
三种数据模型---层次模型、网状模型以及关系模型
本文转载自:http://www.cnblogs.com/yue-blog/p/6010527.html
一、层次数据模型
定义:层次数据模型是用树状<层次>结构来组织数据的数据模型。
其实层次数据模型就是的图形表示就是一个倒立生长的树,由基本数据结构中的树(或者二叉树)的定义可知,每棵树都有且仅有一个根节点,其余的节点都是非根节点。每个节点表示一个记录类型对应与实体的概念,记录类型的各个字段对应实体的各个属性。各个记录类型及其字段都必须记录。
特征:树的性质决定了树状数据模型的特征
1. 整个模型中有且仅有一个节点没有父节点,其余的节点必须有且仅有一个父节点,但是所有的节点都可以不存在子节点;
2. 所有的子节点不能脱离父节点而单独存在,也就是说如果要删除父节点,那么父节点下面的所有子节点都要同时删除,但是可以单独删除一些叶子节点;
3. 每个记录类型有且仅有一条从父节点通向自身的路径;
实例:
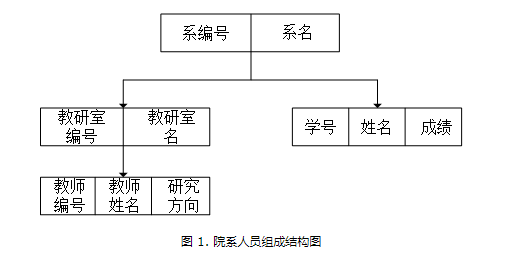
如图1,以学校某个系的组织结构为例,说明层次数据模型的结构。
1. 记录类型系是根节点,其属性为系编号和系名;
2. 记录类型教研室和学生分别构成了记录类型系的子节点,教研室的属性有教研室编号和教研室姓名,学生的属性分别是学号、姓名和成绩;
3. 记录类型教师是教研室这一实体的子节点,其属性由教师的编号,教师的姓名,教师的研究方向。
优点:
1. 层次数据模型的结构简单、清晰、明朗,很容易看到各个实体之间的联系;
2. 操作层次数据类型的数据库语句比较简单,只需要几条语句就可以完成数据库的操作;(百度百科)
3. 查询效率较高,在层次数据模型中,节点的有向边表示了节点之间的联系,在DBMS中如果有向边借助指针实现,那么依据路径很容易找到待查的记录;
4. 层次数据模型提供了较好的数据完整性支持,正如上所说,如果要删除父节点,那么其下的所有子节点都要同时删除;如图1,如果想要删除教研室,则其下的所有教师都要删除;
缺点:
1.结构呆板,缺乏灵活性。
2. 层次数据模型只能表示实体之间的1:n的关系,不能表示m:n的复杂关系,因此现实世界中的很多模型不能通过该模型方便的表示;
3.查询节点的时候必须知道其双亲节点的,因此限制了对数据库存取路径的控制。
二、网状数据模型
定义:用有向图表示实体和实体之间的联系的数据结构模型称为网状数据模型。
其实,网状数据模型可以看做是放松层次数据模型的约束性的一种扩展。网状数据模型中所有的节点允许脱离父节点而存在,也就是说说在整个模型中允许存在两个或多个没有根节点的节点,同时也允许一个节点存在一个或者多个的父节点,成为一种网状的有向图。因此节点之间的对应关系不再是1:n,而是一种m:n的关系,从而克服了层次状数据模型的缺点。
特征:
1. 可以存在两个或者多个节点没有父节点;
2. 允许单个节点存在多于一个父节点;
网状数据模型中的,每个节点表示一个实体,节点之间的有向线段表示实体之间的联系。网状数据模型中需要为每个联系指定对应的名称。
实例:
同样是以教务管理系统为例,下面说明了院系的组成中,教师、学生、课程之间的关系。

图 2. 院系的教务管理系统
由上图中可以看出课程(实体)的父节点由专业、教研室、学生。以课程和学生之间的关系来说,他们是一种m:n的关系,也就是说一个学生能够选修多门课程,一门课程也可以被多个学生同时选修。
优点:
1. 网状数据模型可以很方便的表示现实世界中的很多复杂的关系;
2. 修改网状数据模型时,没有层次状数据模型的那么多的严格限制,可以删除一个节点的父节点而依旧保留该节点;也允许插入一个没有任何父节点的节点,这样的插入在层次状数据模型中是不被允许的,除非是首先插入的是根节点;
3. 实体之间的关系在底层中可以借由指针指针实现,因此在这种数据库中的执行操作的效率较高;
缺点:
1. 网状数据模型的结构复杂,使用不易,随着应用环境的扩大,数据结构越来越复杂,数据的插入、删除牵动的相关数据太多,不利于数据库的维护和重建。
2. 网状数据模型数据之间的彼此关联比较大,该模型其实一种导航式的数据模型结构,不仅要说明要对数据做些什么,还说明操作的记录的路径;
三、关系型数据模型
关系型数据模型对应的数据库自然就是关系型数据库了,这是目前应用最多的数据库。
定义:使用表格表示实体和实体之间关系的数据模型称之为关系数据模型。
关系型数据库是目前最流行的数据库,同时也是被普遍使用的数据库,如MySQL就是一种流行的数据库。支持关系数据模型的数据库管理系统称为关系型数据库管理系统。
特征:
1. 关系数据模型中,无论是是实体、还是实体之间的联系都是被映射成统一的关系---一张二维表,在关系模型中,操作的对象和结果都是一张二维表;
2. 关系型数据库可用于表示实体之间的多对多的关系,只是此时要借助第三个关系---表,来实现多对多的关系,如下例子中的学生选课系统中学生和课程之间表现出一种多对多的关系,那么需要借助第三个表,也就是选课表将二者联系起来;
3. 关系必须是规范化的关系,即每个属性是不可分割的实体,不允许表中表的存在;
实例:
下面以学生选课系统为例进行说明。学生选课系统的实体包括:学生、教师、课程;其联系一般为学生与课程之间是一种多对多的关系,教师与课程之间是多对多的关系。学生可以同时选择多门课程,一门课程也可以同时被多个学生同时选择;一位教师可以教授多门课程,一门可能可以由多个教师教授。因此他们之间的联系如下:
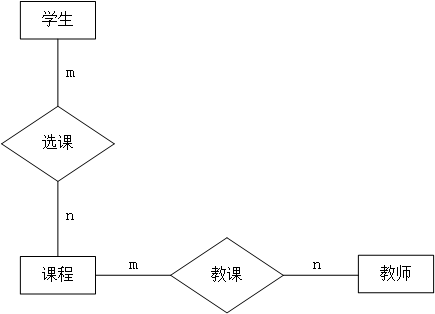
图 3 学生选课系统示意图
将该图映射为关系数据模型中的表格为图4。从中可以看到学生与课程之间的联系以及教师和课程之间的多对多联系都被映射成了表格。其中选课表中的sut_id和cour_id分别是引用学生表和课程表的cour_id的外键;教课表也是如此。
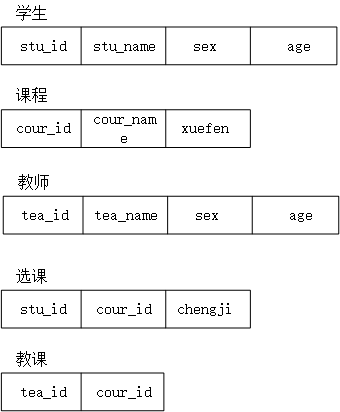
图 4 关系数据模型的表格
优点:
1. 结构简单,关系数据模型是一些表格的框架,实体的属性是表格中列的条目,实体之间的关系也是通过表格的公共属性表示,结构简单明了;
2. 关系数据模型中的存取路径对用户而言是完全隐蔽的,是程序和数据具有高度的独立性,其数据语言的非过程化程度较高;
3. 操作方便,在关系数据模型中操作的基本对象是集合而不是某一个元祖;
4. 有坚实的数学理论做基础,包括逻辑计算、数学计算等;
缺点:
1. 查询效率低,关系数据模型提供了较高的数据独立性和非过程化的查询功能(查询的时候只需指明数据存在的表和需要的数据所在的列,不用指明具体的查找路径),因此加大了系统的负担;
2. 由于查询效率较低,因此需要数据库管理系统对查询进行优化,加大了DBMS的负担;
关系数据模型的三种约束完整性:
关系数据模型定义了三种约束完整性:实体完整性、参照完整性以及用户定义完整性。
实体完整性:实体完整性是指实体的主属性不能取空值。实体完整性规则规定实体的所有主属性都不能为空。实体完整性针对基本关系而言的,一个基本关系对应着现实世界中的一个主题,例如上例中的学生表对应着学生这个实体。现实世界中的实体是可以区分的,他们具有某种唯一性标志,这种标志在关系模型中称之为主码,主码的属性也就是主属性不能为空。
参照完整性:在关系数据库中主要是值得外键参照的完整性。若A关系中的某个或者某些属性参照B或其他几个关系中的属性,那么在关系A中该属性要么为空,要么必须出现B或者其他的关系的对应属性中。如上表中的选课关系的stu_id和cour_id分别是参考学生和课程的外键,那么对于现实的系统而言,stu_id和cour_id必须分别出现在学生和课程关系中,这就是外键参考的完整性,同时删除的时候根据设置的不同有不同的处理方式。
用户定义完整性:用户定义完整性是针对某一个具体关系的约束条件。它反映的某一个具体应用所对应的数据必须满足一定的约束条件。例如,某些属性必须取唯一值,某些值的范围为0-100等。

