[01] 网络爬虫的基本原理
1、什么是网络爬虫
爬虫是“模拟用户在浏览器或某个应用上的操作,把操作的过程实现自动化程序”,那什么是网络爬虫呢?即模拟浏览器行为,通过指定url,直接返回给用户所需要的数据,而不需要人为操纵浏览器获取。
我们使用浏览器访问网页大概发生了什么?
- 查找域名对应的IP地址
- 向IP对应的服务器发送请求
- 服务器响应请求,发回网页内容
- 浏览器解析网页内容
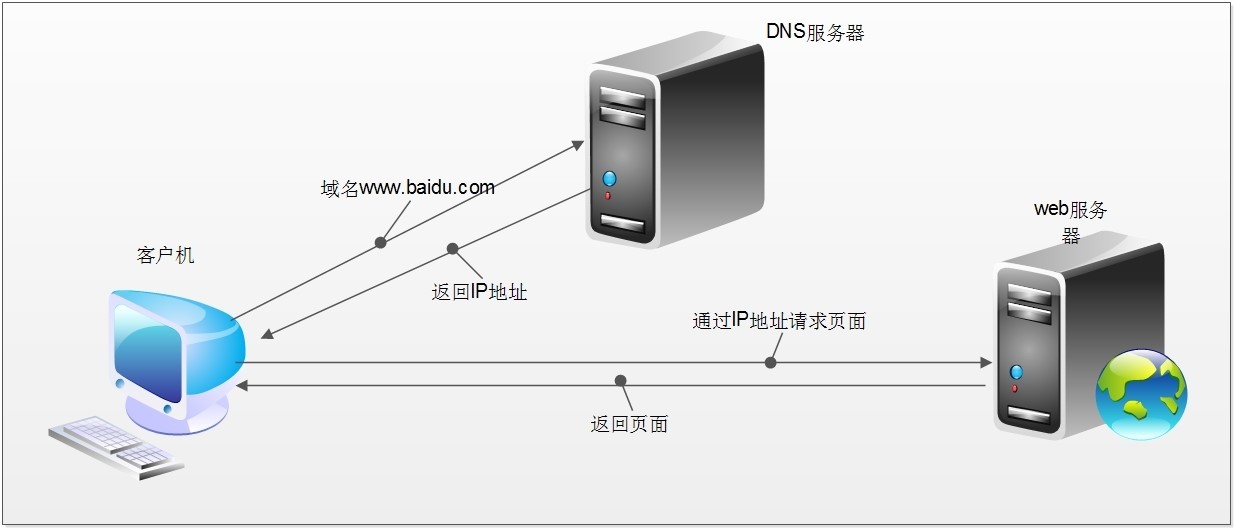
网络爬虫,就是要模拟上述行为。
2、最简单的爬虫:你好百度
既然知道了原理,那么我们试着来把百度的网页内容抓取下来,无非就是:
- 模拟url连接
- 获取响应的输入流
- 把输入流的内容输出到本地
public class Test {
public static void main(String[] args) {
try {
URL url = new URL("http://www.baidu.com");
URLConnection connection = url.openConnection();
//建立连接
connection.connect();
//获取输入流
InputStream in = connection.getInputStream();
//输出内容
OutputStream out = new FileOutputStream(new File("C:/Users/Dulk/Desktop/baidu.txt"));
byte[] temp = new byte[1024];
int size = -1;
while ((size = in.read(temp)) != -1) {
out.write(temp, 0, size);
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}1
public class Test { 2
public static void main(String[] args) {3
try {4
URL url = new URL("http://www.baidu.com");5
URLConnection connection = url.openConnection();6
//建立连接7
connection.connect();8
//获取输入流9
InputStream in = connection.getInputStream();10
//输出内容11
OutputStream out = new FileOutputStream(new File("C:/Users/Dulk/Desktop/baidu.txt"));12
byte[] temp = new byte[1024];13
int size = -1;14
while ((size = in.read(temp)) != -1) {15
out.write(temp, 0, size);16
}17
} catch (MalformedURLException e) {18
e.printStackTrace();19
} catch (IOException e) {20
e.printStackTrace();21
}22
}23
}瞧瞧本地多了什么?一个baidu.txt文件,打开看看:
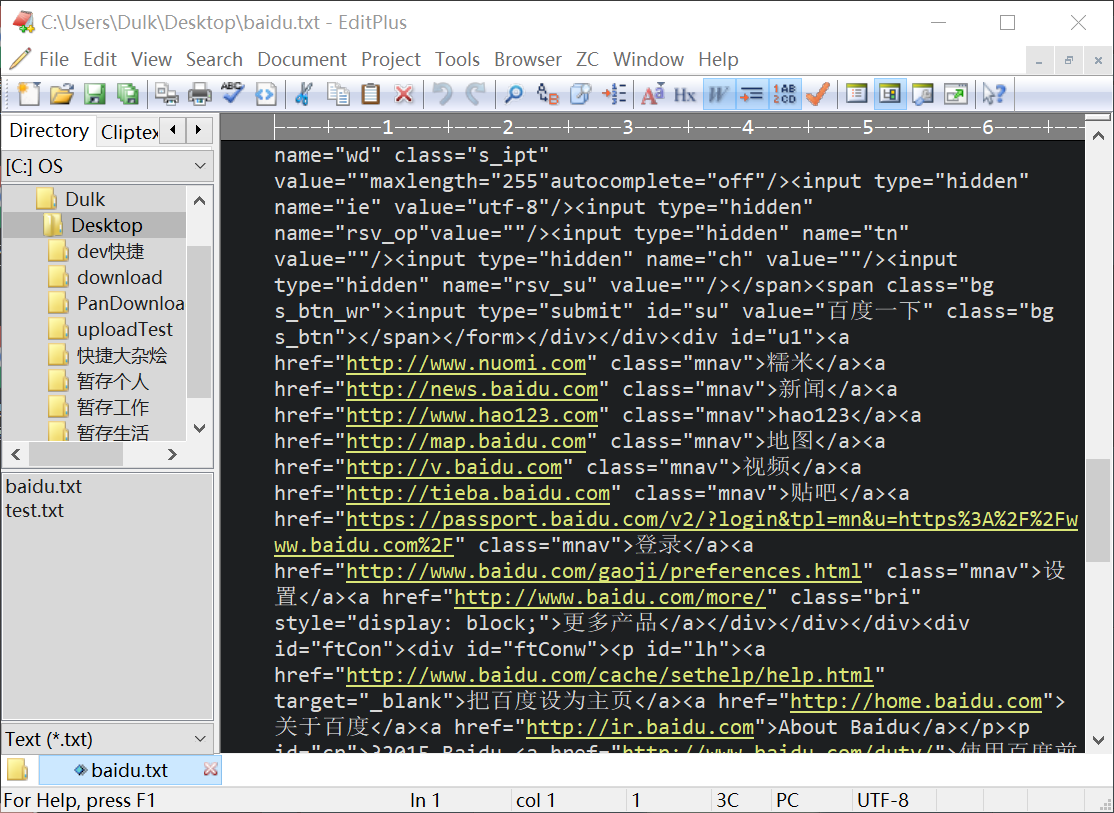
再把后缀txt改为html试试:

3、再听我叨叨
上面的例子写了一个最简单不过的爬虫,爬取了百度首页的网页内容。爬虫有什么作用?举个简单的例子,你看到某个帖子里有好多好多美女图片,但是帖子有上百页,手动保存图片估计得累得半死,有爬虫就so easy。再者,你想租个房子,要离地铁近,要套一,价格要便宜,网上一家一家找?有爬虫,去几大网站上把租房信息爬下来,再写个算法进行筛选,找到心仪的租房so easy。当然,爬虫生态较好的还是python了,爬下来的内容也是做大数据分析不可或缺的。
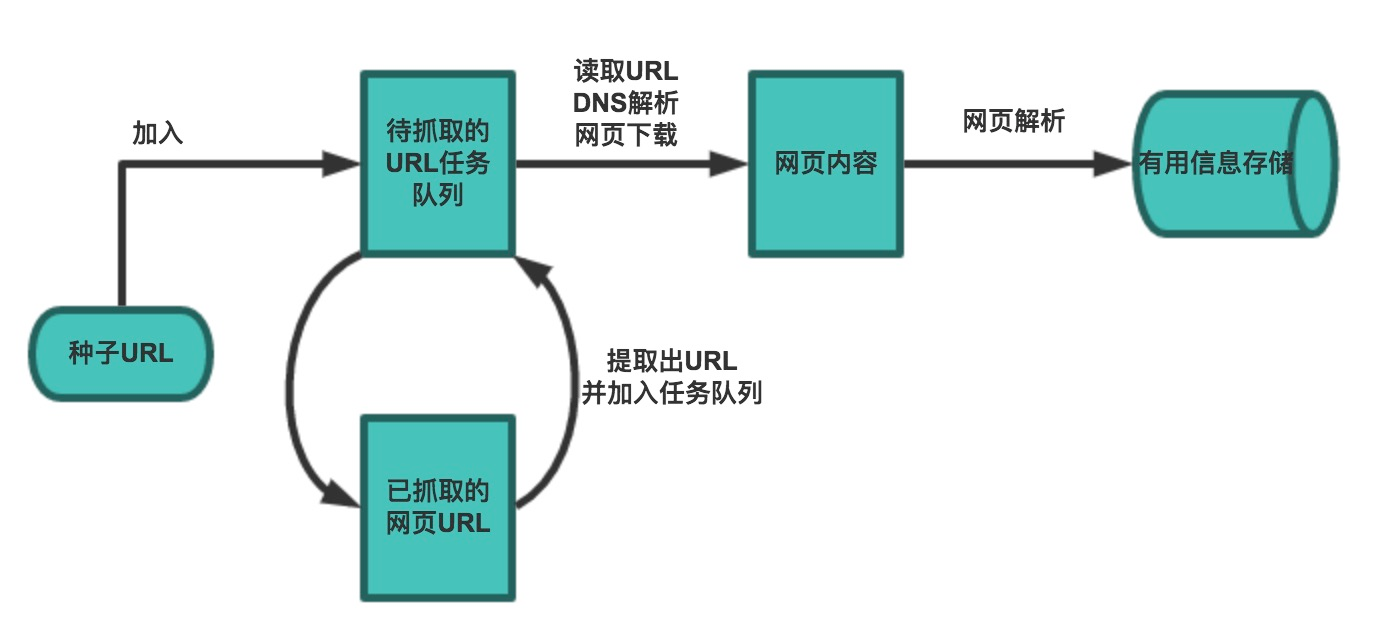
3.1 爬虫的基本流程
在复杂的需求下,就不会像上例那么简单的爬虫了,它的工作流程有了一些变化,主要是因为URL需要变化:
- 首先选取一部分精心挑选的种子URL
- 将种子URL加入任务队列
- 从队列取出URL,解析DNS得到IP,并将对应的网页下载下来,并将这些URL放进已抓取URL队列
- 分析已抓取URL队列中的URL,分析其中的其他URL,并放入待抓取队列,从而循环
- 解析下载下来的网页,将需要的数据解析出来
- 数据持久化,保存至数据库中
3.2 爬虫的抓取策略
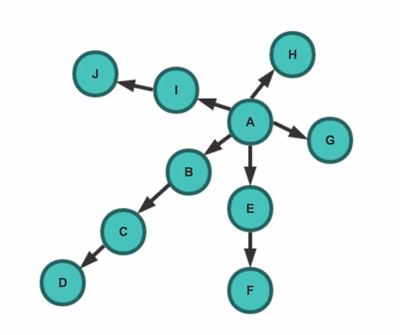
这里只列举两种常见的抓取策略:
深度优先策略:
- 指爬虫从某个URL开始,一个链接接着一个链接爬取下去,直到处理完某个链接所在的所有线路,才切换到其他线路
- 抓取顺序(如上图例):A -> B -> C -> D -> E -> F -> G -> H -> I -> J
广度优先策略:
- 指将新下载网页中发现的链接,直接插入到待抓取队列的末尾
- 即先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取该网页链接中所有网页
- 抓取顺序(如上图例):A -> B -> E -> G -> H -> I -> C -> F -> J -> D
3.3 其他还没有提到问题
还有其他很多要点这里没有详细进行阐述,比如:
- 如果网页需要登陆,设置Cookie的问题
- 如何通过抓包分析请求
- 拥有反爬虫机制的网站如何进行伪装
- AJAX技术的网页如何处理
- 高频请求后是否触发网站的验证码验证
- ...
真是学无止境啊!

