
[翻译]Kafka Streams简介: 让流处理变得更简单
这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams。当时Kafka Streams还没有正式发布,所以具体的API和功能和0.10.0.0版(2016年6月发布)有所区别。但是Jay Krpes在这简文章里介绍了很多Kafka Streams在设计方面的考虑,还是很值得一看的。
以下的并不会完全按照原文翻译,因为那么搞太累了……这篇文件的确很长,而且Jay Kreps写的重复的地方也挺多,有些地方也有些故弄玄虚的意思。不过他想说的道理倒挺容易搞清楚。
我很高兴能宣布Kafka的新特性-Kafka Streams的预览。Kafka Streams是一个使用Apache Kafka来构造分布式流处理程序的Java库。它前作为Kafka 0.10版本的一部分,其源码在Apache Kafka项目下。。
使用Kafka Streams构建的一个流处理程序看起来像是这样:

需要注意的是:Kafka Streams是一个Java库,而不是一个流处理框架,这点和Strom等流处理框架有明显地不同
这个程序和0.10.0.0版在细节上有很多不同。对Kafka 0.10.0.0版的Kafka Streams, 实际能运行的例子可以在Kafka Streams工程的examples包底下找到。需要注意的是,这个例子使用了lambda表达式,这是JAVA8的特性。
在KStream的构造上,体现了它跟Kafka的紧密关系。比如,它默认的输入流的元素就是K,V对形式的,输出流也是这样,因此在构造输入输出流时需要分别指定K和V的Serde。其中KStream的API使用了很多集合函数,像map, flatMap, countByKey等,这个也可以称为Kafka Streams的DSL。
虽然只是一个库,但是Kafka Streams直接解决了在流处理中会遇到的很多难题:
- 一次一件事件的处理(而不是microbatch),延迟在毫秒
- 有状态的处理,包括分布式join和aggregation
- 一个方便的DSL
- 使用类似于DataFlow的模型来处理乱序数据的windowing问题
- 分布式处理,并且有容错机制,可以快速地实现failover
- 有重新处理数据的能力,所以当你的代码更改后,你可以重新计算输出。
- 没有不可用时间的滚动布署。
对于想要跳过这些前言,想直接看文档的人,你们可以直接去到Kafka Streams documention. 这个blog的目的在于少谈"what"(因为相关的文档会进行详细地描述),多谈"why"。
但是,它到底是啥呢?
Kafka Streams是一个用来构建流处理程序的库,特别是其输入是一个Kafka topic,输出是另一个Kafka topic的程序(或者是调用外部服务,或者是更新数据库,或者其它)。它使得你以一种分布式以及容错的方式来做这件事情。
在流处理领域有很多正在进行的有趣的工作,包括像 Apache Spark, Apache Storm, Apache Flink, 和 Apache Samza这样的的开源框架,也包括像Google’s DataFlow 和 AWS Lambda一样的专有服务。所有,需要列一下Kafka Streams和这些东西的相似以及不同的地方。
坦率地说,在这个生态系统中,有开源社区带来的非常多的各种杂乱地创新。我们对于所有这些不同的处理层(processing layer)感到很兴奋:尽管有时候这会让人感到有点困惑,但是技术水平的确在很快地进步。我们想让Kafka能够成为所有这些处理层的合适的数据源。我们想要Kafka Streams填充的空缺不大在于这些框架所关注的分析领域,而在于构建用于处理流式数据的核心应用和微服务。我在下面一节将会深入讲述这些不同之处,并且开始讲解Kafka Streams是怎么使这种类型的程序更简单的。
嬉皮士,流处理,和Kafka
如果想要知道一个系统设计是否在真实情况下工作良好,唯一的方法就是把它构建出来,把它用于真实的程序,然后看看它有什么不足。在我之前在LinkedIn的工作中,我很幸运地能够成为设计和构造流处理框架Apache Samza的小组的成员。我们把它推出到一系列内部程序之中,在生产中提供为它提供支持,并且帮助把它作为一个Apache项目开源。
那么,我们学到了什么呢?很多。我们曾经有过的一个关键的错觉是以为流处理将会被以一种类似于实时的MapReduce层的方式使用。我们最终却发现,大部分对流处理有需求的应用实际上和我们通常使用Hive或者Spark job所做的事情有很大不同,这些应用更接近于一种异步的微服务,而不是批量分析任务的快速版本。
我所说是什么意思呢?我的意思是大部分流处理程序是用来实现核心的业务逻辑,而不是用于对业务进行分析。
构建这样的流处理程序需要解决的问题和典型的MapReduce或Spark任务需要解决的分析或ETL问题是非常不同的。它们需要通常的程序所经历的处理过程,比如配置,布署,监控,等。简而言之,它们更像是微服务(我知道这是一个被赋予了过多意义的名词),而不像是MapReduce任务。Kafka取代了HTTP请求为这样的流处理程序提供事件流(event streams)。
之前的话,人们用Kafka构造流处理程序时有两个选择:
1. 直接拿Consumer和Producer的API进行开发
2. 采用一个成熟的流处理框架
这两种选择各有不足。当直接使用Kafka consumer和producer API时,你如果想要实现比较复杂的逻辑,像聚合和join,就得在这些API的基础上自己实现,还是有些麻烦。如果用流处理框架,那么就添加了很多很多复杂性,对于调试、性能优化、监控,都带来很多困难。如果你的程序既有同步的部分,又有异步的部分,那么就就不得不在流处理框架和你用于实现你的程序的机制之间分隔开。
虽然,事情不总是这样。比如你已经有了一个Spark集群用来跑批处理任何,这时候你想加一个Spark Streaming任务,额外添加的复杂性就挺小。但是,如果你专门为了一个应用布署一个Spark集群,那么这的确大大增加了复杂性。
但是,我们对Kafka的定位是:它应该成为流处理的基本元素,所以我们想要Kafka提供给你能够摆脱流处理框架、但是又具有非常小的复杂性的东西。
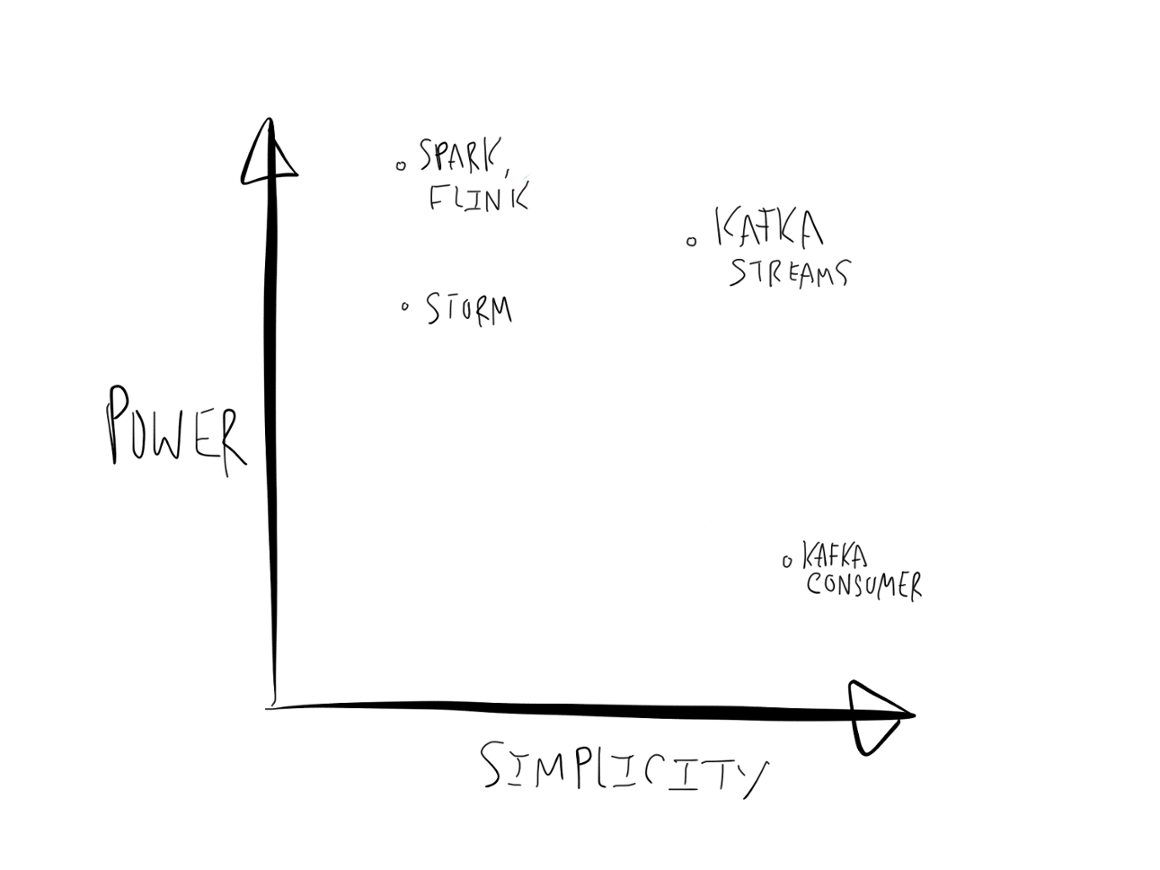
我们的目的是使流处理足够简化,使它能够成为构造异步服务的主流编程模型。这有很多种方法,但是有三个大的方面是想在这个blog里深入讨论一下:
这三个方面比较重要,所以把英文也列出来。
- Making Kafka Streams a fully embedded library with no stream processing cluster—just Kafka and your application.
- Fully integrating the idea of tables of state with streams of events and making both of these available in a single conceptual framework.
- Giving a processing model that is fully integrated with the core abstractions Kafka provides to reduce the total number of moving pieces in a stream architecture.
- 使得Kafka Streams成为一个嵌入式的libray,而不依赖于任何流处理框架。
- 把“有状态的表”和"事件流“紧密结合,使它们在同一个概念框架内可用。
- 提供一个和Kafka的核心抽象完全整合的处理模型,来减少流处理架构内的不确定部分的数量。
下面对每个方面单独进行讨论。
简化点1: 不依赖框架的流处理
Kafka Streams使得构建流处理服务更简单的第一点就是:它不依赖于集群和框架,它只是一个库(而且是挺小的一个库)。你只需要Kafka和你自己的代码。Kafka会协调你的程序代码,使得它们可以处理故障,在不同程序实例间分发负载,在新的程序实例加入时重新对负载进行平衡。
我下面会讲一下为什么我认为这是很重要的,以及我们之前的一点经历,来帮助理解这个模型的重要性。
治愈MapReduce的宿醉
我前边讲到我们构造Apache Samza的经历,以及人们实际想要的(简单的流服务)和我们构建的东西(实时的MapReduce)之间的距离。我认为这种概念的错位是普遍的,毕竟流处理做的很多事情是从批处理世界中接管一些能力,用于低延迟的领域。同样的MapReduce遗产影响了其它主流的流处理平台(Storm, Spark等),就像它们对Samza的影响一样。
在LinkedIn在很多生产数据的处理服务是属于低延迟领域的:email, 用户生成的内容,新消息反馈等。其它的很多公司也应该有类似的异步服务,比如零售业需要给商品排序、重新定价,然后卖出,对于金融公司,实时数据更是核心。大部分这些业务,都是异步的,对于渲染页面或者更新移动app的屏幕就不会有这样的问题(这些是同步的)。
那么为什么在Storm, Samza, Spark Streaming这样的流处理框架之上构建这样的核心应用这么繁琐呢?
一个批处理框架,像是MapReduce或者Spark需要解决一些困难的问题:
- 它必须在一个机器池之上管理很多短期任务,并且在集群中有效地调度资源分配
- 为了做到这点,它必须动态地把你的代码、配置、依赖的库以及其它所有需要的东西,打包并且物理地布署到将要执行它的机器上。
- 它必须管理进程,并且实现共享集群的不同任务之间的隔离。
不幸的是,为了解决这些问题,框架就得变得很有侵入性。为了做到容错和扩展,框架得控制你的程序如何布署、配置、监控和打包。
那么,Kafka Streams有什么不同呢?
Kafka Streams对它想要解决的问题要更关注得多。它做了以下的事情:
- 当你的程序的新的实例加入,或已经有实例退出时,它会重新平衡要处理的负载
- 维护表的本地状态
- 从错误中恢复
它使用了Kafka为普通的consumer所提供的同样的组管理协议(group manager protocol)来实现。Kafka Streams可以有一些本地的状态,存储在磁盘上,但是它只是一个缓存。如果这个缓存丢失了,或者这个程序实例被转移到了别的地方,这个本地状态是可以被重建的。你可以把Kafka Streams这个库用在你的程序里,然后启动任意数量的你想要程序实例,Kafka将会把它们进行分区,并且在这些实例间进行负载的平衡。
这对于实现像滚动重启(rolling restart)或者无宕机时间的扩展(no-downtime expansion)这样简单的事情是很重要的。在现代的软件工程中,我们把这样的功能看做是应该的,但是很多流处理框架却做不到这点。
Dockers, Mesos, 以及Kurbernetes, 我的天哪!
从流处理框架中分离出打包和布署的原因是,打包和布署这个领域本身就正在进行自身的复兴。Kafka Streams可以使用经典的老实巴交维工具,像是Puppet, Chef, Salt来布署,把可以从命令行来启动。如果你年轻,时髦,你也可以把你的程序做成Dock镜像;或者你不是这样的人,那么你可以用WAR文件。
但是,对于寻找更加有灵活的管理方式的人,有很多框架的目标就是让程序更加灵活。这里列了一部分:
- Apache Mesos with a framework like Marathon
- Kubernetes
- YARN with something like Slider
- Swarm from Docker
- Various hosted container services such as ECS from Amazon
- Cloud Foundry
这个生态系统就和流处理生态一样专注。
的确,Mesos和Kubernets想要解决的问题是把进程分布到很多机器上,这也是当你布署一个Storm任务到Storm集群时,Storm尝试解决的问题。关键在于,这个问题最终被发现是挺难的,而这些通用的框架,至少是其中优秀的那些,会比其它的做得好得多-它们具有执行像在保持并行度的情况下重启、对主机的粘性(sticky host affinity)、真正的基于cgroup的隔离、用docker打包、花哨的UI等等功能。
你可以在这些框架里的任何一种里使用Kafka Streams,就像你会对其它程序做的一样,这是用来实现动态和有弹性的进程管理的一种简单的方式。比如,如果你有Mesos和Marathon,你可以使用Marathon UI直接启动你的Kafka Streams程序,然后动态地扩展它,而不会有服务中断, Meos会管理好进程,Kafka会管理和负载匀衡以及维护你的任务进程的状态。
使用一种这些的框架的开销是和使用Storm这样的框架的集群管理部分是一样的,但是优点是所有这些框架都是可选的(当然,Kafka Streams没有了它们也可以很好的工作)。
简化点2:Streams Meet Tables
Kafka Strems用于简化处理程序的另一个关键方式是把“表”和"流“这两个概念紧密地结合在一起。我们在之前的"turning the database inside out"中简化这个想法。那句话抓住了作为结果的系统是如何重铸程序和它的数据之彰的关系以及它是怎么应于数据变化,这样的要点。为了理想这些,我会回顾一下,解释我对于”table"和"stream"的定义,以及把二者结合在一起如何能够简化常见的异步程序。
传统的数据库都是关于在表格中存储状态的。当需要对事件流进行反应时,传统数据库做得并不好。什么是事件呢?事件只是一些已经发生了的事-可以是一个点击、一次出售、源自某个传感器的一个动态,或者抽象成任何这个世界上发生的事情。
像Storm一样的流处理程序,是从这个等式的另一端出发的。它们被设计用于处理事件流,但是基于流来产生状态却是后面才加进来的。
我认为异步程序的基本问题是把代表当前世界状态的tables与代表正在发生事件的event streams结合在一起。框架需要处理好如何表示它们,以及如何在它们之间进行转化。
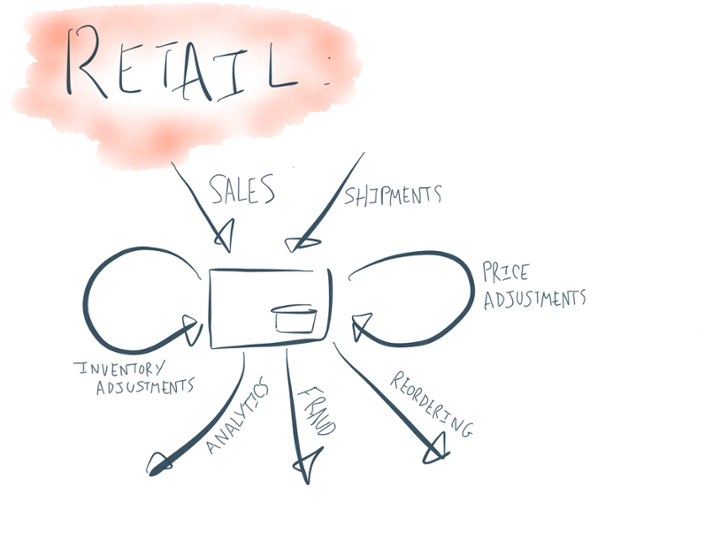
为什么说这些概念是相关的呢?我们举一个零售商的简单例子。对于零售商而言,核心的事件流是卖出商品、订购新商品以及接收订购的商品。“库存表”是一个基于当前的存货量,通过售出和接收流进行加减的“表”。对于零售商而言两个关键的流处理动作是当库存开始降低时订购商品,以及根据供需关系调整商品价格。
表和流是一体的双面
在我们开始研究流处理之前,让我们先试着想解表和流的关系。我想在这里最好引用一下Pat Helland关于数据库和日志的话:
事务日志记录了对于数据库的所有改变。高速的append操作是日志发生改变的唯一方式。从这个角度来看,数据库保存了日志里最新记录的缓存。事实记录于日志中。数据库是一部分日志的缓存。被缓存的部分刚好是每个记录的最新值,以及源自于日志的索引值。
这到底是在说什么呢?它的意义实际上位于表和流的关系的核心。
让我们以这个问题开始:什么是流呢?这很简单,流就是一系列的记录。Kafka把流建模成日志,也就是说,一个无尽的健/值对序列:
key1 => value1key2 => value2key1 => value3...
那么,什么是表呢?我认为我们都知道,表就是像这样的东西:
|
Key1 |
Value1 |
|
Key2 |
Value3 |
其中value可能是很多列,但是我们可以忽略其中的细节,简单地把它们认为是KV对(添加更多的列并不会改变将要讨论的东西)。
但是当我们的流随时间持续更新,新的记录出现了,这只是我们的表在某个特定时间的snapshot。表格是怎么变化的呢?它们是被更新的。一个表实际上并不是单一一个东西,而是像下面这样的一系列东西:
time = 0
| key1 | value1 |
time = 1
|
Key1 |
Value1 |
|
Key2 |
Value2 |
time = 2
|
Key1 |
Value3 |
|
Key2 |
Value2 |
但是这个序列有一些重复。如果你把没有改变的行去掉,只记录更新,那么就可以用一个有序的更新序列来表示这张表:
但是,这不就变成流了吗?这种类型的流通常补称为changelog, 因为它展示了更新序列,按照更新的顺序记录了每个记录的最新的值。
所以,表就是流之上的一个特殊的视图。这样说可能有些奇怪,但是我认为这种形式的表跟我们脑海中的长方形的表对于“表实际上是什么”是一样可以反映其本质的。或者,这样实际上更加自然,因为它抓住了“随时间改变”的概念(想一想:有什么数据真的不会改变呢?)。
换句话说,就像Pat Helland指出的那样,一张表就是一个流里的每个key的最新的值的缓存。
用数据库的术语来说:一个纯粹的流就是所有的更新都被解释成INSERT语句(因为没有记录会替换已有的记录)的表,而一张表就是一个所有的改变都被解释成UPDATE的流(因为所有使用同样的key的已存在的行都会被覆盖)。
这种双面性被构建进Kafka中已经有一段时间了,它被以compacted topics的形式展现。
表和流处理
好的,这就是流和表是什么。那么,这跟流处理有啥关系呢?因为,最终你会发现,流和表的关系正是流处理问题的核心。
我上面已经给了一个零售商的例子,在这个例子里“商品到货”和“商品售出”这两个流的结果就是一个存货表,而对存货表的更改也会触发像“订货”和“更改价格”这样的处理。
在这个例子中,存货表当然不只是在流处理框架中创造出来的东西,它们可能已经在一个数据库中了。那好,把一个由变化组成的流捕捉到一个表中被称为Change Capture, 数据库就做了这个事。Change capture数据流的格式就是我之前描述的changelog格式。这类型的change capture是你可以使用Kafka Connect轻松搞定的事情,Kafka Connect是一个用于data capture的框架,是Kafka 0.9版本新加的。

通过以这种方式构建表的概念,Kafka使得你从变化流(stream of changes)得到的表中推导出数值。换句话说,就是让你可以像处理点击流数据一样处理数据库的变化流。
你可以把这种基于数据库变化触发计算的功能看作类似于数据库的触发器和物化视图功能,但是这个功能却不仅限于一个数据库,也不仅限于PL/SQL,它可以在数据中心的级别执行,并且可以工作于任何数据源。
Join和Aggregate也是表
我们到了怎么样可以把一个把变成一个更新流(也是一个changelog),并且使用KafkaStreams基于它计算一些东西.但是表/流的双面性用相反的方式也是可行的.
假如你有一个用户的点击流,你想计算每个分户的点击总数.KafkaStreams可以让你计算这种聚合(aggregation),并且,你所计算出来的每个用户的占击数就是一张表.
在实现时,Kafka Streams把这种基于流计算出来的表存储在一个本地数据库中(默认是RocksDB,但是你可以plugin其它数据库).这个Job的输出就是这个表的hcnagelog. 这个changelog是用于高可用的计算的(译注:就是当一个计算任务失败,然后在别的地方重启时,可以从失败之前的位置继续,而不用整个重新计算),但是它也可以被其它的KafkaStreams进程消费和处理,也可以用KafkaConnect导到其它的系统里.
这种支持本地存储的架构已经在Apache Samza中出现,我这前从系统架构的角度写过一篇关于这个的文章.KafkaStreams与Apache Samza的关键的革新是表的概念不再是一个低层的基础设施,而是一个和stream一样的一等成员.Streams在Kafka Streams提供的programming DSL中用KStream类表示, 表是用KTable类表示.它们有一些共同的操作,也可以像表/流的双面性暗示的那样可以互相转换,但是,它们也有不同之处.(译注:接下来的几句比较难懂,如果觉得理解得不对,可以看原文).比如,对一个KTable执行取合操作时,Kafka Streams知道这个KTable底层是一个stream of updates,因此会基于这个事实进行处理.这样做是有必要的,是因对一个正在变化的表计算sum的语义跟对一个由不可变的更新组成的流计算sum的语义是完全不同的.与之相似的还有,join两个流(比如点击点和印象流)的语法和对一个表和一个流(比如点击流和账户表)进行join的语义是完全不同的.通过用DSL对这两个概念进行建模,这些细节自动就分清楚了.(译注:我觉得这段话的意思是就Kafka Streams会考虑到KTable底层实际上是一个流,所以会采用与计算普通表的aggregation和join不同的特殊的计算方式)
WIndows和Tables
窗口、时间和乱序的事件是流处理领域的另一个难搞的方面。但是,令人惊奇的是,可以证明的是一个简单的解决方案落到了表的概念上面。紧密关注流处理领域的人应该听说过"event time"这个概念,它被Google Dataflow团队的人非常有说服力地频繁地讨论。他们抓住的问题是:如果事件无序地达到,那么怎么做windowed操作呢?乱序的数据在大多数分布式场景下是无法避免的,因为我们的确无法保证在不同的数据中心或者不同的设备上生成的数据的顺序。
在零售商的例子中,一个这种windowed computing的例子就是在一个十分钟的时间窗口中计算每种商品的售出数量。怎么能知道什么时候这个窗口结束了呢?怎么知道在这个时间段的所有出售事件都已经到达而且被处理了呢?如果这些都不能确定的话,怎么能给出每种商口的售出总数的最终值呢?你无论在什么时候基于此时统计的数量做出答案,都可能会太早了,在后续可能会有更多的事件到达,使得你之前的答案是错误的。
Kafka Streams使得处理这个问题变得很简单:windowed aggregation的语义,例如count,就表示对于这个windows的“迄今为止"的count。随着新的数据的到达,它保持更新,下流的接收者可以自已决定什么时候完成统计。对,这个可以更新的数量的概念看起来莫名其秒的熟悉:它不是别的,就是一个表,被更新的windows就是key的一部分。自然而然的,下游操作知道这个流表示一个表,并且在这些更新到达时处理它们。
在数据库变化流之上进行计算和处理乱序事件的windowd aggregation,使用的是同样的机制,我认为这是很优雅的。这种表和流的关系并不是我们发明的,在旧的流处理的文章中,比如CQL中,已经展示了它的很多细节,但是这个理论却没有融合进大多数现实世界的系统——数据库处理表时、流处理系统处理流时,并且也没多数没有把两者都做为一等公民。
Tables + Embeddable Libary = Stateful Services
有一个基于我上边提出的一些特性的正在发展的功能可能不是那么明显。我讨论了Kafka Streams是如何让你透明地在RocksDB或其它本地数据结构中维护一个基于流推演出来的表的。因为这个处理的过程的状态都在物理上存在于你的程序中,这就开启了另一项令人兴奋的新的用途的可能性:使得你的程序可以直接查询这个状态。
我们当前还没暴露出来这个接口-我们现在还专注于使得流处理的API先稳事实上下来,但是,我觉得对于一些特定类型的数据敏感的程序,这是一个很吸引人的架构。
这意味着,你可构建,比如,一个嵌入了Kafka Streams的REST服务,它可以直接查询数据流通过流处理运算得到的本地的聚合结果。这种类型的有状态的服务的好处在这里讨论过。并不是在所有领域这么做都合适,你通常只是想要把结果输出到一个外部的数据库中。但是,假如你的服务的每个请求都需要访问很多数据,那么把这些数据放在本地内存或者一个很快的本地RocksDB实例中会非常有用。
简化点3: 简单即为美
我们的所有这些的最高目录是使得构建和操作流处理程序的过程变得更简单。我们的信念是流处理应该是一个构建应用程序的主流方式,公司所做的事情的很大一部分在异步领域,流处理正是用来干这个的。但是为了使这点成为现实,我们还需要使Kafka Streams在这方面更简单更可依赖。这种对于操作的简化的一部分就是摆脱对外部集群的依赖,但是它还简化了其它的地方。
如果对人们是怎么构建流处理程序进行观察的话,你会发现除了框架本身,流处理程序倾向于具有高度的架构复杂性。这是一个典型的流处理程序的架构图。
(图)

这里有如此多的会变化的部分:
- Kafka 自身
- 一个流处理框架,例如Storm或者Spark或者其它的,它们通常包含一系列的master进程和在每个结点上的守护进程。
- 你的实际的流处理job
- 一个辅助的数据库,用于查找和聚合
- 一个被应用程序查询的数据库,它接收来自于流处理任务的输出。
- 一个Hadoop集群(它本身就有一系列变化的部分)来重新处理数据
- 为你的用户或客户的请求提供服务的请求/响应式的程序
把这么一大堆东西弄下来不仅不是人们想追求的,而且通常也是不现实的。即使你已经有了这个架构的所有部分,把它个整合在一起,把它监控好,能够发挥它的所有作用,也是非常非常困难的。
Kafka Streams的一个最令人欣喜的事情就是它的核心概念很少,而且它们贯穿于整个系统中。
我们已经谈论过一些大的点:摆脱额外的流处理集群,把表格和有状态的处理完全整合进流处理本身。使用Kafka Streams,这个架构可以瘦身成这样:

但是使得流处理变得简单这个目标比这两点远得多。
因为它直接构建于Kafka的基础操作之上,Kafka Streams非常小。它的整个代码基础只有不到九千行。你喜欢的话,一下行就看完了。这意味着你会遇到的除了Kafka自己的producer和consumer以外的复杂性是很容易承担的。
这有很多小的含义:
- 输出和办理出都只是Kafka topics
- 数据模型自始至终都是Kafka的Keyd record数据模型
- 分区模型就是Kafka的分区模型(译注:这里就是指”数据分区”这件事的实现方式),Kafka的partitionor也可以用于streams。
- 用于管理分区、分配、存活状态的group membership机制也就是Kafka的group membership机制
- 表和其它的有状态的计算都是log compacted topics(译注:是指用的是compacted topics)。
- 对于Producer, consumer和流处理程序,metrics都是统一的,所以监控的时候只要抓取一种metrics就行了(译注:是指这三个部分用的是同样的metrics机制)。
- 你的程序的position被使用offset来维护,就像Kafka consumer一样。
- 用于做windowing操作的时间戳就是0.10加到Kafka的那个timestamp机制,它可以提供给你基于event-time的处理
简单来说一个kafka Strems程序在很多方面看起来就像其它的直接用Kafka producer或consumer写的程序一样,但是它写起来要简洁得多。
除了Kafka client暴露出来那些配置以外,额外的配置项非常少。
如果你改了代码,想要使用新的逻辑重新处理数据,你也不需要一个完全不同的系统。你只需要回退你程序的Kafka offsets,然后让它重新处理数据(你当然也可以在Hadoop端或者其它地方重新处理,但是关键是你可以选择不这么做).
尽管最初的样例架构是由一系列独立的组件组成,并且它们也只是部分地工作在一起,但是我们希望你将来会感觉到Kafka、Kafka Connect和Kafka Streams就是为了一起工作而设计的。
接下来呢?
就像其它的预览版一样,有一些功能我们还没有完成。下面是一些将会添加进来的功能。
可查询的状态
接下来会利用内置的表提供提供对程序状态的查询。
端到端的语义
当前的KafkaStreams继承了Kafka的"at least once"的消息传递语义。Kafka社区正在探索如何实现跨Kafka Connect, Kafka, KafkaStream和其它计算引擎的消息传递语义。
支持Java以外的语言

 浙公网安备 33010602011771号
浙公网安备 33010602011771号