

http://www.uml.org.cn/zjjs/201512011.asp
“11.11”是一年一度的电商盛宴,为了准备这个一年内最大规模的促销,1号店各条战线都在紧张有序地忙碌着。1号店搜索团队经过几年的大促历练,不断推动架构演进,积累了越来越多的经验。
11.11的主要特点是流量大和突发性高,这就带来了两个核心的需求:
可扩展 如何抗住这样的流量,针对这个需求,1号店搜索团队构建了分布式搜索引擎,支持横向扩展;并且针对业务特点做了Routing优化,让搜索的效率更高。
快速响应 流量越大,单位时间内的流量价值就越大,出现问题的损失也就越大,如何做到快速响应变得非常关键。针对这个需求,搜索系统支持自动部署和快速扩容以应对突发流量,索引数据从导入、处理到上线服务会经过层层验证,同时还有监控体系及时发现线上的问题。
下面我们针对这些设计要点分别展开。
分布式搜索引擎1号店分布式搜索引擎是Lucene/Solr核心的,结合SOA框架Hedwig构建了一层分布式框架,支持搜索请求的分发和合并,并且构建了搜索管理后台,支持多索引管理、集群管理、全量索引切换和实时索引更新。
选择自己构建分布式方案,而不是采用开源的SolrCloud或ElasticSearch,主要是基于以下几点考虑:
(1) ElasticSearch/SolrCloud都适合于把搜索引擎作为一个黑盒系统来使用,而1号店搜索业务的展现形式多样性很高,搜索条件有的会很复杂,有的需要通过自定义插件来实现,性能调优时也需要对引擎内部的执行细节进行监控。
(2) 将ElasticSearch/SolrCloud与公司内部的发布系统、监控系统和SOA体系结合起来,也是一项比较耗时的工作。
(3) 相对于整体使用,我们更倾向于把Lucene/Solr开源家族中的各个组件按需引入,一方面降低引入复杂工程的可维护性风险,另一方面逐渐深入理解这些组件,可以在必要时替换为定制化的组件。
分布式搜索是为了解决数据增长过程中索引变大和操作时间变长的问题,它将原来的单个索引文件划分成n个切片(shards),让每个shard都足够小,从而保证索引可以在多台服务器上部署,而且搜索操作可以在较短时间内返回。
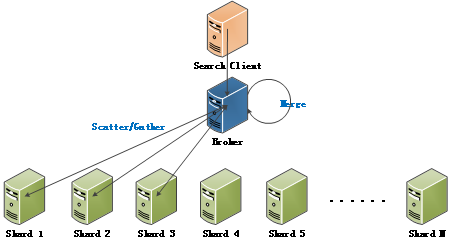
如上图所示,分布式搜索中有两个主要组件:Shard Searcher和Broker,其中Shard Searcher与单机搜索引擎类似,基于Lucene/Solr完成基本的搜索任务。Broker负责把针对整个索引的搜索请求转化为针对单个Shard的搜索请求,它把Shard搜索请求分发给各个ShardSearcher,并且把各个Shard的结果进行合并,生成最终的结果。
分布式搜索中,一次搜索所需的资源与它要访问的Shard数和每个Shard要返回的结果数有非常强的关联关系,在Shard数特别多或结果数特别多时可能会碰到一些的内存、CPU资源使用的问题。针对结果数特别多的情况,可以按照业务场景优化,比如如果对排序无要求,就可以每次指定一个Shard进行搜索,搜完这个Shard再换下一个,这样就限制了每次搜索的Shard数,另一方面也可以考虑使用DeepPaging等技术,减少每次Shard搜索的成本。我们下一小节也会介绍1号店主站搜索是如何减少每次搜索Shard数的。
另外,上图中的Broker和Shard Searcher仅仅是概念上的划分,实际部署时有几种选择:
A) 每个节点上都有Broker和部分Shard的Shard Searcher。
B) Broker单独部署成一个集群,与Shard Searcher隔离。
C) Broker作为客户端的一部分,和搜索应用一起部署。
我们开始使用的是A方式,后来主站搜索转为C方式,主要是考虑到可以节省一次网络调用(以及请求和结果的序列化开销),另外Broker在客户端也可以更多地使用应用逻辑相关的数据进行更高效的Routing。
高效Routing通过前面的讲述,我们不难看出,使用分布式搜索引擎,面临的核心问题就是如何选择高效的Sharding策略和Routing方案。为了设计Routing方案,我们需要深入理解业务场景。
1号店有很多的类目,每个类目的业务模式也不尽相同。以图书和快消品为例,图书是一种典型的长尾商品,它需要索引大量的SKU(Stock Keeping Unit,可以理解为一个独立的商品),但每个SKU的访问量和销量都不高;快消品是另外一个极端,总体SKU数量不高,但是访问量和效率都很高。这就造成了一个不平衡的局面,图书的SKU数目占比达到了50%以上,流量却小于10%,我们就首先排除了按Shard数目取模(id mod N)这种平衡划分的策略。
1号店搜索有两个主要入口,一个是搜索框的搜词,另外是类目导航。在这两个入口中,类目的点击肯定是访问到一个特定的一级类目下,搜词时用户其实也只会关注相关的几个类目。基于这种访问模式,我们就采用了按照类目来切分Shard的策略。基本操作为:
(1) 按照一级类目切分Shard。
(2) 如果该Shard过大,则按照二级类目继续切分。
(3) 经过前两步之后,如果切分后的Shard过小,则按照相关性进行Shard合并。
经过这样一番尝试,Sharding策略就确定下来,切分之后的Shard索引大小一般为200~500MB,Shard上单次搜索可以控制在10ms以下。
接下来说到Routing,我们还是分搜词和类目导航两种场景,对于类目导航,原理上非常简单,按照类目ID来查找Sharding策略,就可以确定需要访问的Shard,虽然现实中还需要考虑扩展类目等特殊场景,但是也不难做出一个简单的Routing策略。再加上类目数是有限的,Routing规则在Broker本地内存就可以缓存起来。
搜词场景就复杂很多,仅凭词本身很难判断它属于哪个Shard。我们首先按照词的热度分为两类,采取不同的Routing策略。对于热词,搜词流量同样符合80-20规则,20%的热词占比80%的搜索流量,对于热词,我们可以在建完索引之后,就跑一遍热词搜索,记录那些Shard有结果,离线构建出热词Routing表。切换索引时,Routing表也一起加载进去。对于非热词,则采用首次搜索去访问所有Shard,根据结果记录Routing表,这个词在下次搜索时,就有了缓存可用。
基本的Routing策略上线之后,通过监控每个Shard的访问量,我们又发现了新的问题,图书类目的访问量比它应有的流量要高出不少。仔细分析之后发现,由于图书类目的特殊性,很多词都可以在图书中找到结果,然而这些结果一般都不是用户想要的,实际上也不会排到前几页,并没有展示的机会。于是我们又增加了一种360-Routing策略,跟进搜索前五页的结果(每页72个商品,共360个商品)计算Routing,下次搜索时优先是用这份Routing规则。由于前五页的流量占比在80%以上,这就进一步减少了单次搜索需要访问的Shard数。
使用了以上这些Routing规则,1号店主站搜索每次搜索平均只需要访问1/3的索引数据,这就节约了2/3的资源,提高了搜索效率。
自动部署与快速扩容文章一开始我们提到11.11要求搜索系统支持快速扩容,为了讲清楚这个功能,我们首先要从索引部署讲起。
按照类目进行Sharding和Routing的方式,在带来高效的同时,也带来了管理上的成本。按照类目切分,必然会导致各个Shard的大小不平均,而对应的Routing方案,必然会带来各个Shard的访问量不平均。这两个维度不平均就要求更加复杂的索引部署方案,主要的原则为:
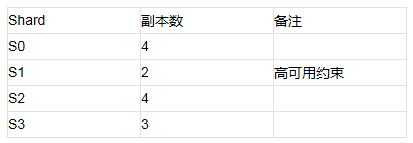
(1) 首先根据流量比例和高可用的需求,确定每个Shard的副本数。
(2) 然后按照单个节点不能放置同一Shard的多个副本,节点上的承担的流量总和与节点的服务能力成正比。
(3) 每个节点上的索引总大小尽量也保持差异最小。
按照流量比例,副本数计算如下:
部署之后的效果如下图所示。
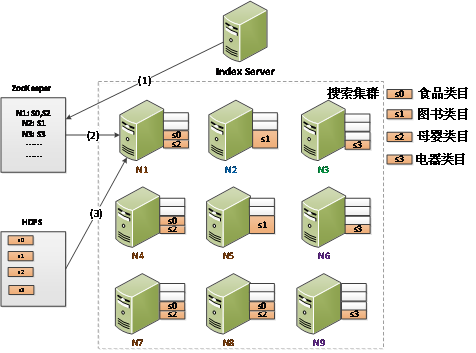
Shard数增多之后,人工计算部署方案就显得较为复杂,于是我们就把部署方案生成做成了自动化,一个基本的Packing算法就可以完成这个工作。除了初始部署之外,自动部署工具还可以支持节点增加、减少和更换。
在11.11的场景下,这个自动化部署工具也可以支持快速扩容,基本过程为:
(1) Index Server(部署工具界面)计算出扩容之后的部署方案,写入到ZooKeeper。这里的算法与初始部署有些不同,它需要保证现有服务器的Shard尽量不变。
(2) 每个Shard Searcher服务器都会监听ZooKeeper上的部署方案,方案改变之后,Shard Searcher会获取新的方案与本地方案对比,进行增减操作。
(3) Shard Searcher从HDFS上获取索引数据,与最近的实时更新数据合并之后,启动索引提供服务。
有了自动扩容工具,11.11容量规划确定之后,新的服务器就可以很快部署上线,也减少了人工操作可能引入的失误等问题。大促期间如果需要紧急扩容,也可以在几分钟内提高整个系统的服务能力。
实时监控体系
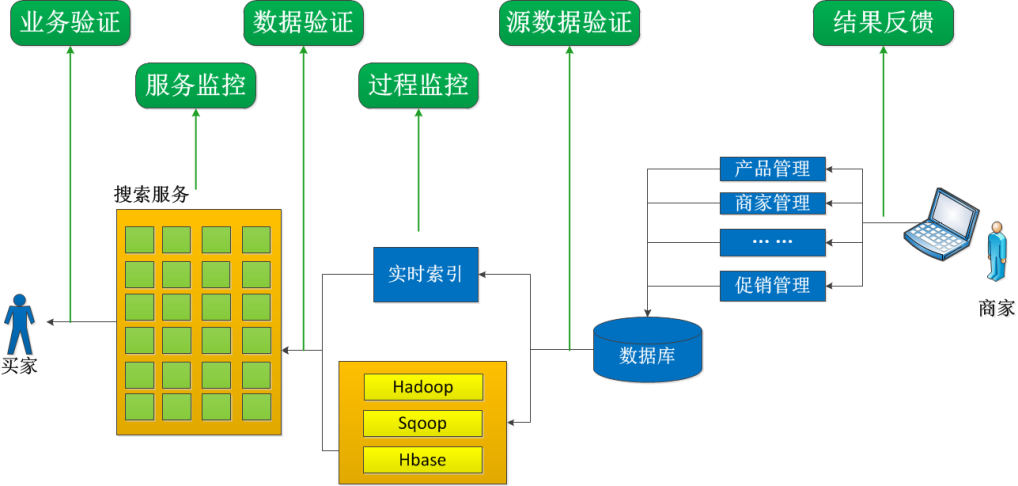
11.11大促期间每一分钟都影响很大,我们需要实时了解线上数据和服务情况,确保系统处于一致和可用的状态,为此,我们构建了搜索的监控体系。
在索引数据方面,从源头开始对索引数据准备的各个环节进行验证,包括数据的条数、处理过程中的异常、最后生成的索引在常见搜索中的执行结果差异等,层层预防,防止有问题的索引数据被用到线上。
在搜索服务方面,监控系统会定时执行常见的搜索,对比排序结果,结果差异较大时及时告警。同时大促期间会有一些商品很快卖完,这些商品继续显示在搜索结果中也没有价值,搜索监控也会及时发现这些商品,触发索引更新,把商品排到后面。
结语每年11.11对系统都是一次大阅兵,通过构建分布式搜索引擎,我们实现了基础架构的可扩展性,结合业务场景设计的Routing规则,保证了 搜索的高效执行,自动化工具支持大促必需的自动扩容,配合成体系的验证和监控,我们有信心应对更高流量的冲击,保障大促平稳度过。

微信公众号: 架构师日常笔记 欢迎关注!
