
生产环境中使用Cassandra(v0.6.1) 经验小结
最近NoSQL 很火爆,就拿 Facebook 的开源项目 Cassandra 来说,园子里面也有不少同学在研究,网上的一些介绍性文章也基本上大同小异,不少人大概也只是在虚拟机上玩玩,真正跑在生产环境下的也许并不多。我所在的公司(莫大 Meta.cn)最近由于产品需求,需要找一个大容量,高可用,扩展性好的海量存储方案,我很快想到了 Cassandra,做过架构的同学应该比较清楚,是否采用一个组件关键不是取决于它能多完美地解决问题,而是它有没有不可忍受的缺点。所以在选择数据存储方案的时候一定要对它的特性有充分的认识,我们在使用 Cassandr 的过程中一开始就是因为对它的一些限制条件了解不足走了一些弯路,写在这里与大家分享。
One to many 关系的保存
在关系型数据库中很容易解决的问题到了去关系的数据中变得有一点棘手,一开始我们想到了使用 Cassnadra 的 Column 或者 SupperColumn 来进行存储,官方网站上也说列很适合存储这种 PerUser 的 Index, 并且列在数量上也没有硬性限制,列名也是天然排序的,看起来是我们想要的东西了,但是读一下关于它的 Limitation 的 wiki 仿佛还是有一些问题的,大家注意第二条,在执行压缩操作的时候整个 row 都会被读入内存,也就是说如果一个 key 下面的数据量过大的话这将消耗大量的内存,到目前( V0.6.1 )为止这个问题还没有被修复,估计得等到0.7版了。
目前这种情况的解决方案我们使用序列化之后的value来存储,因为虽然 clomn 上有一定的限制但是 column 对应的value 体积可以比较大,再加上分散至多个key 上去存储也就够用了,性能上也有保证。
SupperColumn的问题
因为 Cassandra 在存储 SupperColumn 下面的 Column 的时候已经是使用序列化的方式了,即是说哪怕只需要读取 其中的一个 Column 整个 SupperColumn 都会被反序列化,这个问题目前也还没有一个方案,在我们的应用场景中大量使用到 SupperColumn 里面的列,多的可达数万之巨,结果可想而知,系统运行速度随着 Column 数的增加性能急剧下降,存取一个 Column 要花费近 3 秒钟时间,还出现 OOM(Out of Memory)错误。因此 SupperColumn 下面的 Column 只适合用于存储一组数量很有限的列,比如最近的100个条目等,如果太多性能上会受到影响。
Token
在 Cassandra 中,token表示一个节点负责的hash key 的范围,节点的失效递换也需要用到这个 token,因此集群建立之后应该另外保存一份 token 的列表,以备不时之需,我们的集群有一次因为误操作导致一个节点丢失,启动时报 string 索引越界错误,无法正常启动,其它的节点也不能使用nodetool 看到此节点因此无法作失效节点替换,只能导出数据重建集群,给我们带来不少麻烦。
增加节点
关于 Seed 设置的解释,Seed里面不需要存储一个集群的所有节点,只需指定一个在节点加入时已经正常运行的节点即可(尤其是不能将自已的ip写进去),一个新节在首次加入时应将 Bootstrap 设置为 true,成功加入集群后需要再设置为 false。
DataFileDirectories 的设定
这里面可以设定多个数据存储位置,但是各个位置数据分布不一定均匀,默认情况下一个位置的存储容量达到90%时将不会再向此位置写入数据。这里有个问题就是如果有多个硬盘的话其中一个损坏是不能够单独修复的,只能重建此节点,这个有点不爽。老外用来跑这个的所谓的"兼价PC级服务器"基本上也是上了硬件 raid 的,内存也都很大,不少在16GB或者以上。
内存使用
Cassandra 启动时默认使用1GB的存储,相对来说是比较小的,我们使用4GB内存因此在 bin/cassandra.in.sh 中设定 -Xmx2G ,内存的话当然是多多益善,每个 CF 默认的 Memtable 会占用 64MB,如果CF比较多的话需要估算一下自己的内存容量,或者调整该值(<MemtableSizeInMB>64</MemtableSizeInMB>),但是也不要太大,如果太大的话每次回写的时间会比较长,基本只是要回写次数不要过于频繁即可,可以使用 nodetool 的 cfstats 查看Memtable switch count得到。
性能监控
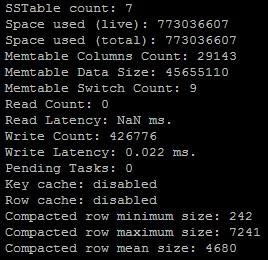
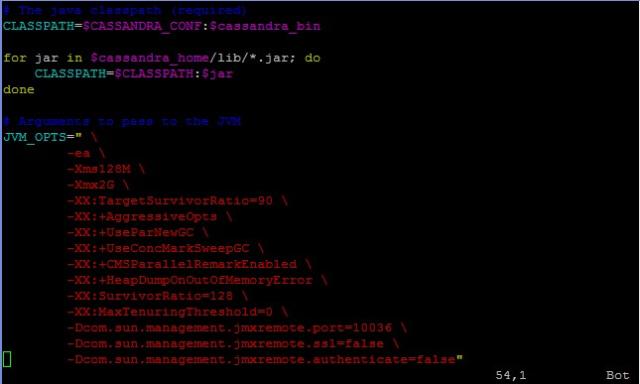
jmx的端口号最好修改一下,在 bin/cassandra.in.sh 中的jmxremote.port,比如改成10036。 我们最关心的还是读延迟,使用 nodetool 的 cfstats 可以看到 read latency 的值,如果明显高于其它的CF那就和注意了,write latency 因为 cassandr 直接写入内存和 commit log 因此这个值非常小,如果有问题的话可能要考虑硬件原因。
总的说来 Cassandra 还是一个很不错的分布式数据库,准确理解它的功能特性和条件限制充分利用它易维护,易扩展,高速写入的优点就能大大提高生产效率。
理解有偏差的地方欢迎大家拍砖。


