C# 词法分析器(一)词法分析介绍 update 2022.09.09
系列导航
- (一)词法分析介绍
- (二)输入缓冲和代码定位
- (三)正则表达式
- (四)构造 NFA
- (五)转换 DFA
- (六)构造词法分析器
- (七)总结
虽然文章的标题是词法分析,但首先还是要从编译原理说开来。编译原理应该很多人都听说过,虽然不一定会有多么了解。
简单的说,编译原理就是研究如何进行编译——也就如何从代码(*.cs 文件)转换为计算机可以执行的程序(*.exe 文件)。当然也有些语言如 JavaScript 是解释执行的,它的代码是直接被执行的,不需要生成可执行程序。
编译过程是很复杂的,它涉及到很多步骤,直接拿《编译原理》(Compilers: Principles, Techniques and Tools,红龙书)上的图来看:
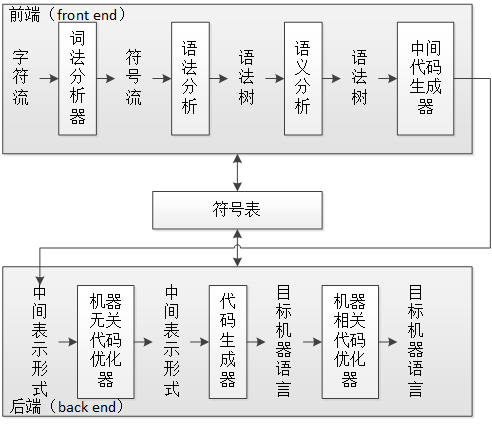
图 1 编译器的各个步骤,其实是我根据书上的图综合了一下后画的
这里给出了 7 个步骤(后面的优化步骤是可选的),其中前 4 个步骤是分析部分(也被称为前端 front end),是把源程序分解为多个组成要素,并在这些要素上加上语法结构,最后把信息存放在符号表(symbol table)中。后三个步骤是综合部分(也成为后端 back end),它们根据中间表示和符号表中的信息构造期待的目标程序。
将编译器分为这么多步骤,其好处就是使得每个步骤更加简单,从而使编译器更加容易设计,也可以利用很多现有的工具——例如词法分析器可以用 Lex 或 Flex 生成,语法分析器可以用 Yacc 或 Bison 生成,几乎不用做太多编码工作就能得到一颗语法树,前端的工作也就完成的差不多了。而至于后端,也有很多现有的技术可以使用,例如现成的虚拟机(CLR 或 Java,只要翻译成相应的 IL 就可以了)。
这个系列的文章,说的就是编译原理的第一步:语法分析。大部分算法和理论都来自《编译原理》,其余的部分则是自己搞出来的,或者是参考了 Flex 的实现(这里的 Flex 是指 fast lexical analyzer generator,一个著名的提供词法分析的程序,而不是 Adobe 的 Flex)。
我会尽量完整的介绍词法分析器的编写过程,包括一些细节的实现。当然,目前只能根据正则表达式定义得到一个可以用来进行词法分析的对象,要想达到 Flex 那样直接根据词法定义文件生成词法分析器源代码,还有很多工作要做,不是短期内能够搞定的。
本篇文章作为系列的第一篇,将会对词法分析做综合的概述,介绍一下其中用到的技术和大致的流程。
一、词法分析介绍
词法分析(lexical analysis)或扫描(scanning)是编译器的第一个步骤。词法分析器读入组成源程序的字符流,并且将它们组织成有意义的词素(lexeme)的序列,并对每个词素产生词法单元(token)作为输出。
简单的来说,词法分析就是将源程序(可以认为是一个很长的字符串)读进来,并且“切”成小段(每一段就是一个词法单元 token),每个单元都是有具体的意义的,例如表示某个特定的关键词,或者代表一个数字。而这个词法单元在源程序中对应的文本,就叫做“词素”。
以计算器来举例,12+34*9 这一段“源程序”的词法分析过程如下所示:
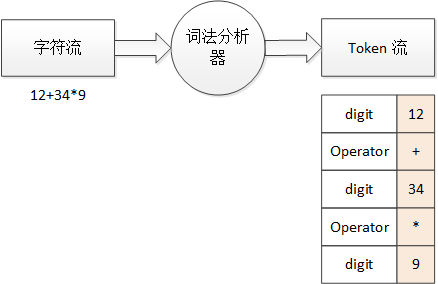
图 2 算式的词法分析过程
一段对计算机来说豪无意义的字符串,经过语法分析后就得到了略微有意义的 Token 流。digit 就表示这个词法单元对应的是数字,operator 则表示操作符,后面相应的数字和符号(粉色背景)就是词素。同时,程序中一些不必要的空白、注释也可以由词法分析器来过滤掉,这样,之后的语法分析等步骤处理起来就会容易得多。
在实际的程序中,词法单元都会以枚举或数字来表示这是哪一类词法单元。我的 Token<T> 类 定义如下所示:
namespace Cyjb.Text {
struct Token<T> {
// 词法单元的标识符,表示词法单元的类型。
T Kind { get; }
// 词法单元的文本,即“词素”。
string Text { get; }
// 获取词法单元的范围。
TextSpan Span { get; }
// 获取词法单元的行列位置范围。
LinePositionSpan LinePositionSpan { get; }
// 获取词法单元的值。
object? Value { get; }
}
}
里面的 Kind 和 Text 属性不必多做解释,Span 是用来在源文件中定位的索引,LinePositionSpan 则是相关行列号(需要在读取源码设置为计算行列号),Value 则仅仅是为了方便传递一些值而设。
2014.1.8 更新:这个 Token<T> 类,最开始的定义是一个 Token 结构,词法单元的标识符是使用一个 int 值表示的。但是,个人认为使用枚举类型要更好些,因为枚举类型是具有名称的,这样每个标识符可以很好的体现其语意;而且具有编译期检查,能够有效防止拼写错误。
二、如何描述词素
现在知道了词法分析可以将词素分割开来,那么词素是怎么描述的?或者说,为什么 12、+ 和 34 都是词素,而 1、 2+3 和 4 就不是词素呢?这就需要用到模式了。
模式(pattern)描述了一个词法单元的词素可能具有的形式。
也就是说,我定义了 digit 模式为“由一个或多个数字组成的序列”,和 operator 模式为“单个 + 或 * 字符”,词法分析器就知道 12 是一个词素,而 2+3 则不是词素了。
现在,模式一般都是用正则表达式(regular expression)表示的,这里所谓的正则表达式,与平常所说的正则表达式(例如 System.Text.RegularExpressions.Regex 类)形式完全相同,功能却更有限,它只包含了字符串的匹配能力,而没有分组、引用和替换的能力。简单的举个例子,a+ 这个正则表达式就表示“由一个或多个字符 a 组成的序列”。关于正则表达式更多详细信息,我会在后面的文章中列出来,当然,有限的参考一下 System.Text.RegularExpressions.Regex 也是可以的。
在本系列之后的文章中所提的正则表达式,都指的是这种只具有字符串匹配能力的正则表达式,大家一定要注意不要与 System.Text.RegularExpressions.Regex 相混淆。
三、如何构造词法分析器
说完了词素的描述,就到如何根据词素的描述来构造词法分析器了。大致的流程如下:
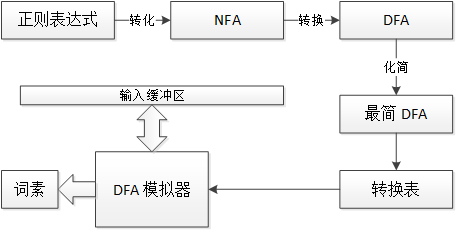
图 3 构造词法分析器
从上图来看,定义了模式的正则表达式,经过 NFA 转换、DFA 转换和 DFA 化简,得到了一张转换表。这张转换表再加上一个固定的 DFA 模拟器,就组成了词法分析器。它不断的从输入缓冲区中读取字符,利用自动机来识别词素并输出。可以说,词法分析的精华就是如何得到这张转换表。
说了这么多,词法分析算是简单的介绍完了,从下一篇开始,就是如何一步一步实现完整的词法分析器。相关代码都可以在这里找到。
作者:CYJB
出处:http://www.cnblogs.com/cyjb/
GitHub:https://github.com/CYJB/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。


