号输出。如果选择连字符作为分隔符,则紧接着再随机挑选一个符号输出。
由于连字符本身的规则较为复杂,因此赋予连字符和作为分隔符的连字符以较大的概率
(3)整体测试测试数据生成
整体测试的数据要求与题目要求一致
生成方法:
1、随机生成一定数量的单词
2、在文件开头随机生成0~n个分隔符
3、进行一定数量的随机步骤,每步随机挑选1个单词输出,之后输出1~n个分隔符,同时统计词频。随机生成1个分隔符时不会选择连字符
4、使用Java自带的排序函数对单词进行排序并输出至多前100个词频非0的结果作为答案
此外,我还负责整个系统的压力测试。
压力测试采用整体测试的数据生成步骤,但是不对答案进行排序和输出,从网上下载五个数据量大的英文小说作为系统的输入文件,其余十五个由压力测试数据生成器随机生成。
case1:《人性的弱点》英文版,数据量619K
case2:《无人生还》英文版,数据量309K
case3:《英特尔汇编手册》英文版,数据量164K
case4:《苏菲的世界》英文版,数据量1810K
case5:《算法导论》英文版,数据量2110K
以下为压力测试结果
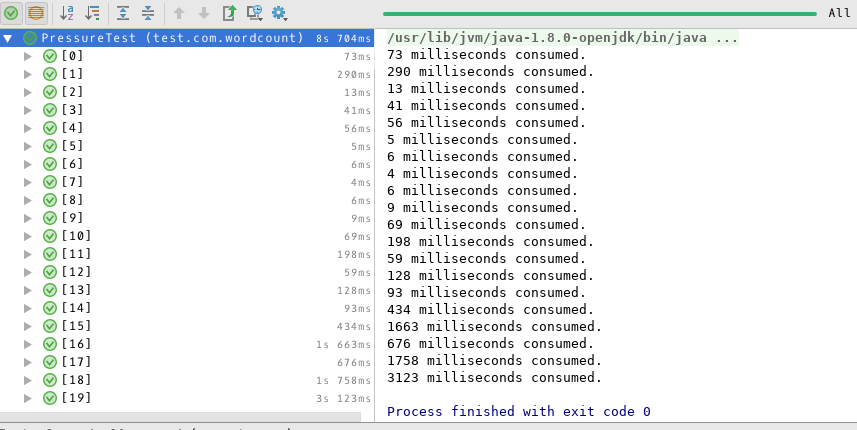
优化方面,制约该系统的主要因素在于文件读入,很难进行进一步优化,可以通过分段读入文件的方式减少内存的占用,但是会增加文件读入的时间。
测试评价:
所有的压力测试用时较短,系统的质量水平较高,可进行正常的词频统计排序的工作。
开发规范:
我选取的是阿里巴巴java开发手册。
静态代码检查:
安装静态检查插件IDEA后,编码过程中IDE实时给出了提示,因此最终没有统计数据,但是代码基本符合编码规范
参考文献:https://blog.csdn.net/xjbclz/article/details/51737249

