
软件工程基础之个人项目
一、项目地址
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| ·Estimate | ·估计这个任务需要多长时间 | 10 | 10 |
| Development | 开发 | ||
| ·Analysis | ·需求分析(包括学习新技术) | 100 | 120 |
| ·Design Spec | ·生成设计文档 | 30 | 20 |
| ·Design Review | ·设计复审(和同事审核设计文档) | / | / |
| ·Coding Standard | ·代码规范(为目前的开发制定合适的规范) | 10 | 10 |
| ·Design | ·具体设计 | 100 | 120 |
| ·Coding | ·具体编码 | 1100 | 1200 |
| ·Code Review | ·代码复审 | 30 | 20 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 400 | 600 |
| Reporting | 报告 | ||
| ·Test Report | ·测试报告 | 60 | 110 |
| ·Size Measurement | ·计算工作量 | 20 | 20 |
| ·Postmortem & Process Improvement Plan | ·事后总结,并提出过程改进计划 | 100 | 120 |
| 合计 | 1960 | 2350 |
三、解题思路描述
对于生成数独,开始的想法是由第一行随机排序,再从第二行开始进行回溯。由于生成的数独对左上角元素有要求,因此第一行随机排序的数从第一行第二个数字开始。
"在生成数独矩阵时,左上角的第一个数为:(学号后两位相加)% 9 + 1。例如学生A学号后2位是80,则该数字为(8+0)% 9 + 1 = 9"
因此,我的左上角第一个元素为7。
后来意识到由于第一行除去第一个固定的数值后只有8个数字进行随机排序,因而最多只能生成8!=40320个第一行数据,用固定的回溯算法只能得到40320个数独终局,与要求1000000数据量相差很大,故靠简单的对第一行随机排序回溯的方法不可取。
在网上查阅资料后得知,对于一个合法的数独终局,对数独终局的两个数进行交换,得到的数独仍然是合法的。
由于8!≈40000,选择采用对已有的数独进行变换的方式,需要25个数独终局,生成不重复的能满足数量要求的数独终局。
解数独
解数独的策略最容易想到的方法是暴力回溯,通过对空格不断地尝试填入数字直到试出合法的数独终局。但暴力回溯的时间复杂度和空间复杂度都很高,并不是合理的做法,查阅资料后,在这里找到了快速解决数独的算法,通过位运算实现了数独的快速求解算法。
四、设计实现过程
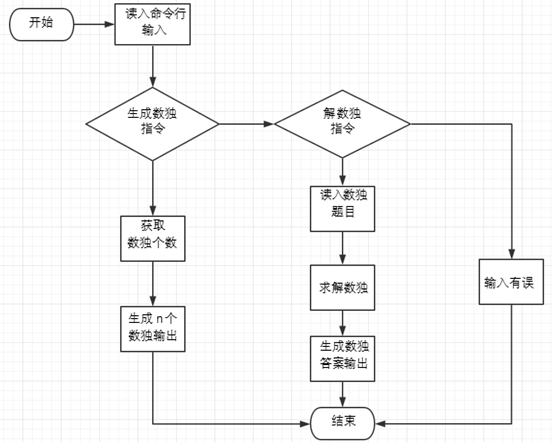
程序实现的流程图如图所示:
各个函数模块的关系如下:
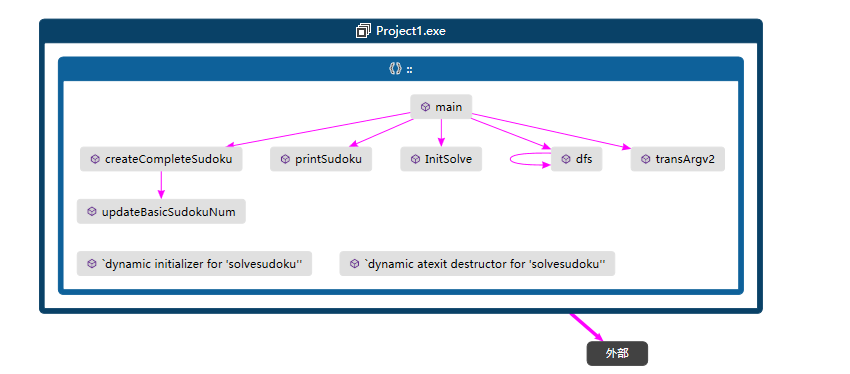
各个模块的主要功能包括:
1、程序初始化
初始化操作包括:
1)基础数独库 basicSudoku[30][10][10],存放基础完整数独
2)基础数独映射序列 basicSudokuNum[30][8],初始化为123456789
3)存放1~1023的二进制数中1的个数 num[1 << 10],提前通过 __builtin_popcount()函数计算得,并打表
2、当命令行输入生成数独的命令,"-c 数字",获取数字NUM,并进行NUM次循环,每次循环执行以下内容。
1)updateBasicSudokuNum()
调用stl库中的next_permutation(start,end),生成下一个全排列
2)createCompleteSudoku()
对基础数独中的数字进行替换,得到新的数独终局,将数独压入vector <int>solvesudoku中储存。
3、当命令行输入求解数独的命令,"-s 文件路径",按照输入的文件路径读取文件内容到二维数组sudoku后,进行以下操作。
1)InitSolve()
对求解数独算法的辅助数组进行预处理
2)dfs(int dep)
对数独进行求解,dep表示当前输入0的个数,dep=0时,表示求解结束,并将求解得到的结果压入vector <int>solvesudoku中储存(如果数独无解,则不压入)
4.如果生成数独的输入请求不合法,比如-1,abc,10000000等,或者求解数独的文件输入不合法,则在控制台输出error,并将validInput赋值为false。
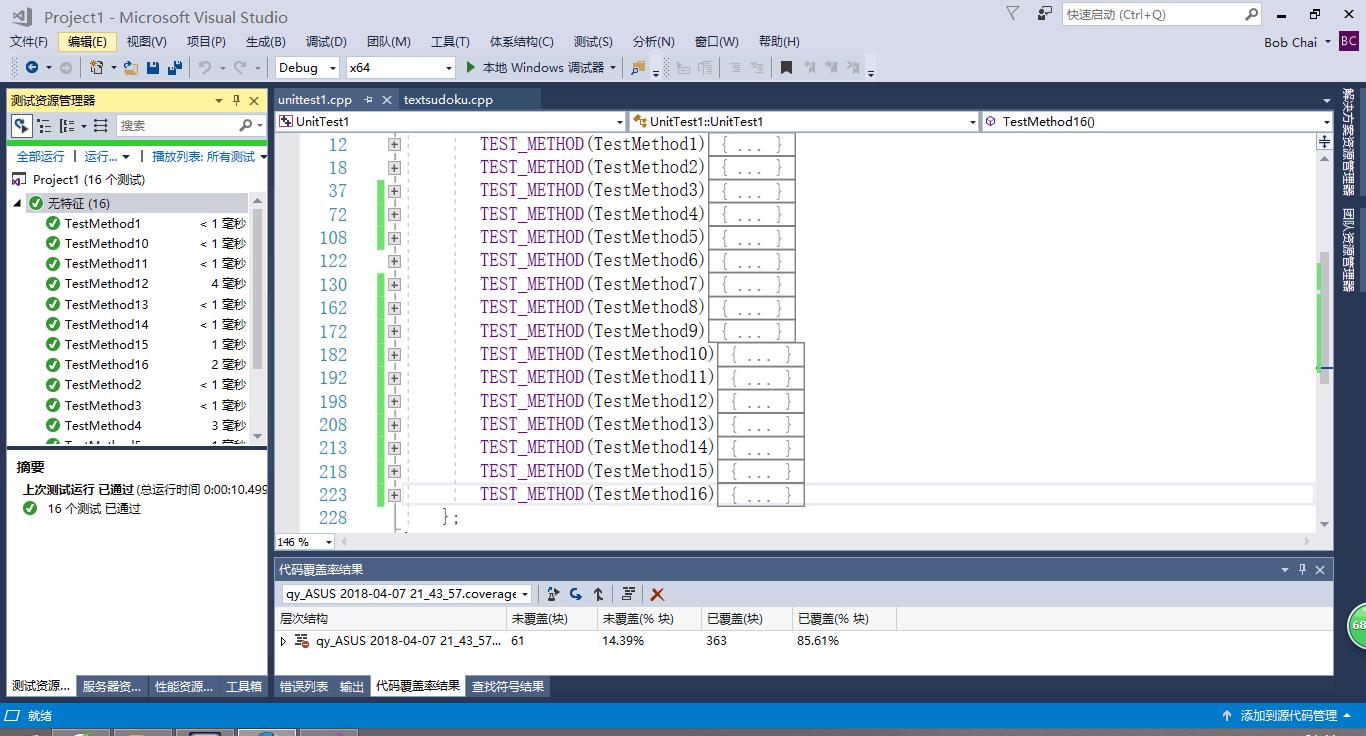
5、单元测试
单元测试针对各个函数模块进行,由于main函数以及dfs中进行单元测试比较困难,因此对main函数以及dfs进行了调整,并进行了15项测试,对大部分模块进行了覆盖,最终代码覆盖率达到了85.61%。
主要的测试有:
1)测试updateBasicSudokuNum(num)函数生成的全排列是否正确。
2)测试createCompleteSudoku(num)函数生成的数独是否正确。
3)测试dfs(int dep)函数求解数独是否正确。
4)测试对命令行参数的捕捉是否正确。
最终的单元测试如下图:
五、性能分析
未进行优化的输出:
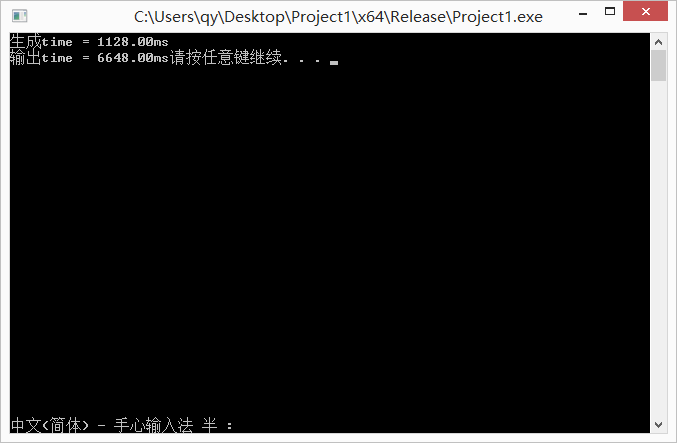
对于1000000的数据量,CPU的使用主要集中在前期生成数独终局的阶段,后期将生成结果输出到文本对CPU的使用率较低。
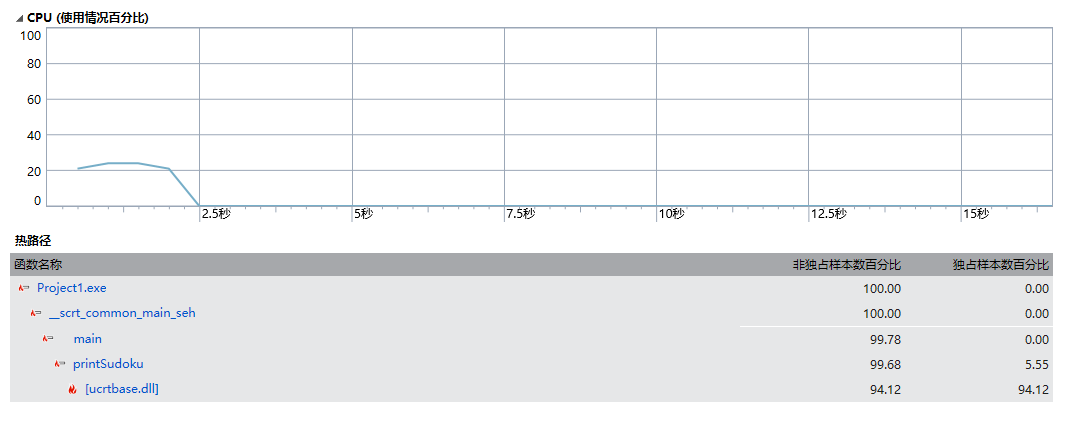

从分析结果看,输出是整个程序的瓶颈,对输出的优化将提升程序的整体性能。因此我将主要的优化重心集中在优化上,在查阅了相关资料后,对存储输出结果的vector<int >solvesudoku进行改变,决定采用string solvesudoku对数独终局以及解题进行临时储存,并利用fout将整个string直接输出。
最终经过优化后,生成1000000的数独终局的时间如下:
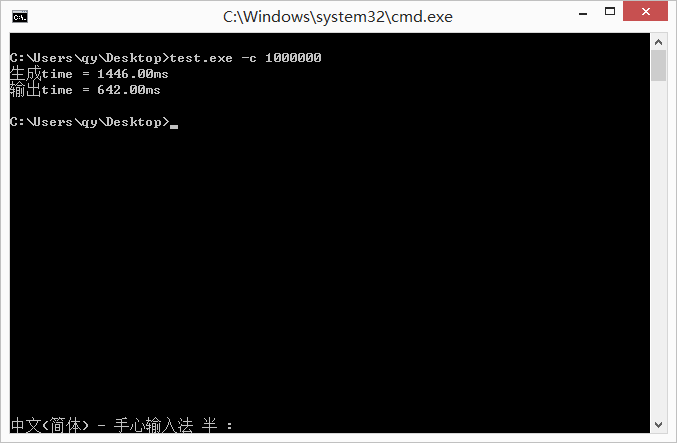
六、代码说明
下面给出经过输出优化后的关键函数的代码。
生成数独终局代码如下:
每次根据映射关系替换各个元素,得到不同的终局。
1 /*按照得到的序列进行一一映射, 2 替换掉基础数独中的数字,得到一个全新的数独, 3 用solvesudoku来存储*/ 4 void createCompleteSudoku(int num) 5 { 6 updateBasicSudokuNum(num); 7 8 int key = basicSudoku[num][0][0]; //key赋值为基础数独的第一个数字 9 int arr[10]; 10 arr[key] = 7; //左上角为 7 11 int counter = 0; 12 13 for (int i = 1; i <= 9; i++) { 14 if (i != key) { 15 arr[i] = basicSudokuNum[num][counter++]; 16 } 17 } 18 19 for (int i = 0; i < 9; i++) { 20 for (int j = 0; j < 8; j++) { 21 solvesudoku+=(arr[basicSudoku[num][i][j]]+'0'); 22 solvesudoku+=' '; 23 } 24 solvesudoku+=(arr[basicSudoku[num][i][8]]+'0'); 25 solvesudoku+='\n'; 26 } 27 solvesudoku+='\n'; 28 }
利用位运算求解数独如下:
由于输入的数独可能存在无解的情况,于是在之后增加了一个计时的语句,对于每次求解超过1000ms的数独认定为无解,并跳出dfs。
这样,对于无解的数独,不会输出结果。
1 clock_t start_solve, end_solve; //解数独计时 2 /*解数独*/ 3 void dfs(int dep) 4 { 5 end_solve = clock(); 6 if (end_solve - start_solve>1000) 7 return; 8 if (!dep) 9 { 10 for (int i = 1; i <= 9; i++) { 11 for (int j = 1; j <= 8; j++) { 12 solvesudoku += (sudoku[i][j] + '0'); 13 solvesudoku += ' '; 14 } 15 solvesudoku += (sudoku[i][9] + '0'); 16 solvesudoku += '\n'; 17 } 18 solvesudoku += '\n'; 19 20 longjmp(buf, 1); //跳出死循环 21 } 22 int b[10][10], c[10][10], x = 0, y = 0, z = 9; 23 for (int i = 1; i <= 9; i++) 24 { 25 for (int j = 1; j <= 9; j++) 26 { 27 if (!sudoku[i][j] && !id[i][j]) 28 return; 29 b[i][j] = sudoku[i][j]; 30 c[i][j] = id[i][j]; 31 if (!sudoku[i][j]) 32 { 33 if (num[id[i][j]]<z) 34 z = num[id[i][j]], x = i, y = j; 35 } 36 } 37 } 38 for (int i = 0; i<9; i++) 39 if (id[x][y] & (1 << i)) 40 { 41 sudoku[x][y] = i + 1; 42 for (int k = 1; k <= 9; k++) 43 id[k][y] &= ((1 << 9) - 1 - (1 << i)); 44 for (int k = 1; k <= 9; k++) 45 id[x][k] &= ((1 << 9) - 1 - (1 << i)); 46 for (int k = (x - 1) / 3 * 3 + 1; k <= (x - 1) / 3 * 3 + 3; k++) 47 { 48 for (int l = (y - 1) / 3 * 3 + 1; l <= (y - 1) / 3 * 3 + 3; l++) 49 { 50 id[k][l] &= ((1 << 9) - 1 - (1 << i)); 51 } 52 } 53 dfs(dep - 1); 54 for (int i = 1; i <= 9; i++) 55 { 56 for (int j = 1; j <= 9; j++) 57 { 58 id[i][j] = c[i][j], sudoku[i][j] = b[i][j]; 59 } 60 } 61 } 62 return; 63 }
优化后的输出函数如下:
将终局/答案保存在string solvesudoku中,利用fout一次性输出,避免了循环,提升性能。
1 /*打印数独到文件*/ 2 void printSudoku() 3 { 4 ofstream fout("sudoku.txt"); 5 solvesudoku.erase(solvesudoku.length()-2); 6 fout<<solvesudoku; 7 fout.close(); 8 }
七、小结
几周的时间完成一个项目,难度比想象中大很多,个人项目难度的本身不是实现数独终局以及求解数独,而是在最后的单元测试以及性能优化上。几周的时间完成了代码编写,代码评审,代码优化等工作,作为第一个项目,个人项目的完成很大程度上提升了各个方面的能力,为今后的学习工作打下基础。
