


caffe windows学习:第一个测试程序
caffe windows编译成功后,就可以开始进行测试了。如果还没有编译成功的,请参考:caffe windows 学习第一步:编译和安装(vs2012+win 64)
一般第一个测试都是建议对手写字体minist进行识别。这个测试放在根目录下的 .\examples\mnist\ 文件夹内。
1、下载数据。程序本身不带测试数据,需要去下载,测试数据为leveldb格式。你可以直接双击运行“get_mnist_leveldb.bat” 这个脚本自动下载数据,但一般都不成功,可能里面的网址被墙了。你可以直接到此下载:http://pan.baidu.com/s/1hry1f4g
下载好后直接解压,得到两个文件夹(mnist-train-leveldb和mnist-test-leveldb),将这两个文件夹直接复制到 .\examples\mnist\ 目录下。
2、修改配置文件。该目录下prototxt扩展名的都是配置文件。我们只需要修改lenet_solver.prototxt,用vs2012打开(也可以用记事本打开,但格式混乱,看不清楚),定位到最后一行:solver_mode: GPU,将GPU改为CPU。 如果你有GPU,这一步就可以免了。
3、运行。直接双击文件“train_lenet.bat”就开始运行了,很简单吧。
但是原理是什么呢? 打开“train_lenet.bat”这个文件看看:
copy ..\\..\\bin\\MainCaller.exe ..\\..\\bin\\train_net.exe SET GLOG_logtostderr=1 "../../bin/train_net.exe" lenet_solver.prototxt pause
这个脚本程序其实很简单,只有四行:
第一行:将根目录下的bin文件夹里面的MainCaller.exe复制一份,并重命名为train_net.exe
第二行:设置glog日志。glog是google 出的一个C++轻量级日志库,介绍请看 glog
第三行:运行train_net.exe,并带一个参数lenet_solver.prototxt(即我们刚才修改的配置文件)
第四行:测试完后,暂停。
MainCaller.exe是整个程序的入口,由它来调用其它的测试。我们打开对应的MainCaller.cpp文件(examples目录下),发现只有这么一行代码:
#include "../../tools/train_net.cpp"
即是去调用执行train_net.cpp文件。
打开打tools下的train_net.cpp,熟悉的main函数就出来了

#include <cuda_runtime.h> #include <iostream> #include <cstring> #include "caffe/caffe.hpp" using namespace caffe; // NOLINT(build/namespaces) int main(int argc, char** argv) { ::google::InitGoogleLogging(argv[0]); //用第一个参数来初始化日志 ::google::SetLogDestination(0, "../tmp/"); //将日志放入/tmp/文件夹下 if (argc < 2 || argc > 3) { LOG(ERROR) << "Usage: train_net solver_proto_file [resume_point_file]"; return 1; } SolverParameter solver_param; //创建测试参数对象 ReadProtoFromTextFileOrDie(argv[1], &solver_param); //读取具体的参数配置 LOG(INFO) << "Starting Optimization"; //打印日志信息 SGDSolver<float> solver(solver_param); //开始优化 //根据调用时,是否带第三个参数,进行不同的测试 if (argc == 3) { LOG(INFO) << "Resuming from " << argv[2]; solver.Solve(argv[2]); } else { solver.Solve(); } LOG(INFO) << "Optimization Done."; //优化结束,打印日志信息 return 0; }
整个minist手写数字识别过程需要迭代10000次,识别精度会有99%以上。
如果你只是想看看caffe是否编译成功,不需要迭代那么多次,你可以修改lenet_solver.prototxt配置文件,定位到max_iter: 10000这一行,修改成你想要的迭代次数就行了。
我迭代1000次的结果如下:
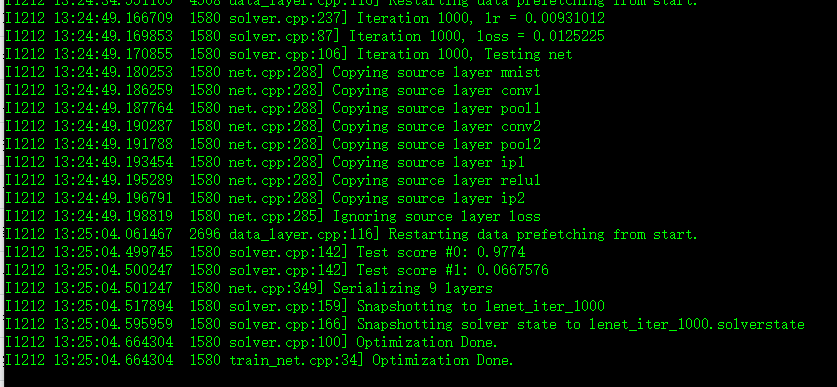
屏幕上显示的这些,都是打印的glog日志信息,从左至右大致是:日期 时间 执行文件] 执行信息

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步