C# 词法分析器(二)输入缓冲和代码定位 update 2022.09.09
系列导航
一、输入缓冲
在介绍如何进行词法分析之前,先来说说一个不怎么被提及的问题——怎么从源文件中读取字符流。为什么这个问题这么重要呢?是因为在词法分析中,对字符流是有要求的,它必须能够支持回退操作(就是将多个字符放回到流中,以后会再次被读取)。
先来解释下为什么需要支持回退操作,举个简单的例子来说,现在要对两个模式进行匹配:

图 1 流的回退过程
上面是一个简单的匹配过程,仅为了展示回退过程,在后面实现 DFA 模拟器时会详细解释是如何匹配词素的。
现在来看看 C# 中与输入相关的类,有 Stream,它支持流的查找,但是只能以字节方式访问;BinaryReader 和 TextReader 虽然支持读取字符,但是又不能支持回退。所以,就必须自己完成这个输入缓冲类了,大致思路就是以 TextReader 作为底层的字符输入,然后由自己的类完成对回退能力的支持。
《编译原理》上给出了一种缓冲区对的方法,简单的说就是开辟两个缓冲区,设缓冲区大小都是 N 个字符。每一次都将 N 个字符读入到缓冲区中,并在这个缓冲区上实现字符操作。如果当前缓冲区的数据已经处理完毕,就将 N 个新字符读入到另一个缓冲区中,接下来就换做操作新的缓冲区。
这样的数据结构效率很高,而且只要维护合适的指针,就可以很容易的实现回退功能。不过它的缓冲区大小是固定的,新读入的字符会覆盖旧的字符。如果需要回退的字符数量过多(比如在分析很长的字符串时),就容易出现错误。我通过使用多个缓冲区解决了旧字符被覆盖的问题——如果缓冲区不足了,就开辟新缓冲区,而不是覆盖旧数据。
如果仅仅是不断的添加缓冲区,那么占用的内存只会不断增加,这样是没有什么意义的,因此我定义了三个释放缓冲区的操作:Drop,Accept 和 AcceptToken。Drop 的作用是将当前位置之前的所有数据标记为无效(被抛弃),被标记无效的数据占用的缓冲区就被释放掉,可以拿来被重复利用了;Accept 则会将标记为无效的数据以字符串形式返回,而不仅仅是简单的抛弃;类似的,AcceptToken 是以 Token 形式返回被无效化的数据,是为了方便进行词法分析。
这样的数据结构比较类似于 STL 中的 deque,不过这里不需要随机访问和插入、删除数据,仅会在数据的头、尾进行操作,因此我直接将多个缓冲区使用双向链表连成一个环,使用三个指针 current,first 和 last 指向链表中有数据的缓冲区,如下图所示:

图 2 多个缓冲区组成的链表,红色的部分表示有数据,白色的部分没有数据
其中,first 指向的是最早的数据缓冲区,last 指向的是最新的数据缓冲区,current 指向的是当前正在访问的数据缓冲区,current 总是在 [first, last] 范围之内。firstIndex 和 lastLen 之间红色的部分,就是包含有效数据的缓冲区,idx 表示当前正在访问的字符。白色的部分表示空缓冲区,或是缓冲区中的数据已无效。
当需要读取下一个字符时,就从 current 中依次读取数据,并将 idx 后移。如果 current 中的数据已经读取完毕,则将 current 移向 last(这里用移向,是因为 current 和 last 之间可能有多个缓冲区),同时 idx 也要相应的移动。
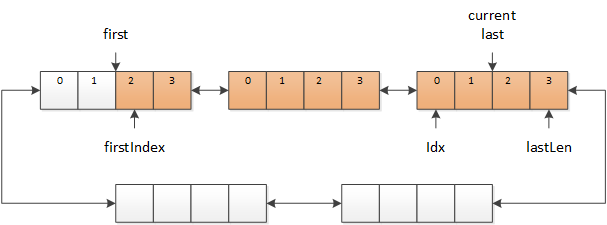
图 3 current 移向 last
如果需要继续读取字符,但是 current 中没有新数据了,而此时 current 已经与 last 相同,表示缓冲区中已经没有更新的数据,那么就需要从 TextReader 中读取数据,放到新的缓冲区中,同时后移 current 和 last(需要保证 last 总是指向最新的缓冲区)。
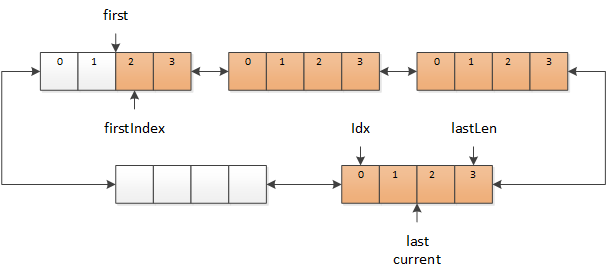
图 4 current 和 last 向后移
现在来看看回退操作。进行回退时,只需要将 current 向 first 的方向移动(同样,current 和 first 之间可能有多个缓冲区)。
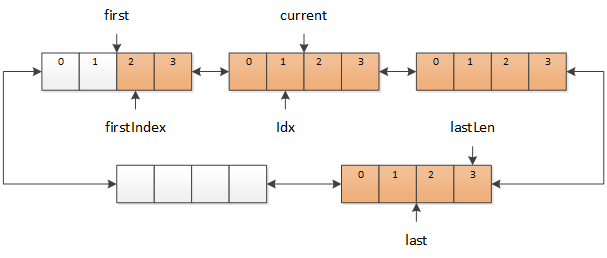
图 5 回退操作
Drop 操作(Accept 和 AcceptToken 也同理)的实现也很简单,只需要将 first 移动到 current 位置,将 firstIndex 移动到 idx 即可,这就表示 idx 之前的数据都看作无效数据。
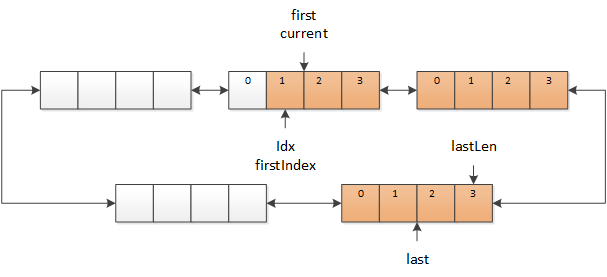
图 6 Drop 操作
这里需要注意的就是,Drop 操作完成后,被无效化的数据就有可能会被新数据覆盖,因此应该确定数据不再需要时再执行 Drop 操作。Drop 操作的效率很高(移动两个引用),基本不用担心会影响效率。
使用这种环形数据结构的优点是除了将字符填充到缓冲区之外,完全避免了数据的额外复制,无论是前进、回退还是 Drop 操作都只有指针(引用)操作,效率很高。当 Drop 比较及时时,仅会使用两个缓冲区,不会额外的占用内存。当占用的缓冲区过多时,还能够实现主动释放多余的内存(这里现在没有考虑)。
缺点就是实现起来会复杂些,需要仔细处理好 first、current 和 last 的关系,以及 firstIndex、index 和 lastLen 范围限制,有时还会涉及到多个缓冲区的操作。
完整的代码可见 SourceReader.cs。
二、代码定位
在对源代码进行解析的时候,记录每个 Token 对应的行号和列号显然是很必要的工作,没有人会喜欢面对一大堆 Error,而且还偏偏不告诉你到底是哪错了……因此,我认为代码定位绝对是词法分析必备的功能,所以直接把这个功能内置到了 SourceReader 类中了。
下面来说明如何实现代码定位。代码定位包含三维数据:索引、行号和列号。索引是从 0 开始的字符索引,主要是方便程序进行处理;行号和列号则都是从 1 开始的,主要是为了人去看。
行定位比较简单,Unix 的换行符是 '\n',Windows 的换行符是 "\r\n",所以直接统计 '\n' 的个数即可。
接下来是列定位。为了达到比较好的效果,需要考虑两个因素:全角、半角字符和 Tab 字符。
一个中文字符(即全角字符)对应的是两列,英文字符(半角字符)对应的则是一列,这样在等宽字体下,每一列都是上下对齐的。在计算列数的时候,自然也应当如此,使用 Encoding.Default.GetByteCount() 而不是字符串的长度。不过这里我发现了一个内存问题(详情参考这里),改用 Encoding.Default.GetEncoder() 的 GetByteCount 方法就可以了。
一个 Tab 字符的长度是不定的(一般是为 4 或 8,因人而异),所以定义了一个 TabSize 来表示 Tab 字符的宽度。那么,一个 Tab 字符就对应 TabSize 列么?并不是这样的,虽然一般看来是这样,但事实上,Tab 字符是让下一字符对应的列总是为 TabSize 的整数倍再加 1。如果 TabSize = 4,那么它的行为如下图所示,其中 a 和 bcc 后面都是有两个 Tab 字符,bcccccc 和 bccccccc 后面都是有一个 Tab 字符,每个 Tab 字符我都用灰色箭头标出来了。
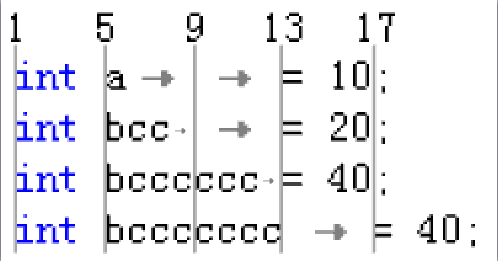
图 7 Tab 字符实例
所以,实际的列号应当使用下面的公式计算,其中 currentCol 是 Tab 字符所在的列,nextCol 就是下一字符所在的列:
1 | nextCol = tabSize * (1 + (currentCol - 1) / tabSize) + 1; |
代码定位的计算方法有了,然后就是计算的时机。如果每次 Read 的时候都计算当前字符的位置,一是计算效率会略低,因为 GetByteCount 方法中,一次性计算较长一个字符数组的效率,差不多是多次计算长度为 1 的字符数组的一倍。二是回退的时候应该怎么办?如果将之前的位置计算结果都保存起来,内存占用会是一个问题,如果不考虑的话,又无法根据当前字符的位置推算出前一个字符的位置(比如当前字符在第一列的话,前一个字符应该在第几列?)。
综合考虑之后,我决定将代码位置的计算放到 Drop 操作(Accept 和 AcceptToken 也一样)中,一个是向上面所说的,计算效率会略高,另一个是一般仅当识别出了一个 Token 后才需要为它定位,此时恰好是 Drop 或 AcceptToken 的时机,识别 Token 的过程中就是定位了也没有什么用处。
我将代码定位的功能单独封装到了 LineLocator.cs 类中。
下一篇将会介绍词法分析中用到的正则表达式,以及如何解析正则表达式。
相关代码都可以在这里找到。
作者:CYJB
出处:http://www.cnblogs.com/cyjb/
GitHub:https://github.com/CYJB/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步