


[大牛翻译系列]Hadoop(10)MapReduce 性能调优:诊断reduce性能瓶颈
6.2.3 Reduce的性能问题
Reduce的性能问题有和map类似的方面,也有和map不同的方面。图6.13是reduce任务的具体的执行各阶段,标识了可能影响性能的区域。
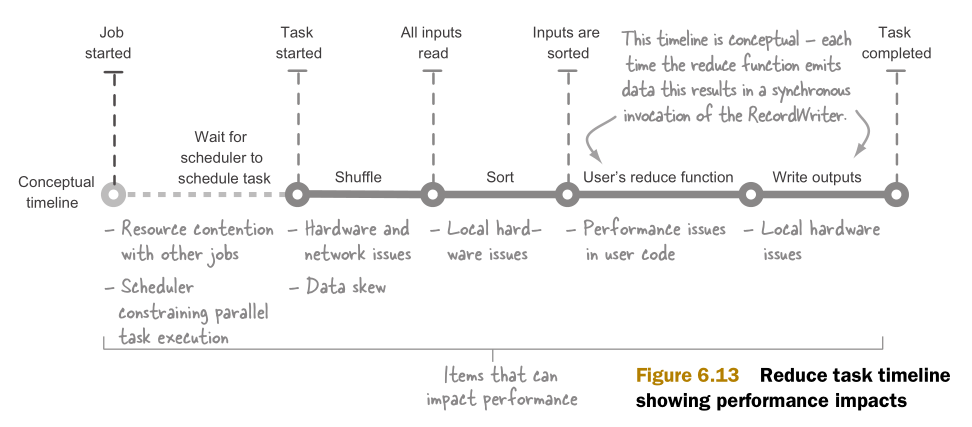
这一章将介绍影响reduce任务性能的常见问题。
技术33 Reduce实例不足或过多
尽管map段的并行化程度在大部分情况下是自动设置的,但是在reduce端,reduce实例的数量是完全自定义的。如果reduce实例不足或过多,集群的性能就很难得到充分发挥。
问题
需要确定reduce实例的数量是否是作业运行缓慢的原因。
方案
用JobTracker UI来诊断作业中运行的reduce实例的数量。如图6.14所示。

讨论
Reduce实例的数量最好能小于集群中设置的reduce的槽(slot)的数量。在JobTracker UI中也可以找到reduce槽的数量。如图6.15所示。

小结
有的时候,为了减小外部资源(如数据库)的压力,不得不只使用很少的reduce实例。
有的时候,为了对所有数据进行排序,有的人会采用单独的reduce实例。实际上,可以用总排序和TotalOrderPartitioner来避免这个做法。(具体参考第4章。)
在对HDFS进行写操作的时候,应该在留出部分富余量的前提下,尽可能多用集群中的reduce槽。留出的那一部分,用于防备有部分节点宕机。如果reduce实例太少的话,显然是浪费集群性能。如果reduce实例比reduce槽还多,就会分两批执行,导致作业执行时间变长。
以上讨论仅仅针对只运行一个作业的情况。如果多个作业同时运行,就要具体情况,具体分析了。不过reduce的槽的数量仍然会是判断标准。
技术34 诊断reduce段的数据倾斜的问题
在reduce端,数据倾斜指的是少数键的记录的数量大得不成比例,比其它大部分键的记录数量要多得多。
问题
需要诊断是否是因为数据倾斜导致作业运行缓慢。
方案
使用JobTracker UI来比较作业中所有reduce实例的字节吞吐量,确定是否存在部分reduce实例得到了过大的数据量。在这个技术中还要用到map和reduce任务的运行时的可视化。
讨论
如果存在数据倾斜,JobTracker UI中将会观察到,一小部分reduce任务的运行时间会不成比例地比其他大部分任务长得多。如图6.16所示。这和map端有数据倾斜时很类似。

这种方法能很快地诊断潜在的数据倾斜问题。本书也提供了一个简单的工具来生成任务级别的统计信息,包括输入/输入记录数,输入/输出字节数。输出的内容有两部分,分别是map和reduce。每个部分又分了三个子部分。所有的结果按照执行时间,输入记录数,输入字节数进行排序。命令如下:
$ bin/run.sh com.manning.hip.ch6.DataSkewMetrics --hdfsdir output
本书还有一个工具,可以生成tab分隔的任务执行时间(或输入字节数)。可以基于这些数据生成图表,就可以直接目测问题了。命令如下:
$ bin/run.sh com.manning.hip.ch6.DataSkewGnuplot --hdfsdir output
图6.17是生成的图表。在这个例子中,很容易发现部分map任务的时间特别长。Reduce任务似乎就比较均匀。

小结
在确认了reduce实例中的数据倾斜之后,下一步就是减轻它的影响。技术50和51尝试如何确定数据倾斜的成因。(技术50和51在6.4.4。)
技术35 确定reduce任务是否存在整体吞吐量过低
有很多原因会导致reduce任务运行缓慢,代码,硬件等。要确定根本原因是比较有挑战性的。
问题
需要诊断是否是吞吐量过低导致作业运行缓慢。
方案
使用JobTracker UI或作业历史信息元数据来计算renduce任务的吞吐量。
讨论
通过JobTracker获得任务的执行时间,就可以计算出单个任务的吞吐量了。图6.18说明了如何计算reduce热舞的吞吐量。

本书还提供了工具来通过作业历史文件来计算吞吐量的统计信息。如图6.19所示。

小结
本书的计算工具提供了四个吞吐量指标。通过它们可以找到reduce任务中是否存在某个环节过于缓慢。下个技术将介绍洗牌(shuffle)和排序阶段。
由于reduce阶段需要从磁盘上读取map的输出,处理,并将数据输出到某个接收器,那么有以下潜在因素会影响reduce的吞吐量:
- 本地磁盘事故。MapReduce需要从磁盘上读取数据作为reduce的输入。
- 效率底下的reduce处理代码
- 网络问题,在作业的输出是HDFS的时候。
- 延迟或吞吐量问题,在数据接收器不是HDFS的时候。
不同的技术将被运用到处理上述除最后一个外的其它各个因素,以便确定reduce低吞吐量的根本原因。
技术36 缓慢的洗牌(shuffle)和排序
洗牌阶段要从任务跟踪器(TaskTracker)来获取map的输出数据,并在后台合并它们。排序阶段要把文件进行合并,并减少文件的数量。
问题
需要确定作业是否因为洗牌和排序阶段而运行缓慢。
方案
从作业历史元数据中提取洗牌和排序阶段执行时间的统计信息。
讨论
图6.20使用本书提供的工具代码来检查作业的洗牌和排序时间的统计信息,并查看其中的潜在改进空间。
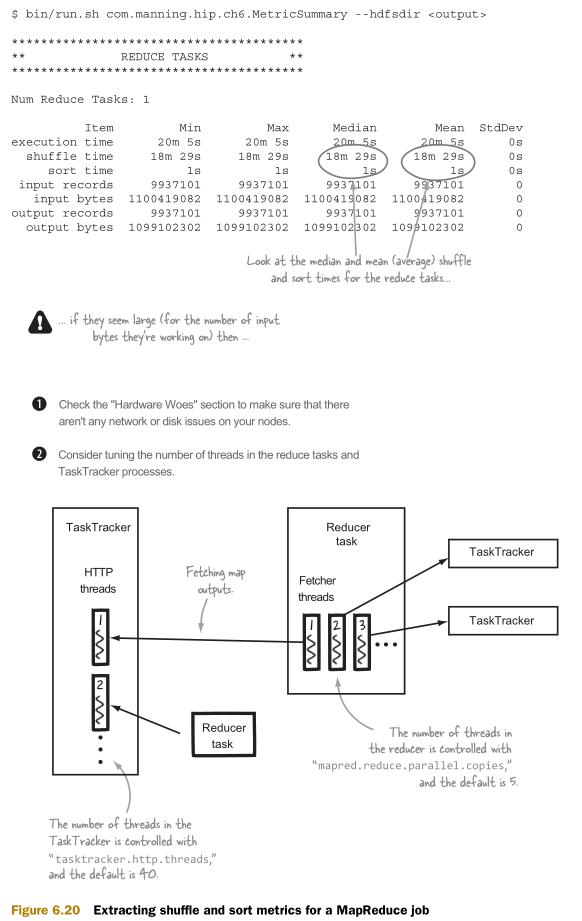
小结
如果要减小洗牌和排序阶段的时间,最简单的方法就是使用combine实例,并压缩map的输出。这些方法都可以极大地减少map和reduce任务之间的数据量,减轻网络,CPU和磁盘在洗牌和排序阶段的压力。
另外还可以调节排序阶段缓存大小,reduce端或map端的实例数量等。这些将在6.4.2中介绍。

【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步