

mongodb副本集架构搭建
高可用性通常描述一个系统经过专门的设计,从而减少停工时间.保存其服务的高度连续可用性,MongoDB提供的主从复制机制保证了多个数据库的数据同步,这对实现数据库的容灾、备份、恢复、负载均衡都是有极大的帮助.
主从集群
主从复制的优点:
从服务器可以执行查询工作,降低主服务器访问压力
在从服务器执行备份,避免备份期间锁定主服务器的数据
当主服务器出现故障时,可以快速切换到从服务器,减少当机时间.
MongoDB支持在多个机器中通过异步复制到底故障转移和实现冗余,多台机器中同一时刻只有一台是用于写操作,这为mongoDB提供了数据一致性的保障.担当Primary角色的机器能把读操作分发给slave机器.
MongoDB的主从集群分为两种
Master-Slave 复制(主从复制)
Replica Sets 复制(副本集)
主服务器支持增删该,从服务器主要支持读.
Master-Slave(主从复制)
只需要在某一个服务启动时加上-master参数,以指明此服务器的角色是primary,而另一个服务加上-slave与-source参数,以指明此服务器的角色是slave. 即可实现同步,
MongoDB的最新版本已经不推荐使用这种方法了.
Replica Sets 复制(副本集)
MongoDB在1.6版本开发了replica set,主要增加了故障自动切换和自动修复成员节点.各个DB之间数据完全一致,最为显著的区别在于,副本集没有固定的主节点,它是整个集群选举得出的一个主节点.当其不工作时变更其它节点.
部署Replica Sets【windows环境模拟】

创建数据文件存储路径
D:\program files\mongo\data\data1\
D:\program files\mongo\data\data2\
创建日志文件路径
D:\program files\mongo\logs\dblog1.log
D:\program files\mongo\logs\dblog2.log
创建主从key文件用于标识集群的私钥的完整路径.如果各个实例的key file内容不一致,程序将不能正常用.
D:\program files\mongo\key\key1.txt
D:\program files\mongo\key\key2.txt
启动2个实例
mongod --replSet rs1 --keyFile=../key/key1.txt --port 8888 --dbpath=../data/data1/ --logpath=../logs/dblog1.log
mongod --replSet rs1 --keyFile=../key/key2.txt --port 8889 --dbpath=../data/data2/ --logpath=../logs/dblog2.log
参数说明
--replSet rs1副本集的名字
如图

另起一个窗口

注意:服务不能启动时,可以去日志文件中查看出现什么错.
比如:Sat Jan 19 11:08:50 key file ../key/key1.txt has length 3, must be between 6 and 1024 chars
重新启动一个窗口,登录其中一台
mongo --port 8888
config_rs1 = {
_id : "rs1",
members : [ { _id:0, host:"localhost:8888", priority:1 }, { _id:1, host:"localhost:8889" } ]
}
初始化配置
rs.initiate(config_rs1);
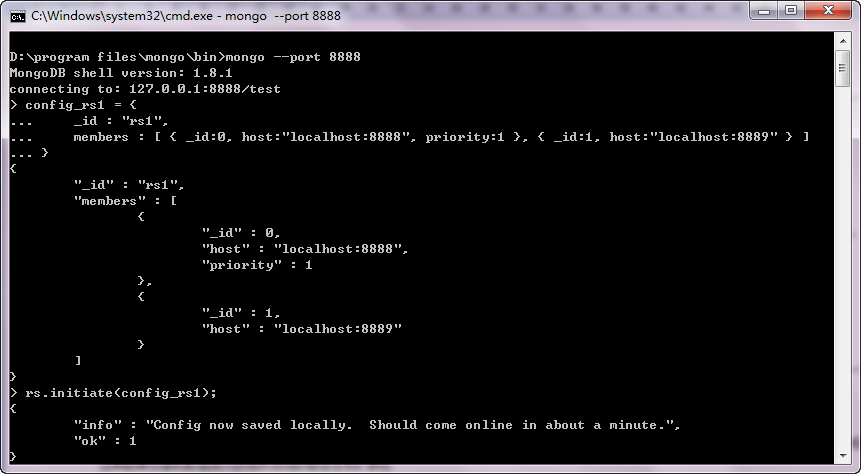
查看副本集状态
rs.status();

可以看到当前8888的为主服务器
另起窗口登录从服务器
使用rs.isMaster()查看Replica Sets状态.

读写分离
大部分web应用都用数据库作为数据持久化工具,在并发访问频繁且负载压力较大的情况下,也能成为系统性能的”瓶颈”,即使使用本地缓存等方式解决频繁访问数据库的问题,但仍会有大量的并发请求访问动态数据,”读写分离”是一种被广泛采用的方案
“读写分离”,机制首先将那些使用CPU以及内存消耗严重的操作分离到一台或几台性能很高的机器上,而将频繁读取的操作放到几台配置较低的机器上,然后,通过数据同步机制,实现多个数据库之间快速高效地同步数据,从而实现将”读写请求”按实际负载情况进行均衡分布.
注意:在从服务器进行查询操作时报错”not master and slaveok=”false” ”说明从库不能执行查询的操作,可以让从库可以读,分担主库的压力命令如下:
db.getMongo().setSlaveOk();

或者使用rs.slaveOk()

主从操作日志
数据复制的目的是使数据得到最大的可用性,避免单点故障的发生,MongoDB支持在服务器之间进行数据的异步复制,以满足数据的最终一致性,但是同一时刻只有一台服务器是可以写的,MongoDB的主从复制是一个异步的复制过程,数据从一个primary实例复制到另一个slave,整个复制过程实际上是slave端从primary端获取日志,然后在自己身上完全顺序执行日志中所有记录的各种操作.
MongoDB的Replica Sets架构是通过一个primary数据库中的日志表来存储写操作的,这个日志表叫做oplog.rs.oplog.rs是一个固定长度的capped collection,存在于local数据库中,用于记录Replica Sets操作日志.
通过 db.oplog.rs.find();命令查看复制集产生的日志信息.
rs1:PRIMARY> db.oplog.rs.find();
主从切换
有时候由于种种原因,需要调整复制集中的主从角色.步骤如下
1.除了现在的主实例,和目标实例以外,其它的实例全部设为”冰冻”状态(freeze状态,即非主状态)
Eg.rs.freeze(30),将当前实例”冰冻”,其中的30单位是秒,说明30秒内这个实例不会参与primary的内部选举工作,
2.将当前主库的实例降级(stepDown)
Eg.rs.stepDown(30),将当前主库实例”降级”30秒.
3.上面的操作结束后,用rs.status查看复制集的状态.
过程很简单,其它的不参与选举,自己降级,目标机肯定优先级就提升了,成为了主库.
将上面的主从集实现主从切换


主从配置信息
在local库中不仅有主从日志oplog.rs,还有一个集合用于记录主从配置信息system.replset,通过执行”db.system.replset.find()”命令查看复制集的配置信息

为复制集中添加节点
MongoDB提供了2种增加节点的方案.
1.通过oplog增加节点
这种添加方式,使数据库的同步完全依赖于oplog,即oplog中有多少操作日志,这些操作日志就完全在新添加的节点中执行一遍.已完成数据同步.
对实例中的2个节点中添加一个节点
创建数据存放文件路径D:\program files\mongo\data\data3
创建key文件输出路径D:\program files\mongo\key/key3.txt [注意key文件中的密钥必须跟之前节点中的一致]
创建日志存放文件路径D:\program files\mongo\logs\dblog3.log
D:\program files\mongo\bin>mongod --replSet rs1 --keyFile=../key/key3.txt --port 9999 --dbpath=../data/data3/ --logpath=../logs/dblog3.log

然后添加此新节点到现有的replica collection中.
rs1:PRIMARY> rs.add("localhost:9999");
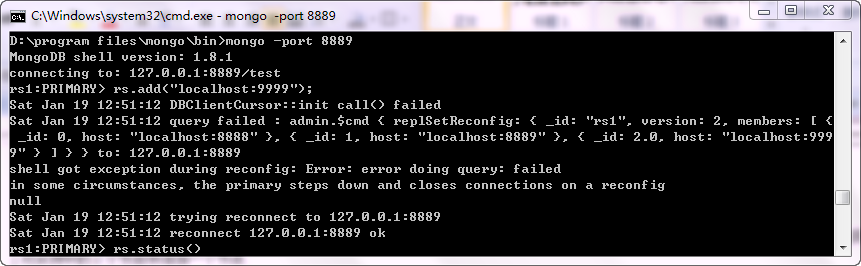
可以使用rs.status()查看复制集状态,新增的节点已经添加成功
登录新增节点,查寻数据,如下说明数据同步成功

2.通过数据库快照和oplog增加节点
通过oplog直接执行增加节点操作简单且无需人工干预,但oplog是capped collection,采用循环的方式执行日志处理,所以采用oplog的方式执行增加节点,有可能导致数据的不一致,因为日志中存储的信息可能已经被刷新过,为了解决这个问题,可以通过数据库快照和oplog结合的方式来增加节点.
这种方式的操作流程是,先取某一个复制集成员的物理文件作为初始化数据,剩余的部分用oplog日志来补充,最终达到数据一致性.
减少节点
减少节点很简单,只需要执行”rs.remove(“ip:port”)”即可.
例如,将实例中的9999节点移除.

可以通过rs.status()查看移除后的状态members成员中已经没有9999节点了.
故障转移
副本集比传统的Master-Slave有改进的地方就是它可以进行故障的自动转移,如果我们停掉复制集中的一个成员,那么剩余成员会再自动选举一个成员,作为主库.
这种故障处理机制,能极大的提供系统的稳定性和扩展性.
转载请注明出处:[http://www.cnblogs.com/dennisit/archive/2013/01/28/2880166.html]

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步