


[大牛翻译系列]Hadoop(7)MapReduce:抽样(Sampling)
4.3 抽样(Sampling)
用基于MapReduce的程序来处理TB级的数据集,要花费的时间可能是数以小时计。仅仅是优化代码是很难达到良好的效果。
在开发和调试代码的时候,没有必要处理整个数据集。但如果在这种情况下要保证数据集能够被正确地处理,就需要用到抽样了。抽样是统计学中的一个方法。它通过一定的过程从整个数据中抽取出一个子数据集。这个子数据集能够代表整体数据集的数据分布状况。在MapReduce中,开发人员可以只针对这个子数据集进行开发调试,极大减小了系统负担,提高了开发效率。
技术23 水塘抽样(Reservoir sampling)
假设如下场景:在开发一个MapReduce作业的时候,需要反复不断地去测试一个超大数据集。当然,处理这个数据集很费时间,想要快速开发几乎不可能。
问题
在开发MapReduce作业的时候,如何能够只用处理超大数据集的一个小小的子集?
方案
在读取数据的那部分,自定义一个InputFormat来封装默认的InputFormat。在自定义的InputFormat中,将从默认的InputFormat中得到的数据按一定比例进行抽样。
讨论
由于水塘抽样可以从数据流中随机采样,它就特别适合于MapReduce。在MapReduce中,数据源的形式就是数据流。图4.16说明了水塘抽样的算法。

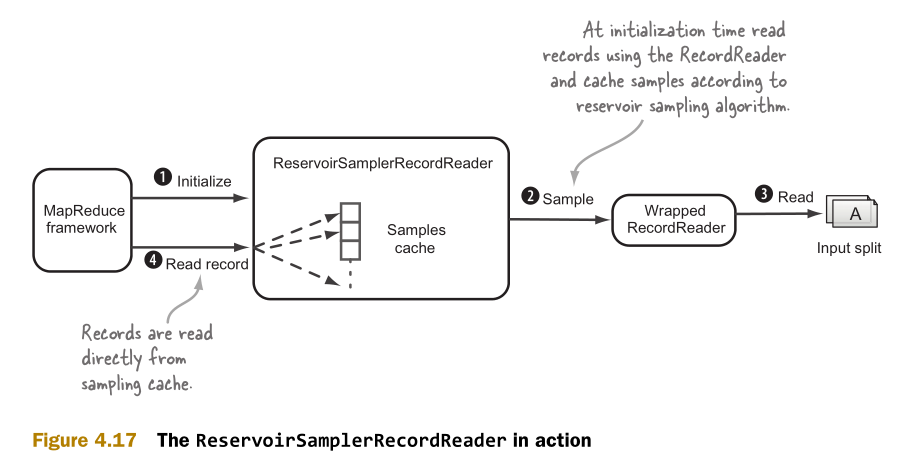
这里需要实现ReservoirSamplerRecordReader类来封装默认的InputFormat类和RecordReader类。InputFormat类的作用是对输入进行分块。RecordReader类的作用是读取记录。抽样功能则在ReservoirSamplerRecordReader类中实现。图4.17说明了ReservoirSamplerRecordReader类的工作机制。
以下是ReservoirSamplerRecordReader类的实现代码:
1 public static class ReservoirSamplerRecordReader<K extends Writable, V extends Writable> extends RecordReader { 2 3 private final RecordReader<K, V> rr; 4 private final int numSamples; 5 private final int maxRecords; 6 private final ArrayList<K> keys; 7 private final ArrayList<V> values; 8 9 @Override 10 public void initialize(InputSplit split,TaskAttemptContext context) 11 throws IOException, InterruptedException { 12 13 rr.initialize(split, context); 14 Random rand = new Random(); 15 16 for (int i = 0; i < maxRecords; i++) { 17 if (!rr.nextKeyValue()) { 18 break; 19 } 20 21 K key = rr.getCurrentKey(); 22 V val = rr.getCurrentValue(); 23 24 if (keys.size() < numSamples) { 25 keys.add(WritableUtils.clone(key, conf)); 26 values.add(WritableUtils.clone(val, conf)); 27 } else { 28 int r = rand.nextInt(i); 29 if (r < numSamples) { 30 keys.set(r, WritableUtils.clone(key, conf)); 31 values.set(r, WritableUtils.clone(val, conf)); 32 } 33 } 34 } 35 } 36 ...
在使用ReservoirSamplerInputFormat类的时候,需要设置的参数包括InputFormat等。以下是设置代码:
1 ReservoirSamplerInputFormat.setInputFormat(job,TextInputFormat.class); 2 ReservoirSamplerInputFormat.setNumSamples(job, 10); 3 ReservoirSamplerInputFormat.setMaxRecordsToRead(job, 10000); 4 ReservoirSamplerInputFormat.setUseSamplesNumberPerInputSplit(job, true);
然后在batch中执行作业,输入文件是name.txt,有88799行。经过抽样后的文件只有10行了。以下是作业执行的过程:
$ wc -l test-data/names.txt 88799 test-data/names.txt $ hadoop fs -put test-data/names.txt names.txt $ bin/run.sh com.manning.hip.ch4.sampler.SamplerJob \ names.txt output $ hadoop fs -cat output/part* | wc -l 10
前面设置的ReservoirSamplerInputFormat类的参数是抽样10行,最后的结果就是10行。
小结
抽样可以把数据集的尺寸变小,这对开发是很有帮助的。如果有时需要抽样,有时不需要抽样,怎么才能把抽样功能很好地整合到代码库中呢?这里有个方法,在作业的configure中加入一个开关,如下面的代码所示:
1 if(appConfig.isSampling()) { 2 ReservoirSamplerInputFormat.setInputFormat(job, 3 TextInputFormat.class); 4 ... 5 } else { 6 job.setInputFormatClass(TextInputFormat.class); 7 }
这样就可以把抽样和其他各种代码整合了。
